
Understanding locking contention in computing
System Design


Imagine a busy household with only one bathroom. In the morning rush, if one family member is in the bathroom, everyone else has to wait their turn.
In computing, lock contention is a similar situation: multiple threads (the “family members” in a program) need the same resource (the “bathroom”), but a lock only lets one thread access that resource at a time. The result is a wait line in your software – threads blocked, CPU cores idle, and performance suffering.

This article breaks down what lock contention means, why locks exist, how contention shows up in real programs (with examples in Java and Python on Linux), and how to diagnose and reduce these bottlenecks. We’ll use simple analogies and code snippets to make it beginner-friendly, and cover strategies from using finer-grained locks to completely lock-free approaches.
What is locking contention?
Lock contention occurs when multiple threads are trying to acquire the same lock simultaneously, but only one can succeed at a time1. It’s essentially a traffic jam at the lock. Using our one-bathroom analogy: a lock is like the bathroom door. Only one person can lock the door and use the bathroom, while others must wait outside. If five people need the bathroom at 8 AM, contention is high – four of them are stuck waiting. In software terms, when a mutex or lock is highly contended, threads line up waiting, unable to proceed until they get the lock.
In more formal terms, “contention on a lock occurs when multiple threads try to acquire the lock at the same time”. High contention means many threads are competing, low contention means few threads are. All those waiting threads are essentially doing nothing useful – they’re paused. Only one thread can hold a given lock, and all others attempting to use that locked resource must block (pause) until the lock is released. This is like having a single-key restroom: everyone else loiters in the hallway (wasting time) until it’s free.
Why is this a problem? While threads are blocked, your CPU cores might sit idle even if there’s plenty of other work to do. In the extreme, if contention is very high, your multi-core system could behave as if it’s single-threaded, because threads spend most of their time waiting instead of running. It’s an inefficient use of resources – akin to having a multi-lane highway where all cars are forced into one toll booth lane.
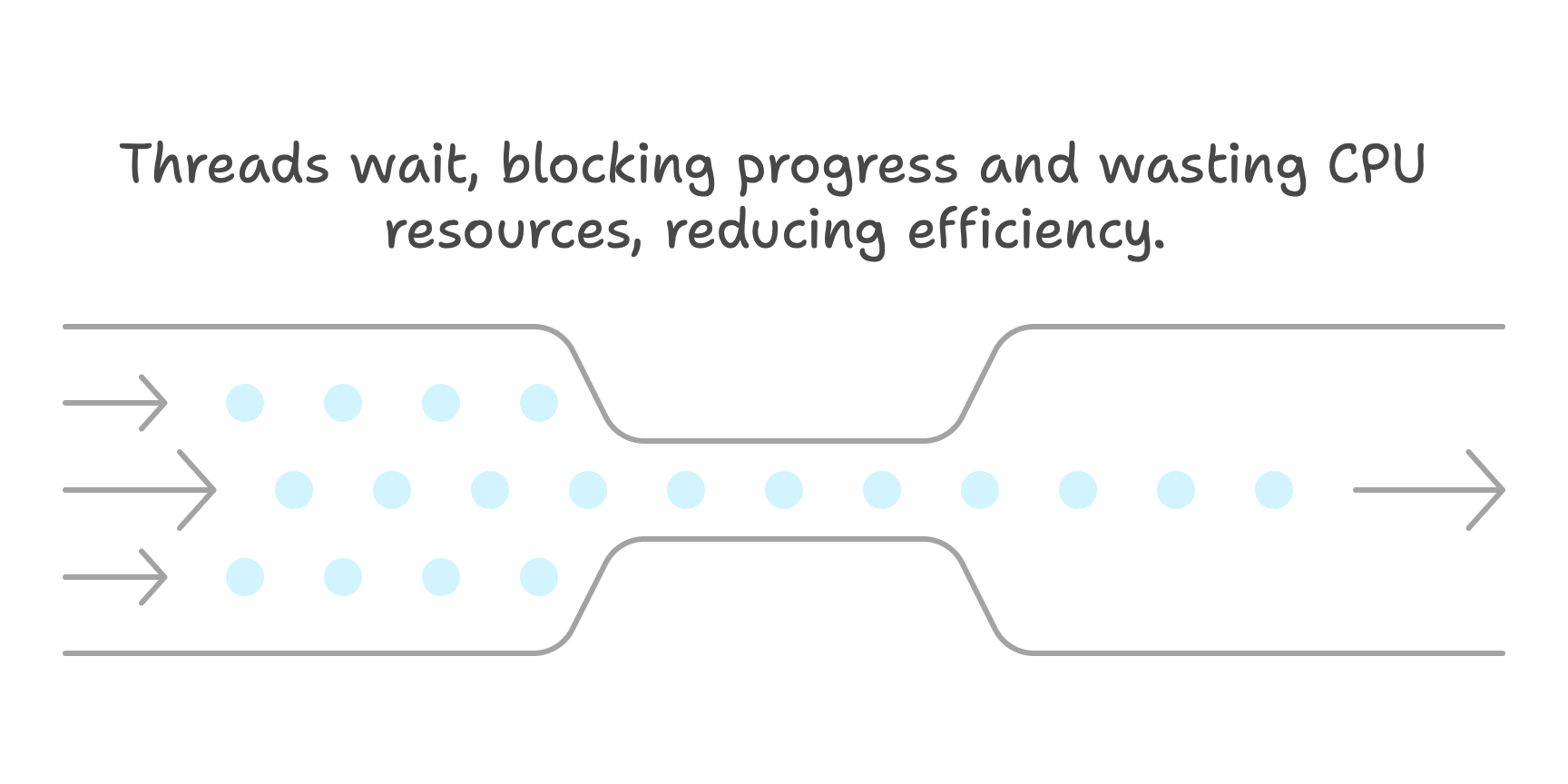
To measure contention, we consider two main factors:
How often the lock is requested - If everyone needs the bathroom frequently, contention rises.
How long the lock is held each time - If each person stays in the bathroom for a long time, others wait longer.

