
Beyond core Agentic Design Patterns
Machine Learning and Artificial Intelligence



Have you ever chatted with one of those chatbots that can hold a surprisingly human-like conversation—or even help you plan a trip or write an email? Behind these chatbots are massive “foundation models” (like GPT or Llama) that power all sorts of AI “agents”. These agents don’t just answer questions; they can take on tasks, like a helpful assistant that organizes your to-do list or brainstorms new ideas for your project.

Core Agentic Design Patterns

Agentic Design Patterns are strategies for making AI systems—especially large language models (LLMs) like GPT—work in a smarter, step-by-step way instead of just giving one answer from start to finish.slys.dev is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
But as handy as they are, building these smart assistants can be tricky. Sometimes they make things up ( a.k.a. hallucinations), other times they can’t figure out exactly what you want, and they often can’t explain how they arrived at their answer. Enter Agentic Design Patterns—tried-and-true ways to structure and guide these AI agents so they work better, are easier to trust, and align more closely with what people really need.
Whether you’re a newcomer to AI or a seasoned developer, these design patterns can help you navigate the complexities of building autonomous AI systems. You’ll discover how to break big tasks into manageable steps, make sure the agent includes the right information at the right time, and get feedback—either from other AI models or from actual humans—to refine the agent’s work. By applying these patterns, we can create AI agents that are more reliable, more transparent, and ultimately more helpful for all kinds of real-world tasks.
What are agentic design patterns?
Think of a design pattern like a reliable “recipe” for solving a common problem in software. If you’ve ever followed a recipe for chocolate chip cookies, you know it sets out everything you need: the ingredients, the steps, the oven temperature—so you don’t have to figure it out from scratch each time. Agentic design patterns work similarly, but instead of telling you how to bake cookies, they guide you in how to build and organize AI agents powered by large language models.

Why do we need these patterns? Because creating an AI agent isn’t just about plugging GPT or another model into your code. You also have to think about:
How the agent decides what to do (especially if the user’s instructions are vague).
How to break down a big goal into smaller steps (so the agent can tackle them in order).
How to handle mistakes (like when the agent hallucinates or provides inaccurate information).
How to get feedback from humans or even other AI agents to improve the results.
