
Why we need Queues - and what they do when no one is watching
System design fundamentals


Imagine you’re building an online store.
Everything runs smoothly - until Black Friday hits.
At 10:00 AM, the servers start sweating. Every “Buy Now” click becomes a request screaming for immediate attention.
The system can’t keep up. The queues form… except this time, not in code - in the minds of frustrated users.
The fix? Queues. But not the human kind - the kind your system understands.
The scene above might feel dramatic, but it’s a reality for many systems under sudden load. Before diving into definitions, feel the pain: overloaded servers, timeouts, and angry customers. In these moments, message queues emerge as unsung heroes. This article explores why we need queues and what they do behind the scenes when no one’s watching.
🚀 Love learning how real-world systems survive chaos?
Get more developer-friendly deep dives like this - delivered right to your inbox.
🔍 Why queues exist
In modern distributed systems, different components rarely work at the exact same speed or capacity. Workloads are often uneven - sometimes a surge of tasks comes in all at once (like our Black Friday sale), other times it’s quiet. Often, an upstream producer creates work faster than the downstream consumer can process.1 Without intervention, this mismatch leads to backlogs, slowdowns, or outright failures.
A message queue exists to handle this mismatch. Think of it as a safety buffer or shock absorber in your architecture. The producer can toss tasks into the queue as fast as needed, and the consumer will pull them out as fast as it can handle. The queue quietly holds onto the overflow - letting the rest of the system breathe. It’s like a waiting room in a hospital - it doesn’t make the doctor faster, but it keeps the hallway calm. In other words:
A queue is like a hospital waiting room - patients (tasks) sit and wait their turn. It doesn’t help the doctor finish sooner, but it prevents a chaotic pileup at the doctor’s door.
By absorbing rapid bursts of work, queues prevent system chaos. They smooth out traffic spikes by buffering messages until the consumer is ready.2 This means your system is less likely to crumble under a peak load – instead, it queues excess work for later processing. Users get faster initial responses (even if some work happens in the background), and your services get a chance to catch up.
⚙️ How Queues actually work
So, what exactly does a queue do behind the scenes? At its core, a message queue is a storage area for messages (tasks, data, requests - any work units). One part of your system (the producer) sends messages into the queue. Another part (the consumer) picks them up and does the processing, often asynchronously.
Let’s break down a message’s journey in a typical queue system.
Produced: A producer application sends a message to the queue (e.g., “
New Order #12345”).Queued: The message sits in the queue, waiting its turn. (This is the “buffer” period - potentially microseconds or hours, depending on system load).
Consumed: A consumer application retrieves the message from the queue and begins processing the order. Importantly, no other consumer will get this message at the same time.
Acknowledged: Once processed, the consumer sends an acknowledgment to the queue. The queue can then remove the message, knowing it’s been handled successfully.
This flow turns a system from “do it now” into “do it when you’re ready”. By inserting that waiting period, the producer isn’t blocking on the task being done - it can move on to other things, confident the queue will eventually deliver the work to a consumer.
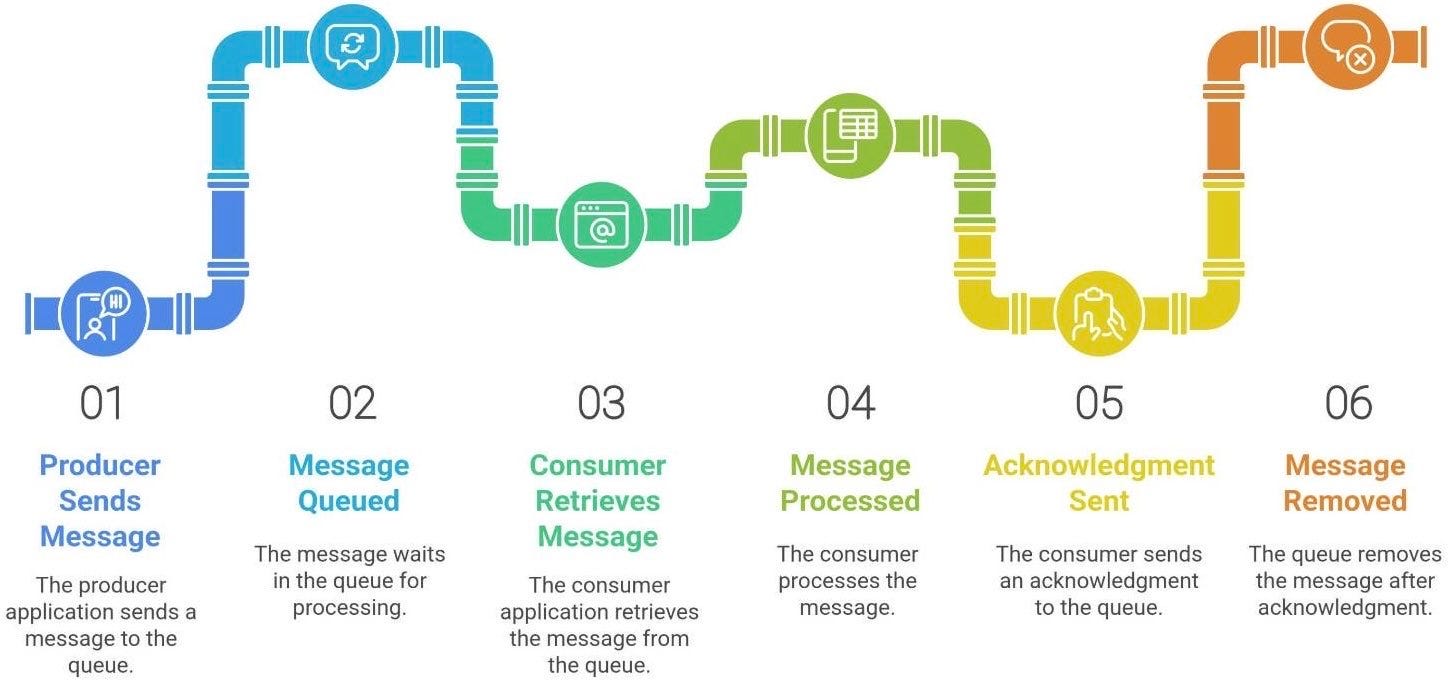
The diagram above is the simplest view: the producer puts messages in one side, and the consumer takes them out the other. Decoupling is the magic here. The producer and consumer don’t interact directly; they communicate via the queue. If the consumer is slow or temporarily offline, the messages just pile up in the queue - the producer doesn’t need to slow down or fail in the meantime. Conversely, if the producer slows down, the consumer can continue working on whatever is in the queue.