High frequency or long hold duration both increase contention. We’ll revisit these factors when discussing how to reduce contention.
Why do we need locks at all?
If locks cause waiting, why use them? The short answer is data safety and consistency. In a multi-threaded program, threads often share data or resources. Without coordination, they can interfere with each other – leading to race conditions (bugs where the outcome depends on unpredictable timing). Locks (also known as mutexes or monitors) are a fundamental tool to prevent such conflicts by ensuring one thread accesses a critical section at a time.
Think of a shared bank account: two ATM withdrawals at the same time could each read the same balance and allow overdraw if not synchronized. A lock around the withdrawal operation will make the transactions happen one after the other (serially), preserving a correct balance. In programming, a lock is like hanging an “Occupied” sign on a resource – others must wait until the sign is removed.
Under the hood, locks are often implemented by the operating system or language runtime. For example, in Java every object can act as a lock (via the synchronized keyword, using the object’s monitor). Only one thread can own an object’s monitor at a time; any other thread that tries to enter a synchronized block on that object will wait in a queue for the monitor2 . In our analogy, the bathroom’s door lock ensures exclusive use: one thread “locks the door” when entering a synchronized section, and unlocks (releases) when exiting, so others can then enter.
Locks exist to protect critical sections – pieces of code that access shared data – so that only one thread can execute that section at a time, preventing chaos. They are crucial for correctness. However, they introduce the side effect of waiting: if threads frequently need the same lock, they contend.

A real-world metaphor: consider a helpdesk counter with one staff (shared resource) and a queue of people (threads). The counter ensures one person is served at a time (safety), but if it’s busy, others line up (contention). If requests are quick, the line moves fast (low contention). If each request takes a while, the line grows (high contention).
Thus, locks solve one problem (safety) at the cost of potential slowdowns if overused or if too many threads pile up. The key is to balance safety with performance – use locks when needed, but try to minimize the wait line. Next, let’s see how this waiting manifests in actual programs.

How lock contention manifests in practice
When lock contention occurs in a program, you’ll typically observe threads that are blocked or waiting for significant time. This can show up as reduced concurrency (threads not utilizing CPU cores fully) and longer execution times. Let’s look at how this appears in both Java and Python scenarios on a Linux system.