By using tried-and-true solutions—i.e., patterns—to handle these questions, you don’t have to reinvent the wheel each time you develop a new AI agent. You can focus on the fun, creative part of building your application, while trusting that your structure and workflow follow a well-tested approach. Essentially, these patterns are like having a mentor whispering in your ear: “Here’s the easiest way to manage user instructions”, or “This is how you should store your AI agent’s memory”, so you can build something that’s both powerful and easy to maintain.
Core challenges in agentic AI
As amazing as these AI agents can be, they come with their fair share of puzzles and pitfalls. Here are some of the big ones that make life interesting (and sometimes frustrating) for both engineers and users.
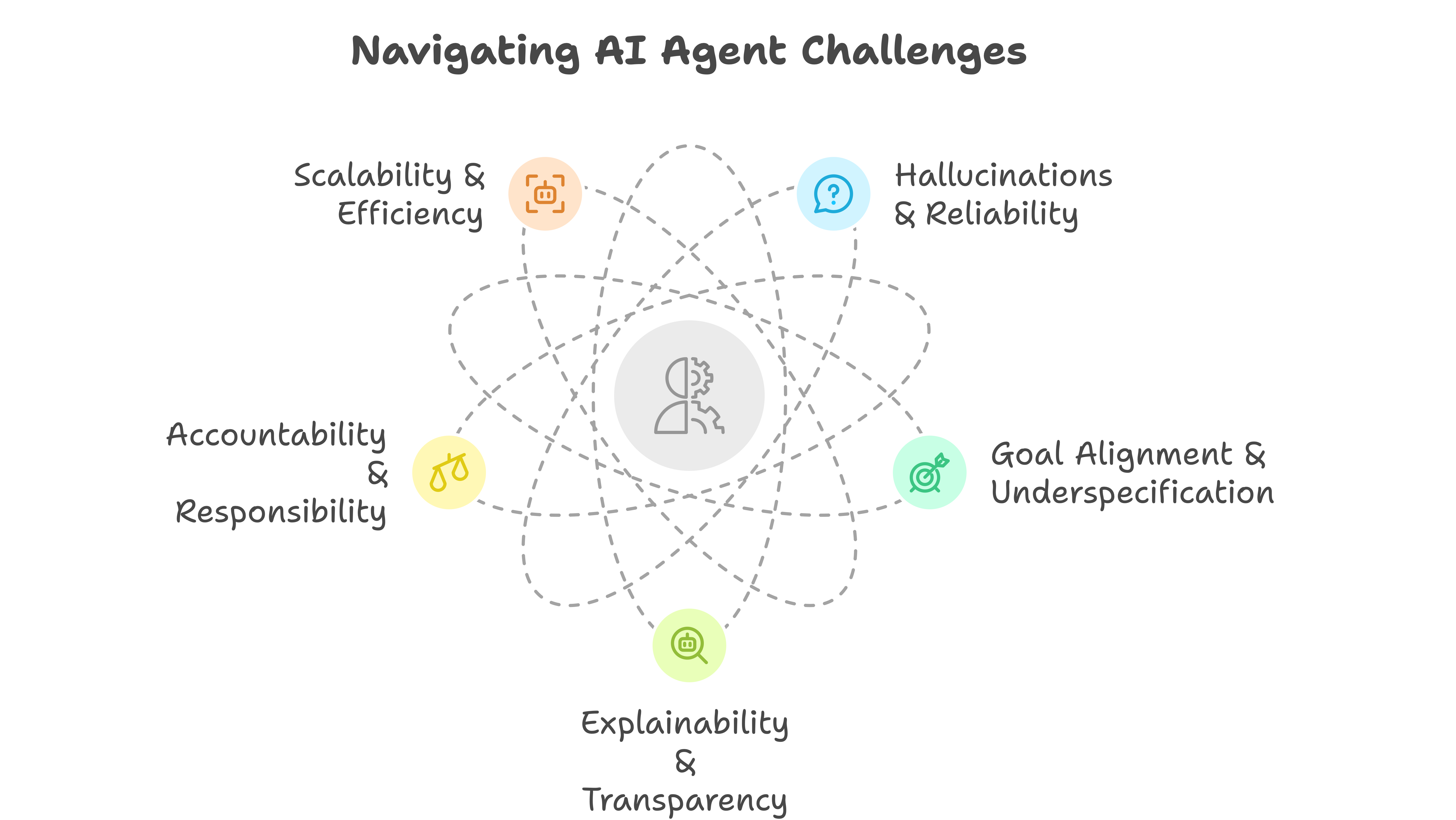
Hallucinations and reliability
Ever had a friend who’s really confident about their facts, but sometimes makes stuff up without realizing it? Large language models can do that too! We call it “hallucination”. An agent may invent fake references or misinterpret details—even if it sounds utterly convincing. Engineers need a way to detect and reduce these errors so the agent doesn’t lead you astray.
Goal alignment and underspecification
Agents are great at following instructions—if they understand exactly what you want. But what if your prompt is vague, or you’re not totally sure how to phrase your request? The agent might miss the mark. Part of designing a good agent is figuring out how to clarify user goals and fill in missing details to get the best outcome.
Explainability and transparency
AI agents can seem like black boxes that magically pop out answers. But when something goes wrong—say, they give weird advice—how do we figure out why it happened? And how can we show users the reasoning behind the agent’s recommendations? This is where explainability comes in: giving us insight into the agent’s “thought process” so we can trust its decisions.
Accountability and responsibility
Who’s in charge if the agent’s actions cause problems, especially when multiple AI services are working together? Ensuring there’s a clear record of which agent did what helps address liability, governance, or even legal issues. Think of it like tracking each ingredient in a recipe: if the cookies taste awful, we need to know which ingredient caused the trouble!
Scalability and efficiency
As you start layering different AI agents, data sources, and feedback loops, things can get complex fast. More agents can mean more power, but it also can mean more overhead in communication, resource usage, and potential errors. Balancing all of this so your AI system runs smoothly without draining the budget is a real design challenge.
Why it matters?
If we sidestep these issues, our agents might be charming but untrustworthy, or accurate but extremely slow. By understanding—and tackling—these core challenges head-on, we set ourselves up to build agents that are both useful and dependable. And that’s exactly what agentic design patterns aim to achieve: giving us the building blocks to address these challenges and create AI that just works.