To illustrate with a snippet of (simplified) Python-like pseudo-code:
# Producer sends a message (e.g., an order request) to the queue.
queue.send(order_request)
# ... time passes, message waits in the queue ...
# Consumer fetches the next message from the queue when ready.
order_request = queue.receive()
process(order_request)
queue.acknowledge(order_request) # confirm the message was processed
In a real system, the queue server (broker) marks the message as “invisible” for others once a consumer picks it up. After processing, the consumer acknowledges it. If the consumer fails to acknowledge (say it crashed), the message becomes visible in the queue again after a timeout, so it can be retried.3 This guarantees that every message will eventually be handled, even if something goes wrong mid-process.
This tiny shift - using a queue - makes a system asynchronous. The producer no longer waits for the work to finish. It just drops a message and moves on. The system becomes more flexible: tasks get done when there’s capacity, rather than all “right now” at once.
💥 Life without Queues
What happens if you don’t have a queue in situations of uneven load? In short, chaos. Let’s paint the picture: suppose your Payment Service calls the Shipping Service directly for each order. It works fine under light load. But one day, orders flood in:
If Shipping slows down or (gasp!) goes down, Payment is stuck waiting. Users clicking “Pay” start seeing spinners or errors. The payment calls fail because the downstream service isn’t responding.
As traffic increases, Payment and Shipping form a tight chain. The slowest component dictates the system’s speed. Users who click faster than Shipping can handle end up queuing in their browsers - or giving up.
Even worse, a failure cascades. If Shipping crashes under load, it takes Payment down with it. A single point of failure can ripple outward, causing a domino effect.4
This is the bottleneck of doom that tightly coupled systems face. Every component must be up and fast for the whole flow to work. In a synchronous call setup, Service A is blocked until Service B finishes. If B fails, A fails; if B is slow, A is slow. It’s brittle and dangerous, especially as you add more services into the mix.
Now contrast that with a queue-based approach (the asynchronous solution). Payment would post an “Order placed” message to a queue. Shipping will pick up orders from the queue at its own pace. If Shipping is down, orders just stay in the queue for a bit; Payment doesn’t crash - it can continue taking orders. When Shipping comes back, it processes the backlog. In the meantime, customers checked out successfully - maybe with a note “We’ll email your tracking info soon”, but the site stays running.
By inserting a queue, you decouple the pace of different components. Each part can fail independently without bringing the whole system down. The result is a more resilient architecture: one that degrades gracefully instead of exploding under stress.
Synchronous calls create brittle systems that fail together, while asynchronous messaging creates resilient systems that fail independently. In other words, message queues are your decoupling superpower.
🧮 Queues in practice - RabbitMQ, Kafka & Friends
All this theory is great, but how do we implement queues in the real world? There are many messaging tools and services out there. Here are a few popular ones, each with its own flavor:
RabbitMQ is a traditional message broker that implements the AMQP protocol. It excels at reliable delivery and complex routing (topics, fan-out, etc.), ensuring messages get to the right place. For example, you might use RabbitMQ to queue tasks for sending emails: each email request is a message, and a pool of consumers sends them out one by one, guaranteeing none are lost.
Kafka, on the other hand, is often described as a “distributed commit log”. It’s great for streaming large volumes of data (think millions of events per minute). Kafka retains ordered logs of events, and consumers track their offset (position) in the log as they go. It’s perfect for systems where you replay or process event histories and need high scalability.
Cloud services like Amazon SQS and Google Pub/Sub offer queueing as a service. You don’t install anything - you just use their API. They automatically scale and are highly reliable. These are great when you need a queue but prefer the cloud provider handle the dirty work (maintenance, scaling, fault tolerance). For instance, SQS guarantees at-least-once delivery of messages and provides features like dead-letter queues out of the box. Similarly, Pub/Sub on GCP handles fan-out messaging to multiple subscribers easily.