Java example (threads blocking on a lock)
Suppose we have a Java web application where multiple threads handle incoming requests. They all need to write to a shared log file. To avoid garbled logs, you protect the logging operation with a single global lock (e.g., using a synchronized method). Now, if 50 threads are active and many try to log around the same time, 49 threads may be blocked waiting while one thread holds the log lock. In a thread dump (a snapshot of all threads’ states), you would literally see many threads in the BLOCKED state, often with a stack trace indicating they are “waiting to acquire” a monitor or lock that another thread owns. This is lock contention in action – threads paused, unable to proceed until the lock is free. To illustrate, consider this simplified Java code snippet:
class Logger {
public synchronized void log(String message) {
// Only one thread can execute here at a time
System.out.println(message);
// (imagine more complex I/O here)
}
}If many threads call Logger.log() concurrently, the synchronized keyword forces them to take turns. The JVM ensures only one thread is in the log() method at once. Other threads will pause at the method entry until the lock is released. Those waiting threads are effectively idle (not doing useful work) during that wait. In a monitoring tool like VisualVM or JConsole, you would see threads marked as “Blocked on monitor” or similar, indicating they’re contending on a lock. A Java flight recording could show JavaMonitorWait events – which record how long threads spent waiting for locks – highlighting which lock caused the most contention.3

In multithreaded programs, threads can be in various states. The diagram above shows a simplified thread state model (e.g., for Java). When a thread is BLOCKED, it means it’s waiting for a lock held by another thread to be released. This is exactly what happens during lock contention: one thread holds a lock (is inside the critical section) and others are blocked outside, queued until they can acquire that same lock. Many blocked threads imply a high degree of contention and a potential performance bottleneck.
Python example (thread contention and the GIL)
Python threads can also experience contention, though Python’s situation is unique due to the Global Interpreter Lock (GIL). The GIL is essentially a global lock that allows only one thread to execute Python bytecode at a time4. This means even on a multi-core system, only one Python thread runs Python code concurrently (extension libraries or I/O operations can run in parallel, but CPU-bound Python code cannot). In effect, all threads contend for the GIL. If you create, say, 10 threads to do CPU-intensive work in Python, they will spend a lot of time waiting for the GIL – only one thread gets to run, then the GIL switches to another, etc. This is a form of lock contention baked into the language. The result is that pure Python threads don’t speed up CPU-heavy tasks linearly with core count; they often run as if on a single core because of this serialization.
Note: There is ongoing work to remove or make the GIL optional in future Python versions, precisely to alleviate this contention.
Apart from the GIL, Python programs can also have user-defined locks (via threading.Lock or other synchronization primitives) that cause contention. For example:
import threading
lock = threading.Lock()
shared_counter = 0
def increment_counter():
global shared_counter
for i in range(1000000):
# Only one thread at a time can execute this block
with lock:
shared_counter += 1
# Create two threads that both increment the counter
t1 = threading.Thread(target=increment_counter)
t2 = threading.Thread(target=increment_counter)
t1.start(); t2.start()
t1.join(); t2.join()
print("Final counter value:", shared_counter)In this Python snippet, we use a lock to avoid race conditions when incrementing shared_counter. Two threads run the increment_counter function. The lock ensures one thread increments at a time. However, this also means one thread will often be waiting while the other holds the lock. By the end, shared_counter will correctly equal 2,000,000, but the threads spent a lot of time blocking each other. If you profile this with Python’s cProfile, you’d find the program doesn’t run much faster (if at all) than a single-threaded version – a clear sign that the threads were contending on the lock and effectively taking turns. In a logging scenario similar to Java, if multiple Python threads try to write to a file and use a Lock to synchronize, you’d observe threads paused in the lock.acquire() call. Tools like trace logs or even just adding print statements can show threads waiting for locks (e.g., logging when a thread starts waiting and when it acquires the lock).
Summary of symptoms
In both Java and Python, lock contention manifests as threads spending time waiting rather than doing work. This can lead to lower CPU utilization (threads are idle when blocked) and longer execution or response times. If you see a lot of threads in “blocked/waiting” states in a debugger, profiler, or thread dump, it’s a red flag for lock contention.
Next, we’ll discuss how to confirm that and which tools can help pinpoint such issues.
Identifying lock contention problems
How can you tell if your application’s slowness is due to lock contention? There are a few approaches and tools.