A tour of key patterns
Below is a whirlwind tour of the major design patterns1 that help AI agents do their job more reliably and transparently. Think of them like specialized “tools in a toolkit”, each tackling a specific challenge in building autonomous systems.
Goal creation
Passive goal creator
This is the straightforward approach: the user says what they want, and the agent just rolls with it. It’s like an AI butler waiting for clear instructions—“Tell me exactly what you’d like me to do, and I’ll do it.” The downside? If the goal is confusing or incomplete, the agent might struggle to fill in the blanks.
Proactive goal creator
Here, the agent actively hunts for context. For instance, maybe it notices your Google Calendar events or your browsing history to guess that you need more than just a reminder. It might suggest scheduling a meeting, booking a ride, or even drafting an email on your behalf. This makes the agent feel more “intuitive” but also requires carefully handling privacy and not overstepping boundaries.

Enhanced reasoning
Prompt/Response optimizer
Large language models are super sensitive to how you phrase your question. This pattern acts like a translator or editor: it polishes up the prompt before sending it to the model and polishes the reply before handing it back to you. If you’ve ever texted with autocorrect turned on, imagine that but for AI prompts—helping the agent produce more consistent and tailored answers.

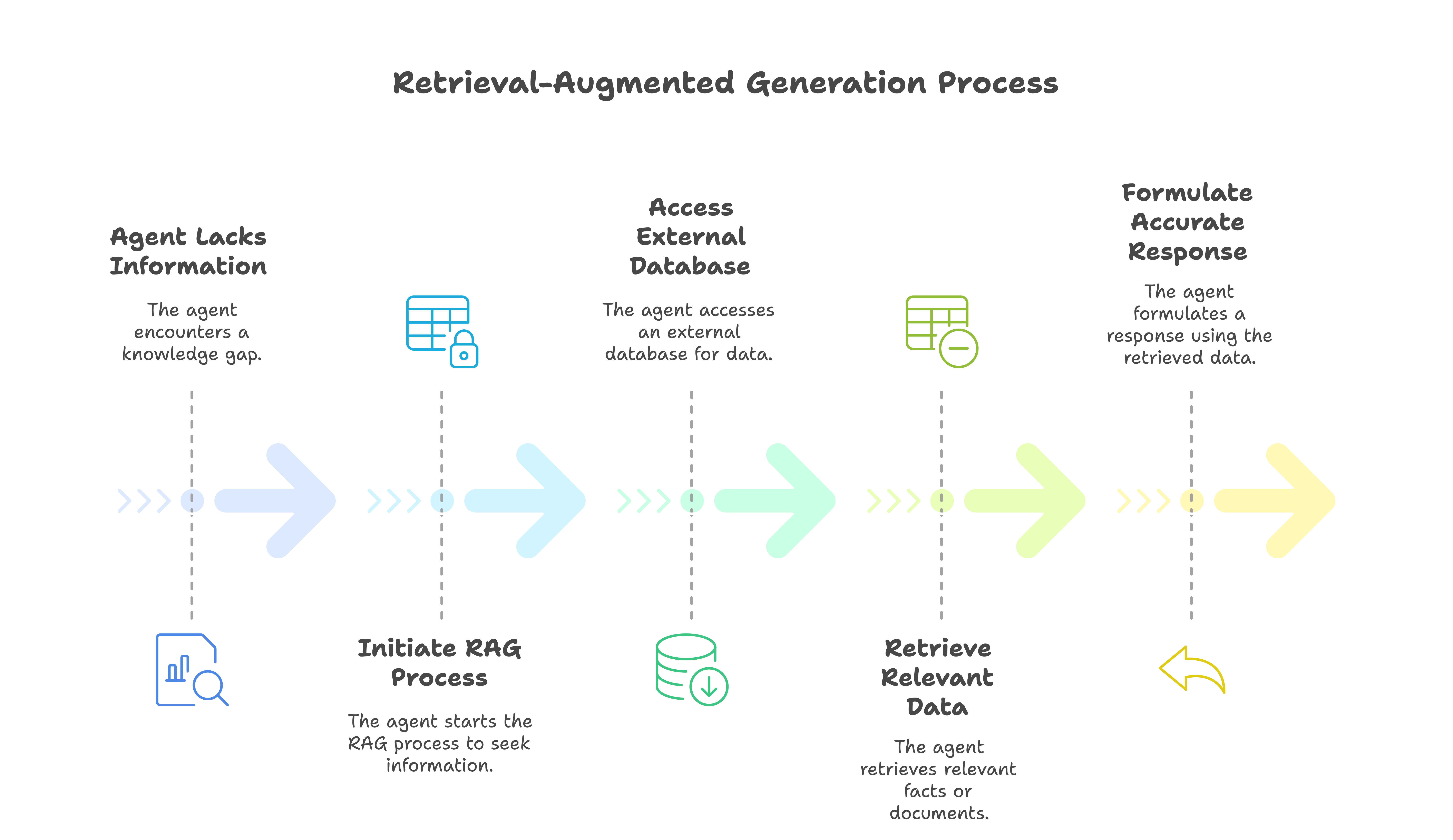
Retrieval Augmented Generation (RAG)
Sometimes the agent doesn’t know enough—or doesn’t have the right info “baked in”. RAG helps it look up facts, documents, or even images in an external database before forming a reply. Think of it like a student who checks a textbook or a search engine mid-conversation to give you a more accurate and up-to-date answer, without having to “retrain” the entire model.
Planning approaches