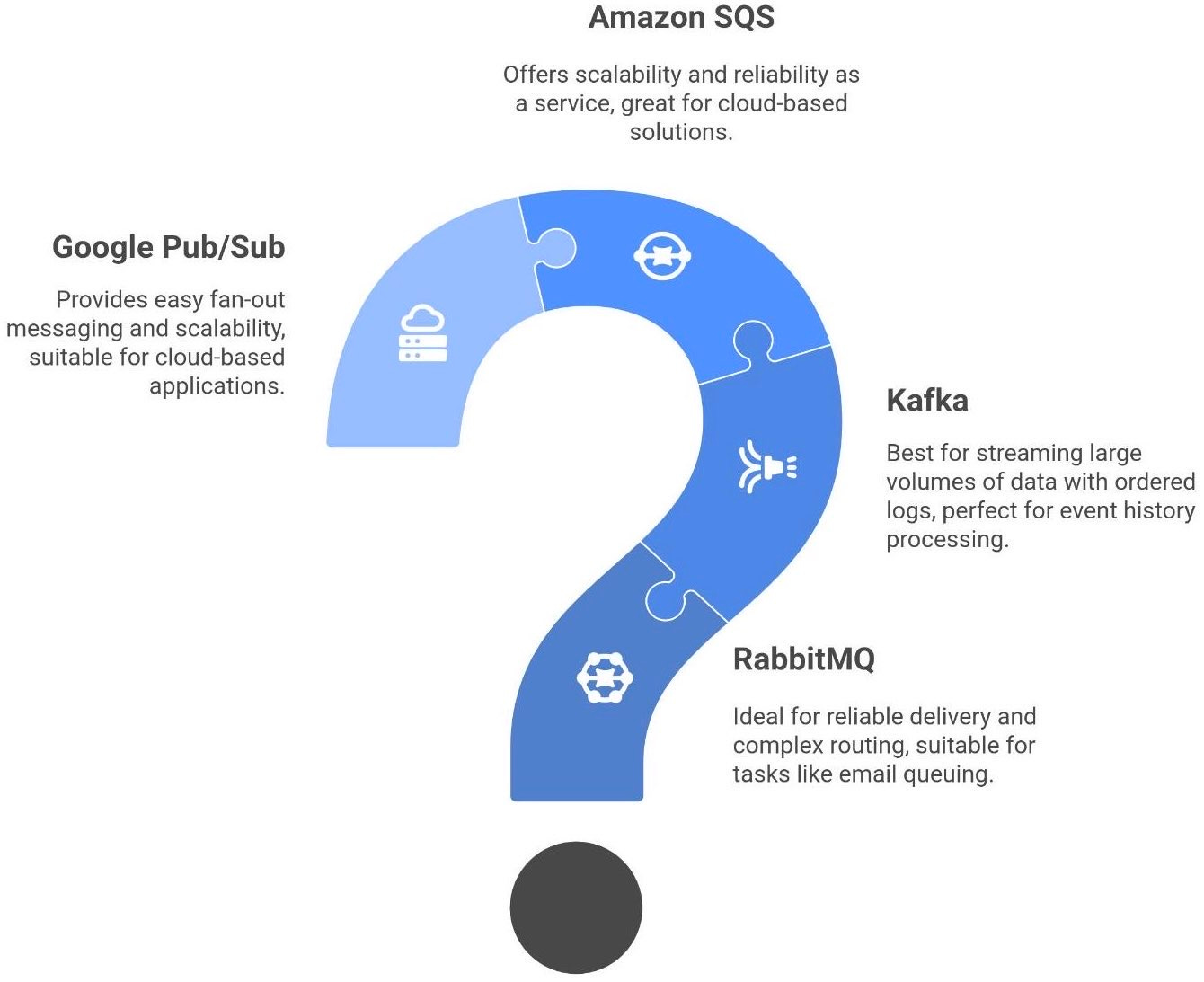
Each of these “friends” has its nuances, but all share the same core idea: don’t call services directly; instead, communicate via an intermediary queue. As one engineer put it:
Queues don’t just move data - they set the rhythm of your system.
By buffering and dispatching messages, queues essentially dictate when each part of the system gets to work, acting like a conductor in an orchestra. The result is a more harmonious (and resilient) performance.
🧠 Key concepts to know
Before you run off to implement your own queue, let’s demystify some jargon you’ll encounter. Here’s a quick glossary of queue concepts:
Consumer Group. A set of consumers collaborating on the same queue or topic. In a consumer group, each message is delivered to only one member of the group.5 This is how you scale out processing - e.g., three consumers in a group can divide the work of one queue. (Kafka uses consumer groups heavily for parallelism.)
Offset. A marker of how far a consumer has read in the queue. Think of it as a bookmark in a stream of messages. For example, Kafka assigns each message a sequential offset number; a consumer’s position (last processed offset) tells it where to resume next time.6 Offsets prevent re-reading from the start every time and help with recovery (you know what’s been processed).
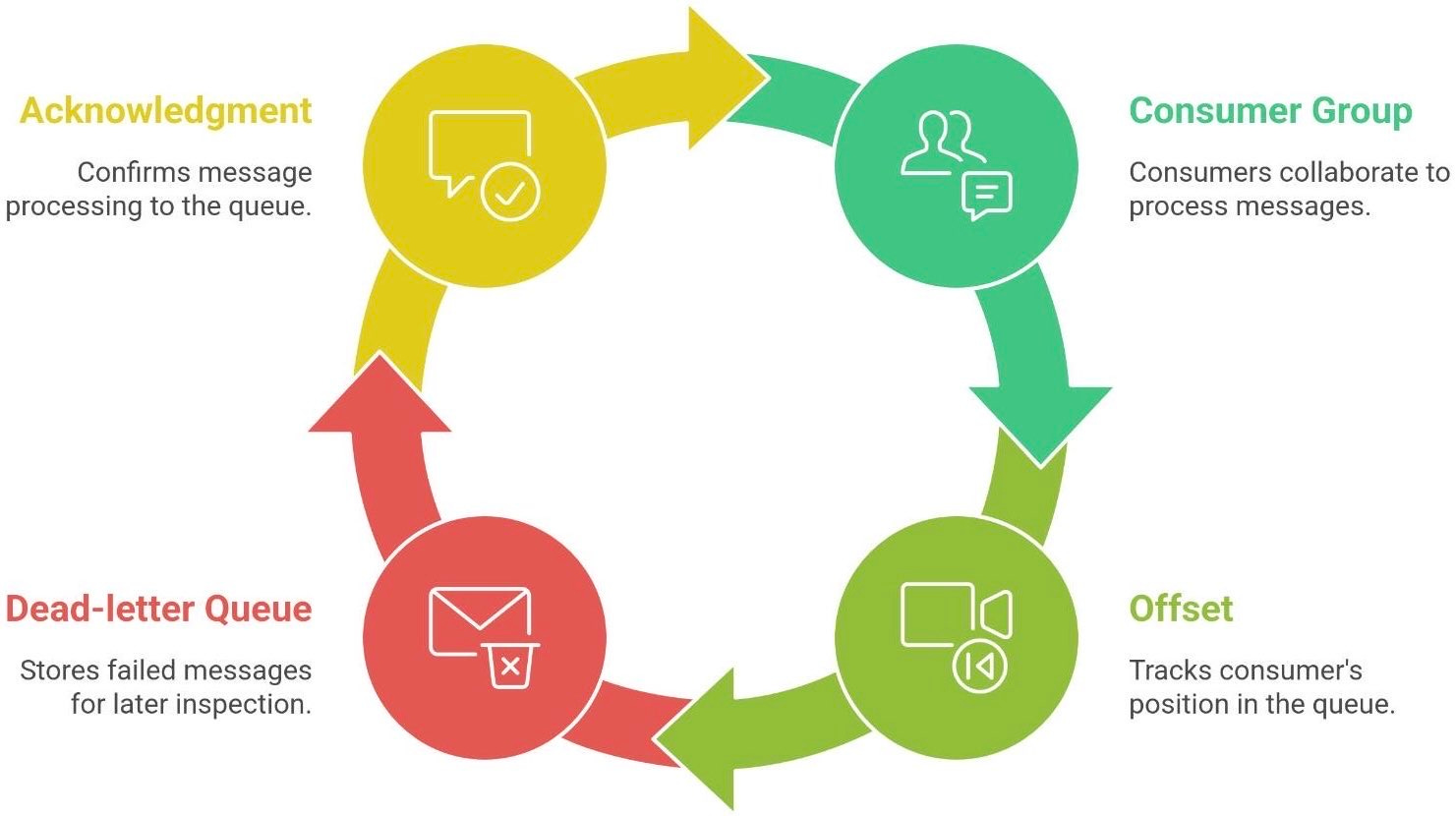
Dead-letter Queue (DLQ). A special queue where messages go when they fail repeatedly. If a message can’t be processed after X tries (due to errors, etc.), it’s often routed to a dead-letter queue rather than clogging the main queue. Think of it as the “rejects” bin for problematic messages - they can be inspected or retried later without affecting the primary flow.