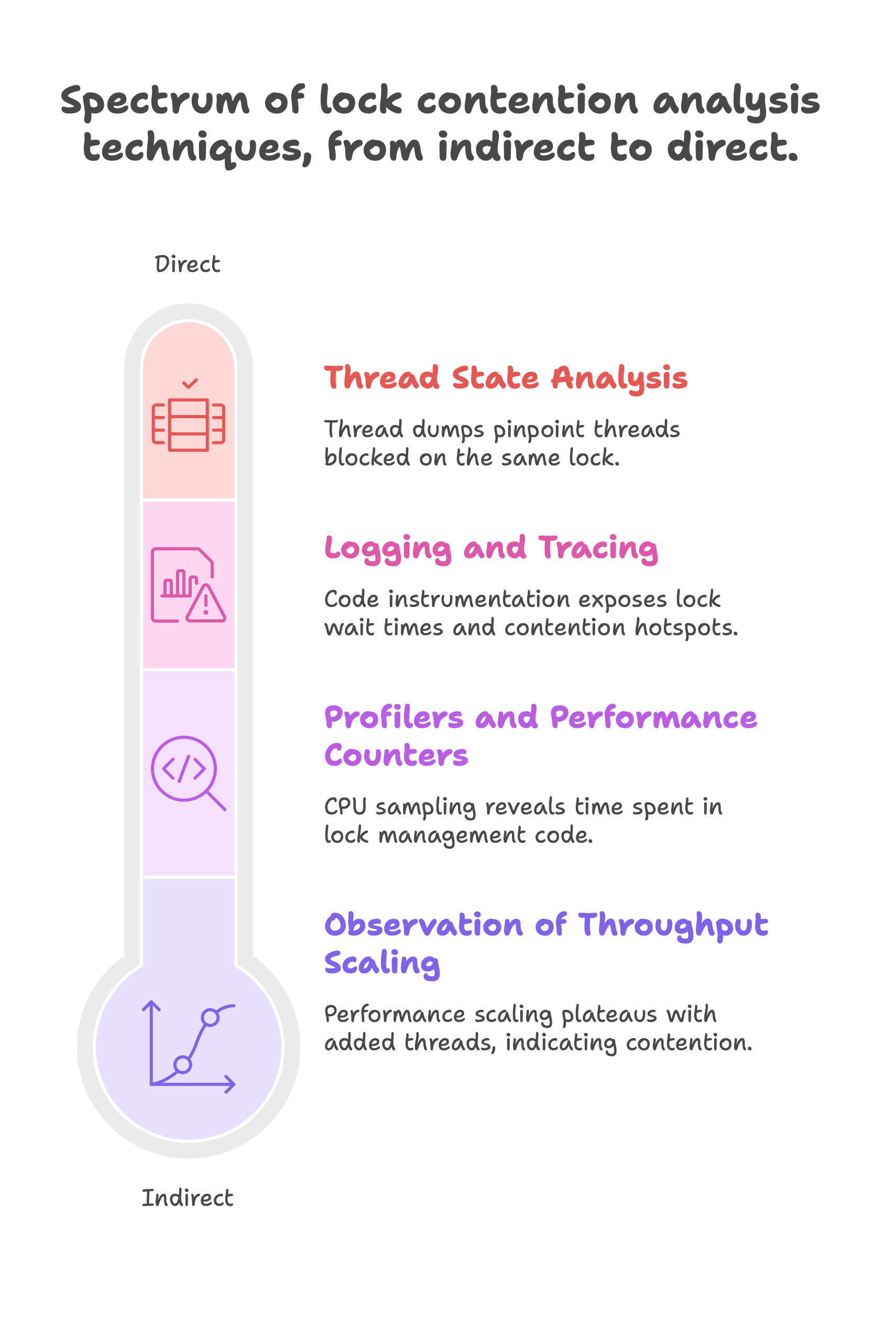
Thread State Analysis. As mentioned, examining thread states is very telling. In Java, you can take a thread dump (using jstack or tools like VisualVM, JDK Mission Control, etc.) to see what each thread is doing. If many threads are in BLOCKED or in a “waiting on monitor” state, and the stack trace points to the same lock or synchronized block, you have contention on that lock. For example, a thread dump might show several threads all waiting to enter Logger.log() (as per our earlier example), indicating they’re contending for that lock. Java’s JDK Flight Recorder (JFR) is even more direct: it has events like JavaMonitorWait that measure how long threads waited for locks. By analyzing a recording, you can “look at the locks that are contended the most and the stack trace of the threads waiting to acquire the lock”. This highlights where the bottleneck is. Java profilers (like VisualVM, YourKit, etc.) often have a view for “synchronization” or “monitors” which can show you which lock objects had the most contention (e.g., how much total thread waiting time was spent on each lock).
Logging and Tracing. Instrumenting your code can help. In Java, you can enable lock contention monitoring via ThreadMXBean (by turning on thread contention monitoring) to get metrics for how long threads wait on locks. You might log warnings if an operation waited too long for a lock. In Python, since explicit lock usage is in your control, you could add logging around lock acquisitions. For instance, logging when a thread starts waiting for a lock and when it acquires it, along with thread IDs, can reveal contention hotspots in logs (e.g., if you see “Thread-2 waited 500ms for lock X”). Python doesn’t have a built-in contention profiler, but high-level profiling can indicate that multi-threading isn’t yielding expected speedups, which often hints at a contention or GIL issue.