One-Shot model querying versus incremental model querying
One-Shot: The agent does its whole plan in one go. Quick and cheap, but sometimes it misses details or context. It’s like writing a to-do list in a single brainstorm without double-checking.
Incremental: The agent plans things step by step, asking follow-up questions along the way—sort of how you’d plan a road trip, city by city, instead of guessing everything up front. This leads to more precise answers but uses more compute (and more time).

Single-Path plan generator versus multi-path plan generator
Single-Path: The agent lays out a linear strategy. It’s easier to follow but might overlook alternative routes.
Multi-Path: Imagine branching paths where the agent can explore various ideas or solutions in parallel. This can be super helpful for complex tasks—like brainstorming multiple design concepts—and letting you pick your favorite.

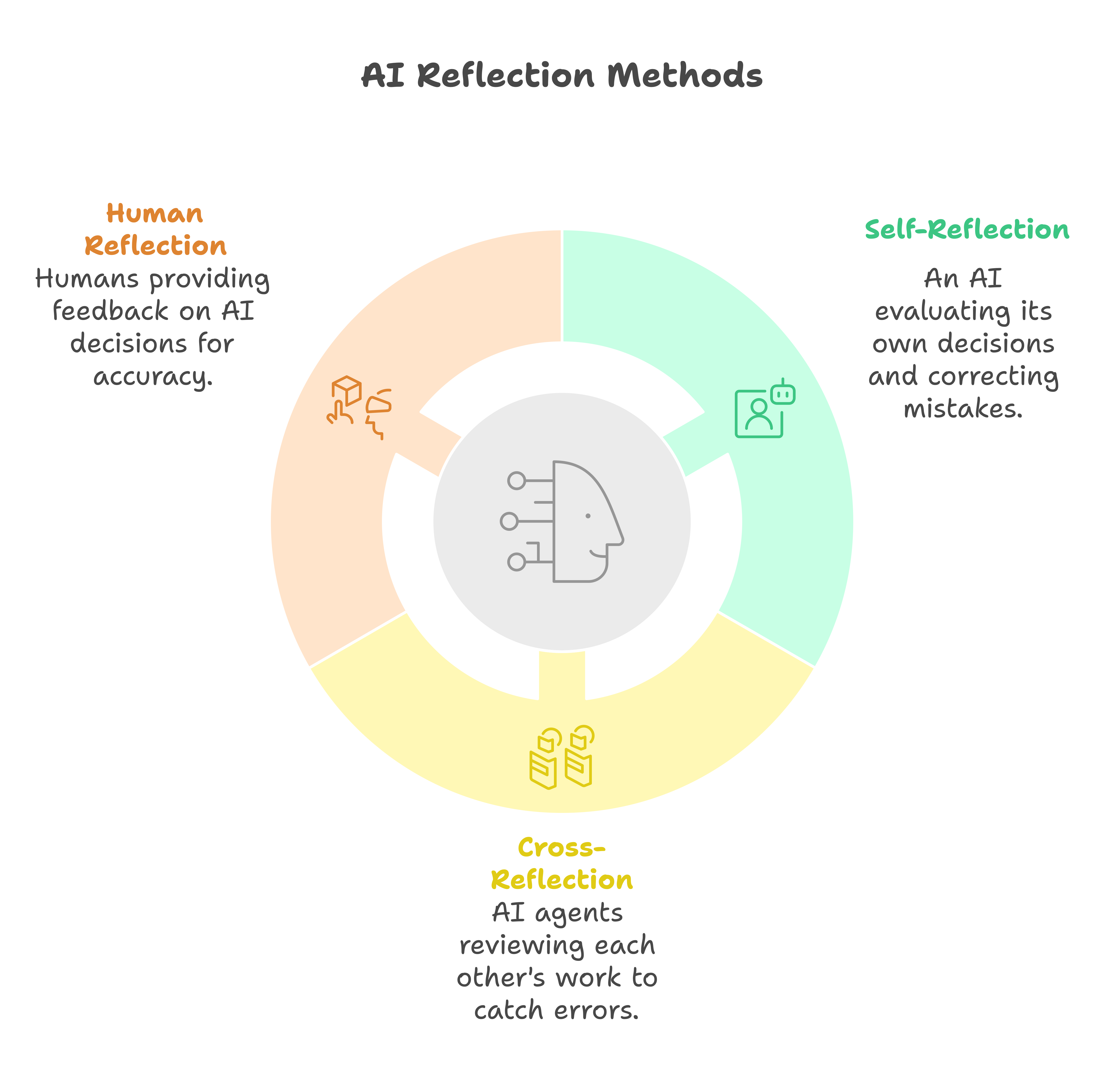
Reflection and feedback
Self-reflection
The agent does a “thought check” on itself. If you’ve ever paused to ask, “Did I do this right?” that’s self-reflection in action. The AI tries to spot and correct its own mistakes, possibly refining a proposed plan before showing you the final version.
Cross-reflection
Two or more AI agents reviewing each other’s work. This is like a pair of proofreaders catching each other’s typos. It can drastically reduce errors—assuming the “reviewer” agent is good at spotting mistakes!
Human reflection
Sometimes, you just need a real person to weigh in. An agent might show you its reasoning or plan, and you (or another human) say, “Hmm, that step doesn’t look quite right…” This not only improves accuracy but also keeps people in the loop for important decisions.
Multi-agent collaboration
Voting-based cooperation
Different agents propose different solutions, then cast votes. The majority or highest-scoring result wins. It’s democracy for AI agents!