Ack (Acknowledgment). A signal from consumer to queue that “I got the message and handled it”. For example, in RabbitMQ a consumer sends an ACK after processing, so the broker knows it can remove that message from the queue. If no ack is received (perhaps the consumer died), the message is requeued or made visible again. Acknowledgements prevent data loss by ensuring work isn’t dropped even if something goes wrong mid-processing.
These concepts help ensure your queue-based system runs smoothly. For instance, using consumer groups means you can scale out processing while each message is still handled only once. Dead-letter queues ensure you don’t get stuck on a poison message that can’t be processed - it gets set aside for later analysis. And acknowledgments combined with offsets give reliability: they guarantee that work is either done at least once or the system knows to retry it.
🧩 How Queues protect systems from overload
One of the biggest advantages of queues is how they shield your system from overload. By their very nature, queues introduce a form of backpressure. This means when the intake of work is faster than the output, the work doesn’t break the system - it simply accumulates in the queue. The system as a whole slows down gracefully instead of crashing.
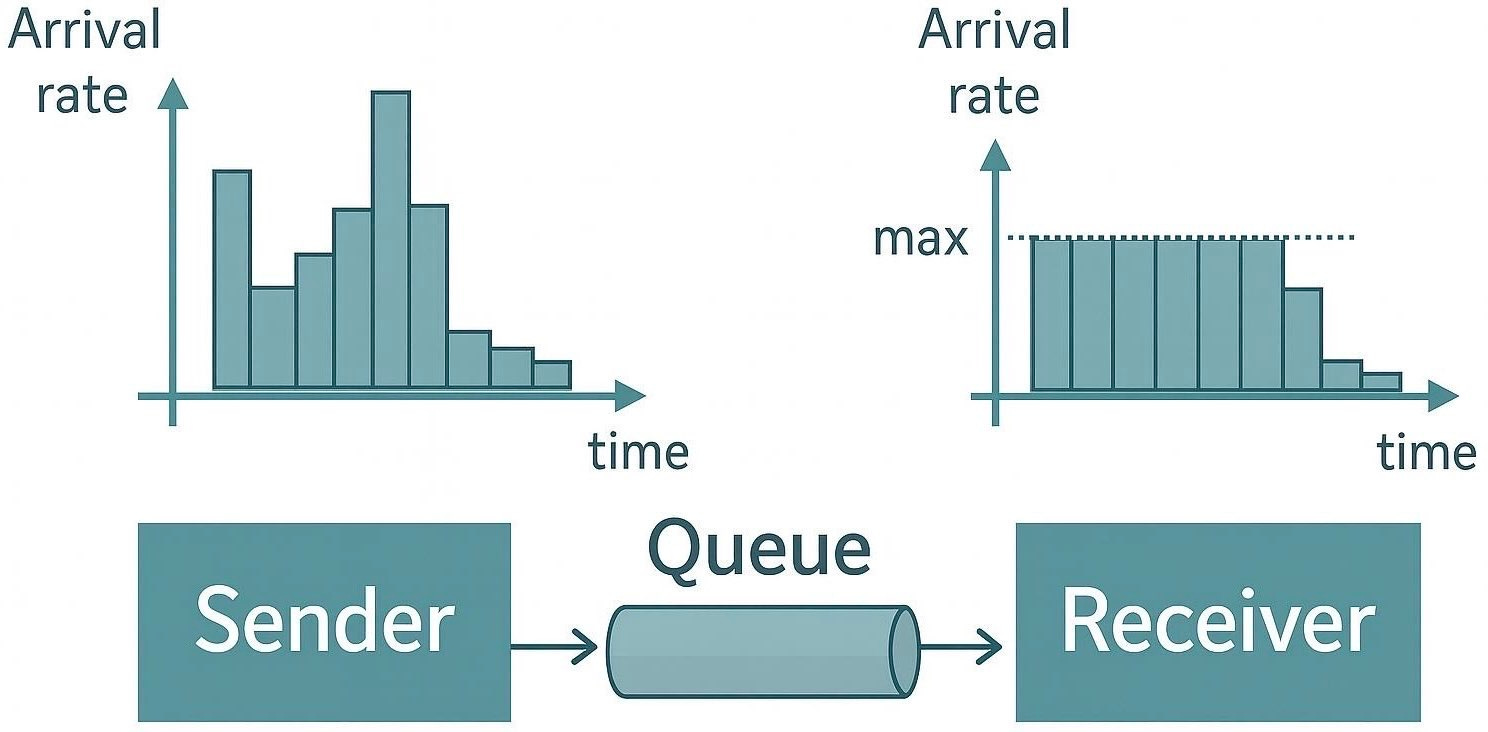
A message queue can act as a traffic buffer. In the left graph, incoming requests fluctuate wildly, sometimes exceeding what the system can handle. On the right, after introducing a queue, the processing rate stays steady and within safe limits, smoothing out the spikes. The backlog accumulates temporarily in the queue, protecting the consumer service.