Profilers and Performance Counters. Aside from thread dumps, profilers can sometimes show symptoms. In Java, CPU sampling might show a lot of time in methods like Unsafe.park or inside lock management code, which suggests threads are often parked (waiting). In .NET (just as an analogy), profilers even surface “lock contention” events; similarly, in Java, JFR or the Async Profiler can capture lock contention events. On Linux at the OS level, tools like perf or strace can catch futex calls (the underlying syscalls for locks) – frequent futex waits indicate contention. These are advanced techniques, but they exist.
Observation of Throughput Scaling. Another indirect method is observing how performance scales with added threads. If doubling the number of worker threads or CPUs does not improve throughput (and especially if it makes it worse), contention could be the culprit. For example, if 1 thread handles 1000 operations/sec, 2 threads handle ~1800 ops/sec, and 4 threads still handle ~1800 ops/sec (or less), something is bottlenecking – often a contended lock or resource.
In summary, identifying lock contention often involves detecting that threads spend time waiting for locks. Tools like Java’s VisualVM/JFR and Python’s profilers or custom logging can help confirm this. Once you’ve identified a contention problem, the next step is to address it. We don’t want a one-bathroom situation if we can avoid it. So how can we reduce or eliminate lock contention? Let’s explore strategies for that.
Strategies to reduce or eliminate lock contention
When you discover that lock contention is slowing down your program, there are several strategies to alleviate the issue. The goal is either to reduce how often threads need to wait or to remove the waiting entirely by changing the synchronization approach. We’ll cover a few key strategies and use our analogies to make them clear:
Use finer-grained locks
One common mistake is using a single “big lock” to guard too much. For example, locking an entire large data structure when maybe threads could safely work on independent parts of it in parallel. Finer-grained locking means using multiple locks for different chunks of data, rather than one lock for everything. It’s like adding more bathrooms in our household analogy – if you have three bathrooms for five people, contention (waiting time) drops dramatically, because three people can be served at once.
In practice, this might mean:
Instead of one lock for a whole array or list, use a lock per element or per section of the array. Then threads accessing different sections won’t block each other. This technique is often called lock striping. For instance, Java’s
ConcurrentHashMap(in Java 7 and earlier) used a fixed number of lock segments internally, so that threads operating on different buckets could proceed in parallel with less interference.If you have an object with multiple independent sub-resources, give each its own lock.
The general advice is “use different locks for different data whenever possible”.5 Don’t lock more than you need to. By protecting smaller portions of data with separate locks, you reduce the scope of contention – threads only contend with others that need that same piece of data. Returning to analogy: one key per bathroom, not one key for the entire house. This significantly cuts down waiting.
Example: Suppose you manage a list of user sessions and you occasionally clean up expired sessions. If you use one global lock for all sessions during cleanup, all request threads might block during a cleanup cycle. But if you partition sessions into, say, N buckets each with its own lock, a cleanup in bucket 1 won’t stall operations in bucket 2..N. Thus, fewer threads collide on the same lock.
Be cautious that finer locks means more complexity – you must ensure that the right locks are acquired for the right operations and avoid introducing deadlocks (which can happen if threads need multiple locks and acquire them in inconsistent orders). But used wisely, finer-grained locks can drastically reduce contention by localizing the locking.
Reduce lock duration
This strategy is about spending less time holding the lock. Even if threads must use the same lock, if each holds it for a very brief period, the odds of others waiting are lower or the wait time is shorter. Continuing our analogy: encourage shorter bathroom trips – get in, do your business, and get out quickly, so the next person can enter. In code, that means design your critical sections to be as fast as possible:
Do less inside the lock. Move any lengthy computation or I/O outside the locked region if it doesn’t need to be inside. For example, build a log message string or read an input file before acquiring the lock, then just write the result while in the lock. The lock should ideally only be held for the minimal actions that truly require exclusive access. One guidance is “get rid of expensive calculations while in locks” – this includes avoiding network calls, disk I/O, or heavy loops while holding a lock.
Use local copies: Sometimes you can copy a shared structure (or the part you need) under lock, then release the lock and work on the copy. This way the lock is held briefly. For instance, iterate over a snapshot rather than holding the lock throughout iteration. (This may trade memory for time.)
Release ASAP: Don’t hold the lock across calls that might block. For example, acquiring a lock and then waiting/sleeping is asking for trouble – it holds up everyone else. If you must wait, better to release the lock before waiting (or reconsider design).