Role-based cooperation
Agents get assigned roles like “Project Manager”, “Developer”, or “Tester”, each focusing on its own specialty. It’s like a mini virtual company where each agent does what it’s best at.
Debate-based cooperation
Picture a roundtable: each agent presents an opinion, they argue it out, and eventually converge on a consensus. This can expose hidden assumptions and yield better overall solutions.

Safety and integration
Multimodal guardrails
These are “filters” that catch harmful or unauthorized inputs and outputs (text, images, etc.) before they reach the model or the user. Guardrails help ensure your agent doesn’t accidentally share private data or produce offensive content.

Tool/Agent registry and agent adapter
Registry: Think of it as a big directory showing all the tools and agents available. If your main agent needs to handle a spreadsheet, it knows exactly where to “look” for a specialized Excel-bot.
Adapter: Agents and tools may speak different “languages” (different APIs, protocols), so an adapter acts as a universal translator so they can work together smoothly.

Agent evaluator
This is your test harness—like a teacher grading a student’s homework. You can check each agent’s performance, reliability, or even real-time results, and use that data to improve or replace agents that aren’t pulling their weight.

Key takeaways
Each pattern addresses a unique problem, whether it’s making the AI agent more flexible in goal-setting, more accurate in retrieving information, or better able to collaborate and explain its logic. By mixing and matching these patterns, you can craft a custom approach that fits the specific tasks and constraints of your project.

Up next, we’ll look at how to actually choose which pattern(s) make the most sense in different situations—and how they can be combined to form a well-rounded agent that’s both helpful and trustworthy.