Let’s revisit our online store example. Without a queue, a surge of 1000 orders in a minute might overwhelm the order processing service, leading to errors or a crash. With a queue in place, those 1000 order messages are all accepted quickly into the queue (so the users’ checkout experience is fast), and then the orders are pulled out one by one (or a few at a time) by the processing service. The service might only handle, say, 100 orders per minute, but that’s okay - it will work through the backlog over the next 10 minutes. Importantly, the front-end doesn’t collapse under the spike.7 It absorbed the burst, and the system remains stable (albeit with a slight delay in processing).
This is the essence of load leveling. Queues level out the peaks and troughs of traffic. During a traffic spike, the queue grows longer (acting as a buffer). During quieter times, the queue drains as consumers catch up. The average rate of processing can remain stable even if the incoming rate is jagged. It’s much easier to design a system for a steady 100 orders/min than to design for sudden bursts of 1000/min followed by zero/minute lulls.
A real-world use case: E-commerce checkout. When a customer places an order, the website immediately puts an “Order Placed” message onto a queue and instantly confirms to the user (“Thank you, your order is received!”). Downstream, an Order Processing service will take messages from the queue and actually process payments, update inventory, notify shipping, etc. If there’s a Black Friday rush, the order confirmations still happen instantly (queue accepts them), and the processing service works through them as fast as it can. The user experience is preserved - the site stays responsive - even if actual fulfillment is a bit behind the scenes.