By reducing lock duration, you convert what could be a long single-occupancy to a quick in-and-out. Even if many threads need the lock, each waits less because the holder releases quickly. This can greatly improve throughput in high contention scenarios. It’s like how an efficient service counter gets the line moving faster.
One caution: in some cases, making a critical section too small can increase overhead if a thread then has to reacquire the lock repeatedly. So there’s a balance. But generally, aim to minimize work inside synchronized sections. A real-world example: in a server, you might lock just to increment a counter or update a shared map, and not to perform the entire request processing.
Replace locks with atomic operations
For certain simple operations, you might not need a full lock at all – an atomic operation can do the job without forcing other threads to wait. Atomic operations are low-level operations (often CPU instructions like compare-and-swap) that complete in one step atomically, meaning no other thread can see a half-finished result. They effectively behave like a tiny lock that’s built into hardware, but they don’t put threads to sleep – they don’t use traditional locking at all6.
A classic example is incrementing a counter. Many languages provide an atomic increment (e.g., C++ std::atomic, Java AtomicInteger.incrementAndGet()). Using that, threads can update a shared counter without a mutex. Under the hood, if two threads try to increment at the same time, one will succeed and the other will retry, but this all happens very fast at the CPU level. The threads don’t get parked; they busy-wait a tiny bit in hardware if needed. As an answer on Stack Overflow explains, “atomic operations leverage processor support (compare and swap instructions) and don't use locks at all”. Because they avoid the overhead of kernel-level locks and context switches, they can be much faster for simple tasks – especially when contention is low to moderate.
Using atomic operations is like having a magic self-checkout for a specific task – you don’t wait for a cashier (lock), you just complete your item scan in one go. But this only works for tasks that can be done in one atomic step or a small set of atomic steps.
Examples:
Instead of using a lock to protect an integer counter, use an
AtomicInteger(Java) or similar atomic type. Then increments and reads can happen from multiple threads without locking. (Java’sLongAdderis another example, optimized to reduce contention on counters by maintaining several sub-counters under the hood.)In Python, there’s no built-in atomic integer for threads (and the GIL makes certain operations atomic by default), but if you were using shared memory across processes or low-level atomics via libraries, the concept would be similar. (With the GIL present, a simple
x += 1is actually atomic at the bytecode level for Python threads, but that’s a special case of the GIL’s locking – once GIL removal efforts land, we might see more explicit atomic types for Python as well.)
It’s important to note that atomic operations work best for simple shared data manipulations (set a value, add a number, swap a pointer, etc.). They don’t scale to complex multi-step operations easily – for those you either need locks or more complex lock-free algorithms. However, whenever you find you are using a lock just to update a simple value, consider if an atomic can replace that. It removes the need for threads to block at all for that operation, which is a big win.
Use concurrent data structures
Many programming platforms offer concurrent collections/data structures that internally manage synchronization in an optimized way, often avoiding conventional locking or minimizing contention through clever techniques. Using these can save you from reinventing the wheel and often yields better performance than naive locking around a standard structure.
For instance:
Java’s
ConcurrentHashMap,ConcurrentLinkedQueue,CopyOnWriteArrayList, and others injava.util.concurrentare designed for multi-threaded use. AConcurrentHashMapallows concurrent reads and updates from multiple threads without a global lock on the whole map (it uses internal segment locks or other non-blocking algorithms under the hood). This means threads are far less likely to block each other compared to using a singleHashMapwith a synchronized block. If you find yourself locking around a normalArrayListorHashMap, it might be as simple as switching to a concurrent version to reduce contention.In Python, the standard library provides some thread-safe structures like
queue.Queue(for producer-consumer queues) which internally handles locks for you, and various classes inmultiprocessingfor sharing data across processes safely. While Python’s built-in data types aren’t explicitly “concurrent” (due to the GIL some operations are thread-safe but you shouldn’t rely on that), using higher-level concurrency primitives (like queues or specialized libraries) can help structure your program to avoid manual locks. For example, instead of multiple threads writing to a list with a lock, you might use aqueue.Queueand have threads put items into the queue, and one consumer thread take from it. The queue internally does locking but very efficiently and spares your threads from all contending on one lock at once.Other languages have similar offerings (C# has concurrent collections, C++ has some lock-free containers or you can use Intel TBB, etc.).
The benefit is these concurrent data structures are often built using a mix of fine-grained locks, atomic operations, and other tricks to maximize parallelism. As one article suggests, “use a data structure that uses [atomic operations] internally – a lock-free message queue for example”. You get the advantage of less contention without having to implement it all yourself.