How to select the right pattern(s)?
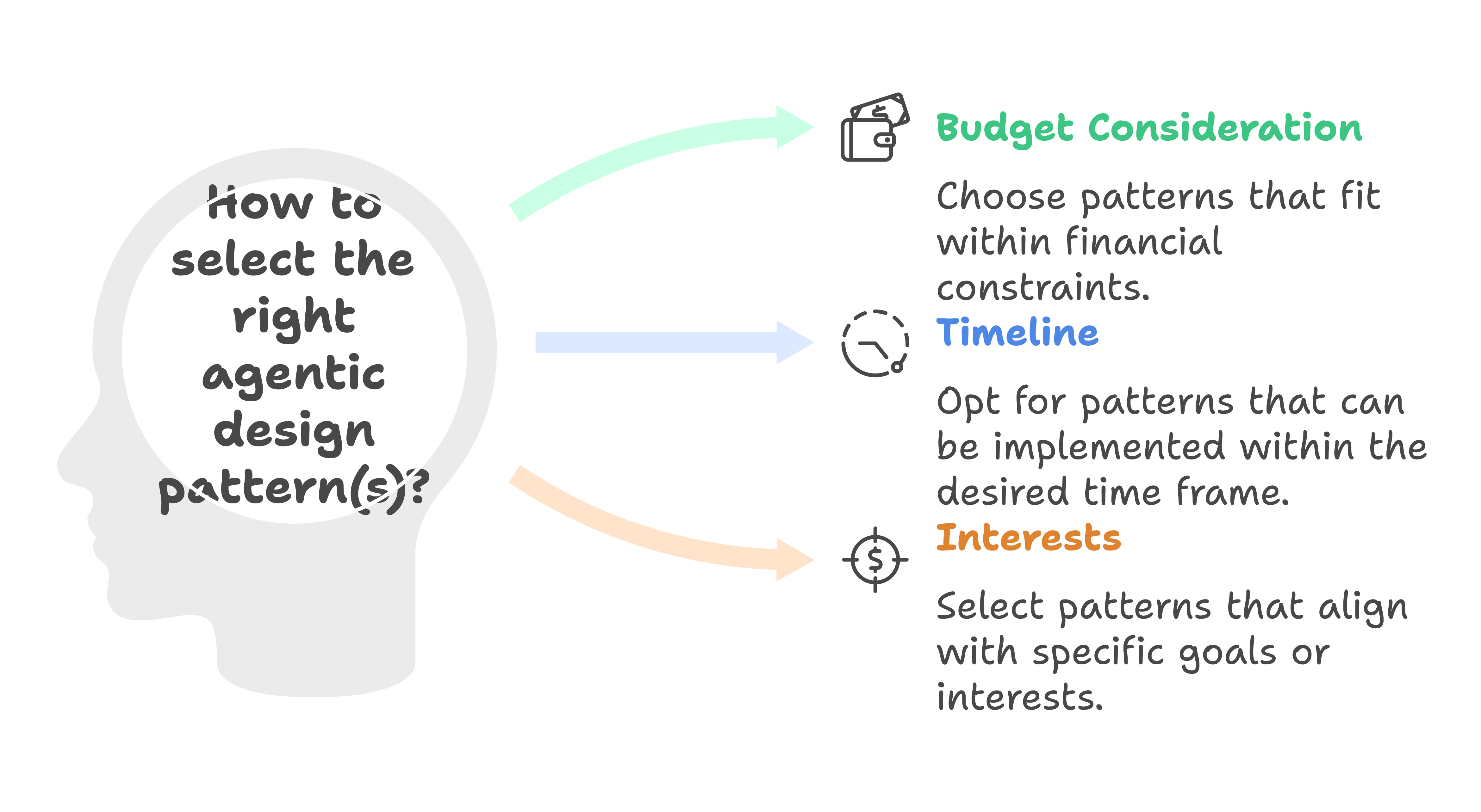
So, how do you actually choose which pattern (or combination of patterns) to use? Think of it like picking a travel itinerary: you’ve got options galore, but you want the perfect route tailored to your budget, timeline, and interests. Below are some guiding principles and examples to help you decide.
Decision factors
Complexity of the task
Simple Tasks (e.g., a quick Q&A bot) often do fine with One-Shot Model Querying or a Single-Path Plan Generator.