Another example: Email sending. Suppose your app needs to send thousands of emails (like newsletters or notifications). If you try to send 10,000 emails all at once, your email server (SMTP) or third-party API might choke (or rate-limit you). Instead, you put email requests into a queue. A worker service pulls, say, 50 emails per second from the queue and sends them. This naturally throttles the outflow to a rate the email server can handle. You never suddenly dump 10k requests; you trickle them. The queue ensures no email is lost, just sent a bit later if needed. The system remains stable and you avoid flooding any component.
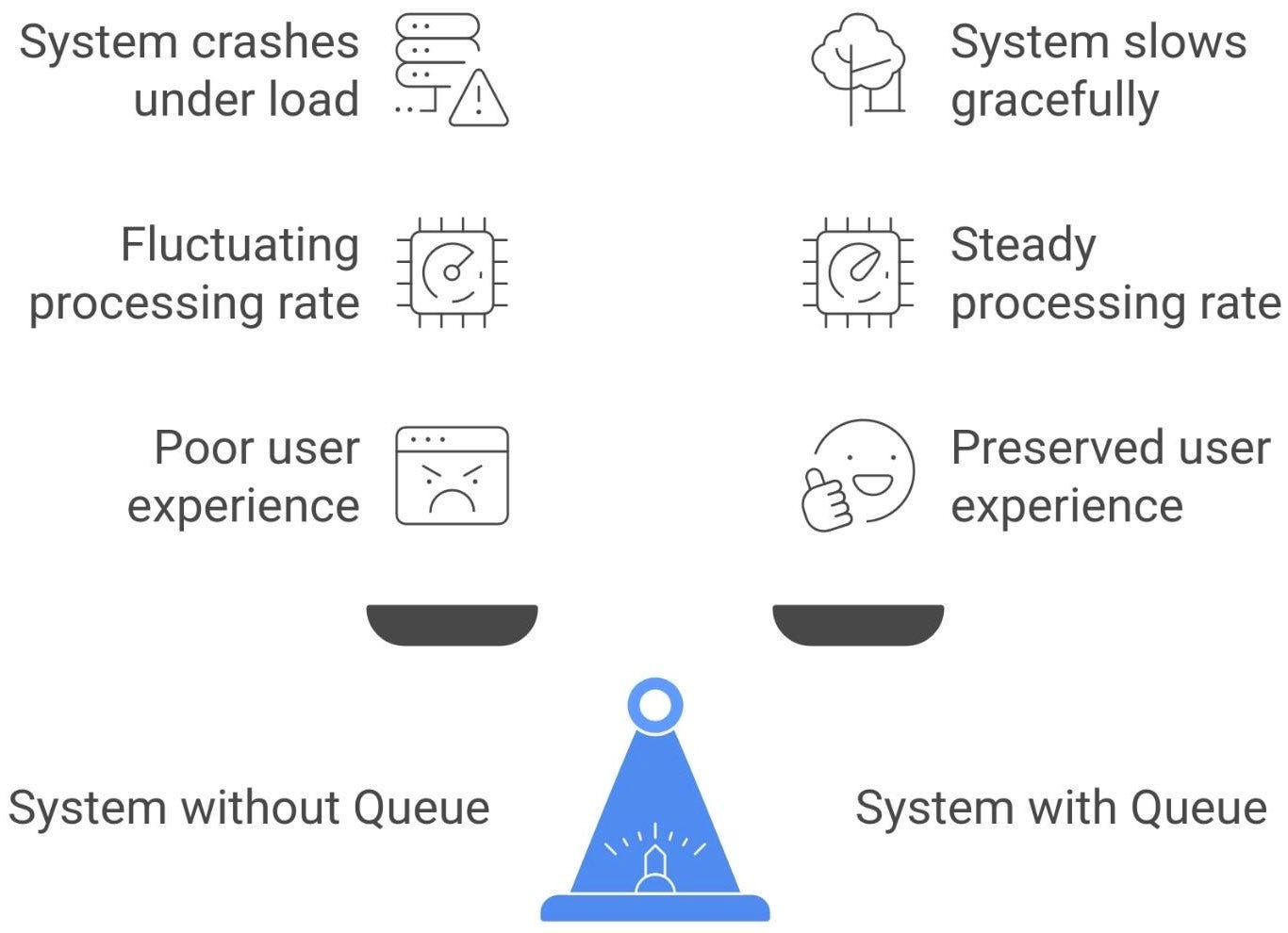
In summary, queues act as a buffer zone between the fast and slow parts of your system. Producers can run at full blast, confident that if consumers can’t keep up immediately, the work will simply wait its turn. Instead of erroring out or crashing under overload, the system’s heartbeat just goes a bit slower. All components operate at their own optimal pace, and the queue handles the hand-off.
Of course, if producers permanently outpace consumers, a queue isn’t a magic infinite bucket - eventually it will fill up or messages will wait so long they become irrelevant. We’ll address those pitfalls next.
⚠️ The dark side of Queues
Queues are powerful, but like any tool they come with trade-offs and pitfalls. It’s important to be aware of these “dark side” aspects so you can design your systems to handle them.
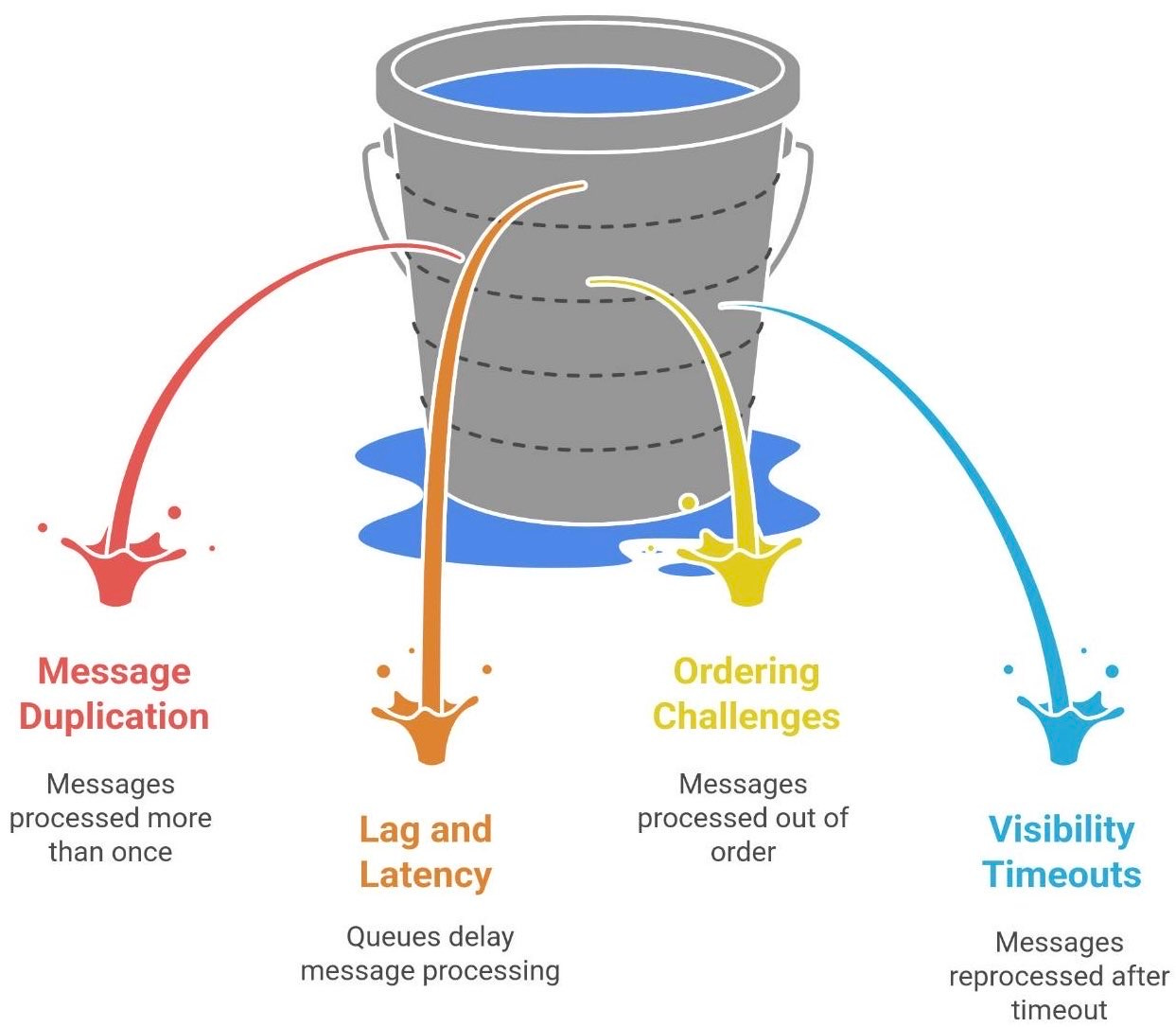
Message duplication. Many queue systems (for example, cloud queues like SQS) guarantee at-least-once delivery. This means it’s possible the same message will be delivered twice on rare occasions. Network hiccups or crashes might make a consumer appear to not have processed a message, so the broker redelivers it, and you end up doing the task twice. The solution is to design idempotent consumers – in plain terms, make sure that processing a message twice has the same effect as once. For instance, if the message says “ship Order #123”, your shipping service should check if Order #123 was already shipped before doing it again. Assume duplicates will happen, and guard against any harmful side effects.