To put it simply: don’t always reach for a manual lock for common patterns – check if a concurrent library structure can do the job. They are usually battle-tested for performance under contention. Using these can eliminate the big lock you might otherwise use, thus cutting down contention dramatically.
Apply lock-free or wait-free algorithms
This is a more advanced strategy: redesign parts of your program to use lock-free or wait-free algorithms. These are methods of synchronization that, instead of using locks, rely on atomic operations and careful algorithm design so that threads do not block one another even when working on shared data. The idea is every thread can make progress independently, and at worst they might retry operations (in lock-free) but never get stuck waiting for a lock.
Using a lock-free approach is like removing the bathroom door lock completely and designing the bathroom in such a way that multiple people can use it simultaneously without interfering – admittedly a strange bathroom, but in computing it can be done for certain problems! For example, a lock-free stack or queue allows multiple threads to push and pop without a mutex; they use atomic pointer swaps (CAS operations) to coordinate. If a conflict occurs (two threads try to push at once), one will succeed and the other will simply try again – but crucially, they don’t have to wait in line, they keep attempting until successful.
The major advantage is that you avoid the waiting altogether, so contention as we know it is basically eliminated. Lock-free data structures “allow multiple threads to access shared resources without locking. By relying on atomic operations, lock-free structures minimize contention and eliminate the risks of deadlocks, enabling systems to scale better under high concurrency”.7 In other words, no thread is ever put to sleep holding a resource – everyone is racing forward, occasionally colliding and retrying, but never parked.
There’s also the term wait-free, which is even stronger: it guarantees every operation completes in a bounded number of steps, so every thread makes progress regardless of what others do. (Lock-free guarantees global progress but a particular thread could starve in theory; wait-free guarantees per-thread progress.)
However – and this is important for beginners – lock-free algorithms are not trivial to implement correctly. They can be very complex and error-prone, involving tricky atomic operations and memory ordering issues. As Preshing on Programming notes, “lock-free programming is extremely challenging, but delivers huge performance gains in a lot of real-world scenarios”.8 So while the performance appeal is high, one should weigh the complexity. Often, using a provided concurrent data structure (previous strategy) is a way to get lock-free benefits without writing it yourself.
Example use cases: Many high-performance libraries (like concurrent queues, stacks, ring buffers, etc.) are lock-free. Another example is something like a read-copy-update (RCU) mechanism or using immutable data structures that avoid locks by design (if data never changes, you don’t need locks to read it — you make new copies on writes, etc.). The actor model (as used in Erlang or Akka) avoids locks by isolating state and communicating via messages. These aren’t lock-free in the atomic CAS sense, but achieve the same goal: no multi-thread contention on shared data because there is no shared mutable data; it’s handled by message passing.
For a practical beginner-friendly scenario: if you have a very hot counter or timestamp that many threads need, instead of locking it or even using an atomic (which can become contended at extremely high frequency), you might use a lock-free approach like having each thread update a different slot (reducing contention) and combine results later. Or use an algorithm that employs exponential backoff on contention (which is a strategy where threads back off and wait a tiny random amount before retrying an atomic operation, to reduce constant collisions).

To summarize, lock-free/wait-free approaches remove traditional locks entirely, and thus remove the possibility of threads waiting on locks. They can drastically improve scalability for certain operations under heavy concurrency. But they are complex to implement from scratch – fortunately, as mentioned, many libraries and language runtimes provide them for common use cases, so you can use them without diving into assembly-level programming. This is like having high-tech plumbing that lets five people brush their teeth in the same bathroom at once without bumping into each other – great if you can get it, but not trivial to set up!
Other tips and techniques
Beyond the five primary strategies above, there are a few other practices worth mentioning:
Read-Write Locks: If your scenario is lots of reads and few writes to a resource, a traditional mutex is overkill because readers don’t actually conflict with each other. A reader-writer lock allows multiple threads to read in parallel and only locks exclusively for writes. This can reduce contention when reads are frequent. For example, many threads can concurrently read a configuration if it rarely changes, and only block each other when an update happens. Most platforms provide
ReadWriteLock(Java) or similar. It’s another way to fine-tune locking behavior.Thread-local or Sharded State: Sometimes you can avoid sharing altogether. If each thread can work on its own copy of data for a while (thread-local storage), and only merge results at the end, you eliminate locks in the parallel phase. For instance, if threads are accumulating statistics, let each thread keep its stats and only combine them at the end (which might require a brief lock or just an aggregation step once threads are done).