Complex Tasks (e.g., multi-step workflows or project planning) may call for Incremental Model Querying or a Multi-Path Plan Generator.
Risk and sensitivity
If mistakes are costly (financially or ethically), consider employing Reflection (Self, Cross, or Human) to catch errors.
For tasks with safety or legal risks, apply Multimodal Guardrails to vet inputs/outputs meticulously.
Collaboration needs
Simple, single-agent tasks? Go with a straightforward approach like Passive Goal Creator + Self-Reflection.
Multi-agent synergy? Patterns like Voting-Based Cooperation, Role-Based Cooperation, or Debate-Based Cooperation can help teams of agents converge on the best solution.
User preference and involvement
Users want a hands-on role? Provide Human Reflection so they can weigh in on decisions, or use Proactive Goal Creator to gather context without too much user input.
Users want something totally autonomous? Lean more on Cross-Reflection and ensure your guardrails are well-set.
Compute and cost constraints
On a tight budget? Minimize queries with One-Shot Model Querying and simpler reflection cycles.
If accuracy is paramount and resources allow, Incremental Model Querying plus multiple reflection steps might be worth the added cost.
Mixing and matching patterns
Much like pairing cheese with wine, some patterns complement each other really well.
Example 1: Incremental Model Querying + Cross-Reflection
The agent iteratively refines its answer, then a second agent double-checks each iteration. This combo is awesome for complex tasks that require both depth and reliability.
Example 2: Proactive Goal Creator + Multi-Path Plan Generator + Human Reflection
Great if you want the agent to gather context on its own, explore multiple solutions, then let a human pick the best path—perfect for creative or open-ended tasks like brainstorming or design.
Example 3: Voting-Based Cooperation + Multimodal Guardrails
Multiple agents propose different solutions, then a guardrail ensures nothing risky or off-limits gets through. Excellent when you have specialized agents contributing from various data sources.
Trade-offs to keep in mind
Speed versus accuracy
Fewer queries and no reflection cycles → faster responses, but potentially more errors.
More reflection or multi-agent debate → more accurate, but higher compute/time costs.
Autonomy versus human oversight
A fully autonomous agent can handle tasks unsupervised but might occasionally make bigger mistakes.
An agent that routinely asks for human input can catch errors early on but might pester the user too often.
Cost versus quality
Engaging multiple agents or extra reflection steps often requires more expensive model calls.
Trimming down reflection cycles saves money but could reduce reliability.

When choosing your design patterns, start by asking: “How complex is the task, and how important is it to get it really right?” Then weigh factors like time, cost, and the level of human involvement you want. By carefully selecting and combining patterns, you’ll craft an AI agent that’s not just impressive, but also fits your team’s workflow, your organization’s budget, and your users’ peace of mind.
Real-world examples
It’s one thing to read about design patterns in theory, but it’s far more illuminating to see them in action. Below are a few notable projects and scenarios where you can spot these agentic design patterns at work.
Open-source projects
Auto-GPT
Key Patterns: Multi-Path Plan Generator, Self-Reflection, Retrieval Augmented Generation (RAG)
How It Works: Auto-GPT breaks big goals into smaller, more manageable tasks. It queries the underlying language model step by step, searching online for additional facts (RAG) and iteratively refining the plan (self-reflection). The multi-path approach offers different possible routes to a solution, letting it pivot if one path hits a dead end.
BabyAGI
Key Patterns: Passive Goal Creator, Incremental Model Querying
How It Works: BabyAGI uses a simple structure where the user’s prompt directly sets the initial goal (passive goal creator). The agent then tackles tasks in multiple steps (incremental model querying), often keeping track of short-term memory to iterate toward more accurate results.
LangChain Agents
Key Patterns: Prompt/Response Optimiser, Tool/Agent Registry
How It Works: LangChain offers a library of “prompt templates” that polish user input, enabling better responses (prompt/response optimiser). It also maintains a library (registry) of various tools—like a web search plugin or a code interpreter—that agents can call on.
Commercial/Enterprise tools
Salesforce Einstein Copilot
Key Patterns: Proactive Goal Creator, Human Reflection
How It Works: The system proactively suggests next-best actions—like scheduling follow-ups or generating sales summaries—by analyzing user interactions and existing CRM data (proactive goal creator). It also gathers feedback from sales reps to fine-tune suggestions (human reflection).