Lag and latency. A queue can delay processing. If your queue grows very long (say, millions of messages), some messages might not get processed for a long time. In extreme cases, this could violate user expectations (imagine if an order confirmation email arrives 3 days late). Long queues also mean more memory/disk usage and potentially timeouts if messages become too old. In practice, if you see queue lengths growing without bound, it’s a sign your consumers are consistently too slow for the incoming workload – you either need more consumers, faster processing, or to throttle the producers (see flow control). Also consider message TTL (time-to-live) for things that have an expiry, or implementing backpressure to inform producers to slow down when queues are too full.
Ordering challenges. Queues often don’t guarantee that messages will be processed in the exact order they were sent, especially when you have multiple consumers or partitions. For example, if two messages A and B are sent, it’s possible B might get processed before A in some setups (unless the queue is strictly FIFO). Even with a single queue, if a message fails and retries, it might be handled out of sequence. If order matters (say, two updates to the same user’s profile), you have to design for it – either use ordering keys/FIFO queues or ensure each message is independent. In distributed systems, once you introduce parallel consumers, ordering is not guaranteed by default. You may need to enforce ordering in the consumer logic or restrict certain flows to a single consumer.
Visibility timeouts and reprocessing. When a consumer takes a message from a queue, that message is often hidden (invisible) from others for a visibility timeout period. If the consumer fails to acknowledge before this timeout, the message pops back onto the queue for someone else to retry. This is great for reliability, but it means your system must tolerate the same message being processed more than once in parallel or sequentially. Also, if a task truly always fails (e.g., bad data), it could get stuck in a cycle of being redelivered over and over. That’s where the earlier mentioned dead-letter queue is important - after a few failed attempts, send the message to a DLQ so you can investigate it without blocking the main queue.
In short, queues require discipline. You gain resilience and flexibility, but you also inherit the complexities of an asynchronous system. Monitoring becomes key: you’ll want alerts if queues are backing up too much (indicative of a problem). You’ll need strategies for poison messages (DLQs) and duplicate handling (idempotency). Ordering might need extra attention if it’s critical to your application’s correctness.
🧠 What’s your take on the dark side? Ever wrestled with duplicate messages or visibility timeouts?
I’d love to hear your war stories or wins - let’s chat below.
The “dark side” isn’t a reason to avoid queues, but it is a reminder: power comes with responsibility. A poorly managed queue can become a black hole (messages languishing forever) or a source of subtle bugs (duplicate processing). With good design and practices, these issues are all manageable.
🔄 How it all connects
By introducing queues, many systems find themselves evolving toward an event-driven architecture (EDA). In an event-driven mindset, instead of components calling each other directly (imperative “do this now” commands), they emit events (facts about something that happened) and other components react to those events.
Using queues is often the first step in this direction. You stop asking “What should happen now in this workflow?” and start asking “What just happened, and who cares about it?” When Payment places an “Order Placed” message on a queue, it’s essentially saying: “This event occurred”. Now any service interested in orders (billing, shipping, notifications, analytics) can subscribe to that queue or topic and do its part, independently. You can add a new service (say, a ReportingService) later that also listens for “Order Placed” events, without touching the Payment or Shipping code at all. This is the essence of loose coupling.
Over time, a simple queue for point-to-point communication can grow into a publish/subscribe system with multiple consumers and producers all interacting via events. Architectures like microservices often leverage queues and pub/sub to keep services decoupled and scalable. It’s a different way of thinking about system design - more like a network of small reactive processes rather than a single big – program.