Microsoft’s Copilot Stack
Key Patterns: Multimodal Guardrails, One-Shot Model Querying
How It Works: Copilot often uses a quick, single round of model calls (one-shot) to generate user-facing text or code. However, it applies guardrails to filter out content that might be harmful or too risky—especially crucial in corporate environments.
IBM Watson Orchestrations
Key Patterns: Role-Based Cooperation, Agent Evaluator
How It Works: In large enterprise deployments, different “agents” might handle data analysis, language understanding, or compliance checks. Each agent has a specific role, and they evaluate each other’s outputs to ensure they meet the organization’s security and accuracy standards.
Lessons learned
Reliability improves with layered feedback
Projects that incorporate reflection—whether self-reflection, cross-reflection, or human oversight—tend to produce more accurate and trustworthy outputs. Simply put, “two (or more) heads are better than one”, even if one of those “heads” is another AI model.
Guardrails are non-negotiable
Whenever user data or high-stakes decisions are involved, implementing Multimodal Guardrails is crucial. This ensures compliance with data privacy laws and keeps AI-driven actions from straying into harmful territory.
Cost-accuracy balancing act
Many open-source agents (like Auto-GPT) rely on repeated calls to large language models, which can get pricey. Some devs limit the Incremental Model Querying steps to manage compute costs, acknowledging that in practice, you have to weigh the budget against how precise or detailed the agent’s responses need to be.
User trust grows with explainability
Systems that reveal a bit of the “thought process”—like step-by-step planning or debate-based cooperation—tend to build more user trust. They also make it easier for developers to debug weird or incorrect outputs.
Scaling up means specialization
In more complex setups (think enterprise-level tools), Role-Based Cooperation often emerges. One agent might be a “data wrangler”, another a “compliance checker”, and yet another a “conversation manager”. This division of labor keeps the system organized and helps maintain a clear chain of responsibility.
Conclusion and future outlook
It might seem like a tall order to juggle complexity, accuracy, collaboration, and safety all at once. But that’s exactly what agentic design patterns are here to help with. They offer a clear, proven roadmap for anyone looking to build AI agents that don’t just sound smart but truly get things done—all while staying user-friendly, explainable, and trustworthy.
Why Agentic Patterns Matter? They transform the daunting process of wrangling big language models into a more structured approach. By following these patterns, you can avoid common pitfalls—like ambiguous goals or random “hallucinations”—and deliver robust AI assistants.
Key Takeaways
Start small: Pick one or two patterns (like One-Shot Querying plus Self-Reflection) and build from there.
Listen to feedback: Whether it’s from humans or other AI agents, reflection is the superpower that keeps your system improving.
Keep it safe: Guardrails, role-based cooperation, and thorough evaluations matter, especially when users trust your system with important tasks.
As foundation models evolve, we’ll likely see more sophisticated ways for AI agents to team up—Debate-Based Cooperation could become a core strategy, enabling deeper discussions and more creative problem-solving.
Future agents might learn to tailor their patterns on the fly. Imagine an agent that automatically decides, “Okay, this user wants a quick fix, so I’ll stick to one-shot queries”, or “This situation is high-stakes, so I’ll switch on multiple reflection steps”.
Expect clearer guidelines on topics like data privacy, model accountability, and bias control. In some industries, advanced Multimodal Guardrails or Agent Evaluators might become not just best practices but legal necessities.
If you’re curious to try these patterns out, there’s no better time to dive in! Many open-source projects (LangChain, Auto-GPT, BabyAGI, and more) already demonstrate these ideas in code, and you can adapt them to your own use cases. Experiment, measure results, and refine your approach. Share your successes—and your hiccups—so the community can learn and improve together.
By blending creativity with a bit of engineering discipline, we can harness the power of AI agents in all sorts of fields—from building the next must-have productivity app to revolutionizing customer service, healthcare, finance, and beyond. With agentic design patterns at your side, you’re set to craft AI systems that are not only cutting-edge but also human-centered and responsible. So go forth, code away, and let your agents shine!
Very techy brother, but it is useful. We learn something new every day! 👍