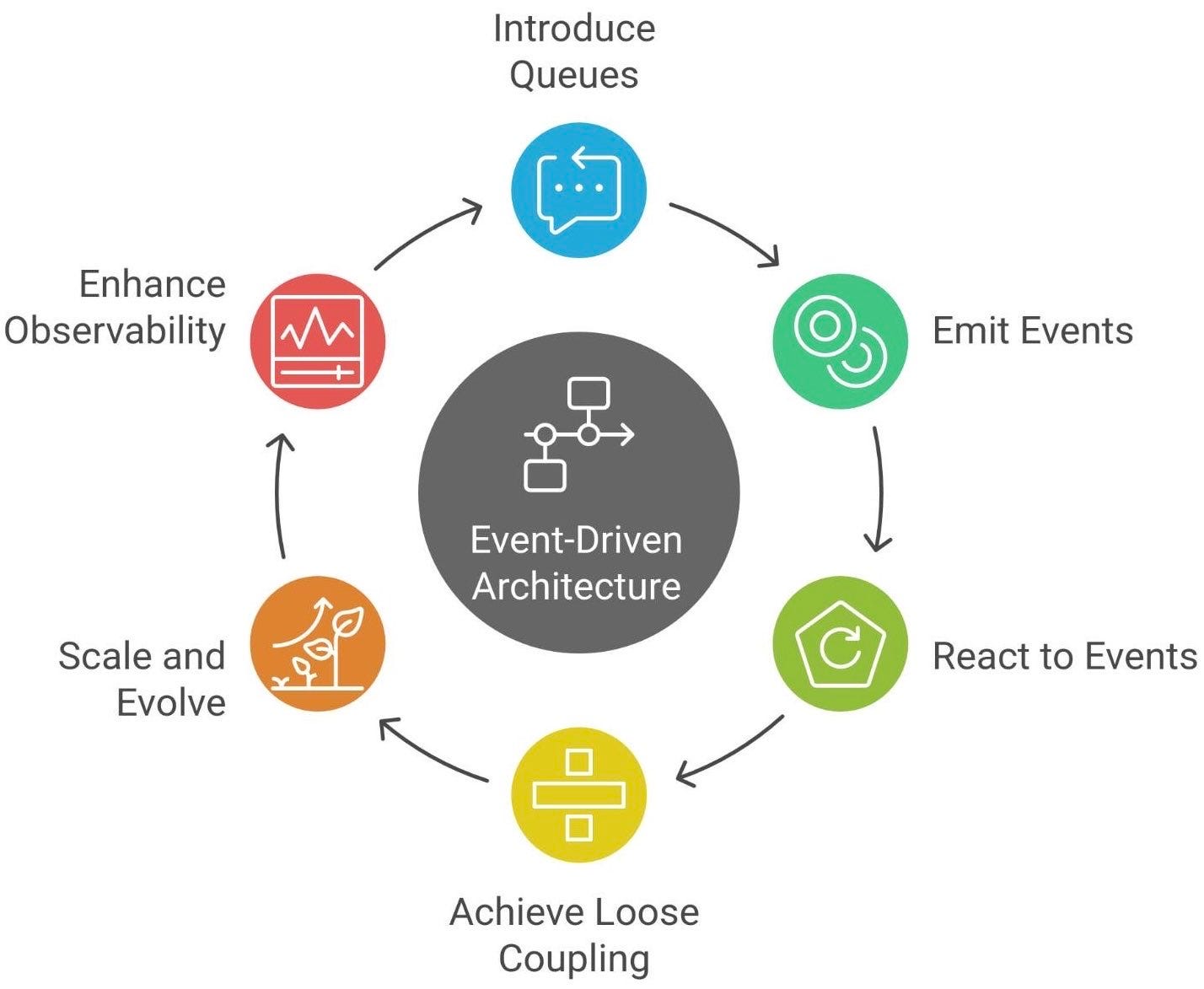
The beauty is that queues allow your system to scale and evolve. Need to handle more load? Add more consumer instances to process from the queue (forming a consumer group). Need to add new functionality? Just plug in a new event handler that listens to relevant queues, instead of rewriting the whole flow. The system becomes a set of building blocks connected by queues (event channels), which can be rearranged or extended with minimal fuss.
In other words, adopting queues is a gateway to thinking in terms of events and reactions. It can lead to more robust systems, because each part is isolated - they communicate only via the messages, not by direct assumptions about each other’s state or timing. This often results in systems that are easier to maintain and expand, as new requirements can be met by adding new message types or consumers rather than modifying existing ones.
Everything connects: queues, by decoupling components, set the stage for an architecture where everything is an event. And once you go down that path, you might discover your system is not just handling spikes better, but is also more extensible and observable (since you can monitor the event flow, inspect queues, etc.).
🧭 Closing thoughts
Building systems is as much about handling failure and unpredictability as it is about the “sunny day” scenarios. Message queues shine in those chaotic moments. They are the heartbeat of a distributed system, giving it rhythm and resilience. They absorb bursts of traffic, prevent cascades of failure, and let each component work at its own pace.
Yes, queues add complexity - you must handle eventual consistency, delayed processing, and other quirks. But the payoff is huge: your services won’t easily knock each other over like dominoes. As an engineer (especially a beginner), learning to integrate queues is a stepping stone to designing systems that scale and survive real-world demands.
Ultimately, queues help engineers (and users!) sleep better at night. Instead of dreading the midnight spike or the next big sale, you can be confident your system will bend, not break.
Queues are the heartbeat of a system.
They give rhythm, absorb chaos, and let components breathe at their own pace.
Thanks to them, systems stay alive — and engineers sleep better.
✍️ Recap
What are queues? A queue is a buffer between components - a place where messages wait so that producers and consumers can work at different speeds. It turns “immediate” calls into asynchronous work.
Why use them? Queues help with scaling and fault tolerance. They even out traffic spikes (prevent overload), decouple services (one can fail or slow without bringing the other down), and improve resilience and throughput.
Tools: There are many implementations - RabbitMQ for robust task queueing, Kafka for high-volume streaming, cloud services like AWS SQS or GCP Pub/Sub for managed simplicity. Use the right tool for your needs (consider factors like throughput, ordering, persistence).
Challenges: Queues aren’t silver bullets. Be mindful of duplicates (use idempotency), potential delays (monitor queue length), ordering issues (design accordingly), and the need for proper error handling (dead-letter queues for poison messages).
Big picture: Queues enable event-driven architectures. They allow systems to react to events at their own pace and scale out by adding consumers. In exchange, they require a shift in thinking (asynchronous mindset) and careful design.
📢 Know someone who’s starting out in backend or devops?
Share this post and help them understand queues before the queues understand them.
By embracing queues, even a beginner developer can start to solve complex scaling problems with elegance - turning panic into ordered (pun intended) chaos that a system can handle. In short, queues keep the data flowing and the systems going, even when no one’s watching.
The best engineering lessons are the ones that teach resilience, not speed.