Reduce Hotspots: Identify if a particular variable or object is a “hotspot” that all threads contended on. Maybe you don’t actually need to update it so often. For example, instead of constantly updating a “global progress counter” that becomes a hotspot, maybe each thread can log progress occasionally or update in batches. Or as one source suggests, reconsider if you need to store a frequently updated value at all (e.g., the size of a list could be computed on demand instead of updated on every modification, to avoid constantly locking on that counter).
Transactional Memory: This is an advanced concept (not widely available in mainstream languages, though languages like Clojure or frameworks like Intel’s Software Transactional Memory have tried it). It allows threads to optimistically execute sections and only roll back if a conflict is detected, rather than using locks. It’s like letting everyone into the bathroom and if two people clash, one steps out and tries again. It’s beyond our scope, but it’s good to know it exists as a research/advanced solution.
Having covered the tactics, let’s cement understanding with a short example of fixing a contention issue.
Case Study: Resolving a lock contention bottleneck
Scenario: A hypothetical e-commerce server is experiencing latency spikes under load. It turns out there’s a single lock protecting a critical section where orders are recorded. Only one order can be processed at a time because of this lock, so when many requests come in, they queue up. The lock was added to prevent two threads from double-selling the last item in stock, but now it’s a scalability killer.
Identification: Using a Java profiler and thread dump, the developers observe many threads in BLOCKED state waiting on the OrderManager lock. The call stacks show they’re all trying to execute OrderManager.processOrder(). This is classic lock contention – the processOrder method is synchronized and becoming a choke point.
Solution Approaches:
Finer-Grained Locking: The team inspects what
processOrder()does. They realize the lock is guarding two things: inventory update and writing to an order log. These could be separated. They decide to use one lock for inventory (stock counts) and a different lock (or a concurrent queue) for logging orders. Immediately, this means an order thread updating inventory won’t block a different thread logging a past order. They also notice that updating inventory for different product categories never conflicts, so they implement a lock-per-product-category. Now threads buying different products don’t block each other at all when updating stock.Reducing Duration: Within each lock section, they trim any extraneous work. The order confirmation email sending, which was mistakenly inside the lock, is moved outside (since sending an email doesn’t need the inventory lock!). Database writes are also done in a way that the lock is held only while calculating the changes, not during the entire DB transaction.
Using Concurrent Structures/Atomics: They replace a simple “orders counter” that was using
synchronizedwith anAtomicInteger. No more blocking on incrementing the orders count. They also use a thread-safe queue for logging orders: instead of each order thread writing to the log file under a lock, they push a log entry into a concurrent queue. A separate background thread handles dequeuing and writing to the file. This removes contention of order threads on the log file completely – they only contend briefly on the queue’s internal lock, which is very optimized and non-blocking most of the time.
Outcome: After these changes, testing shows the server can handle a much higher load. Threads rarely block now – multiple orders for different products process in parallel smoothly. The order throughput scales almost linearly with added threads until another limit is hit. The latency spikes disappear since the long waits on the order lock are gone. Essentially, by splitting one big lock into multiple smaller ones (finer-grained), shortening the work done while holding locks, and leveraging concurrent/lock-free utilities for things like counters and logging, the contention issue was resolved. The “bathroom line” in the server cleared up – now there are multiple “bathrooms” (locks) and the “occupancy” time is short, so wait times are negligible.
Takeaway: This case illustrates a composite solution: often, you will use several strategies in combination to tackle lock contention. Analyze what exactly needs protecting and choose the least contentious way to do it, whether that’s more locks, no locks, or alternative approaches.
Conclusion
Locking contention is like an unseen traffic jam in your software – threads piling up at a chokepoint, leading to poor performance despite available computing power. We started with a simple one-bathroom household analogy to understand contention in intuitive terms: it’s not that the bathroom (lock) is slow, it’s that everyone fighting over one bathroom causes delays. In computing, locks are necessary to maintain correctness in concurrent programs, but when too many threads need the same lock, you get contention which hurts throughput and responsiveness.
We learned how to recognize lock contention by looking at thread states (many threads BLOCKED waiting for a lock) and using tools like profilers, thread dumps, and logging to pinpoint where threads spend time waiting. Once identified, the key is to relieve the bottleneck with thoughtful strategies:
Finer-grained locks: partition the problem so threads don’t all serialize on one lock.
Shorter lock hold times: do less inside critical sections, freeing locks quickly for others.
Atomic operations and lock-free techniques: use low-level atomics for simple tasks to avoid locks altogether.
Concurrent data structures: leverage those “pre-built” solutions that minimize contention internally.
Lock-free algorithms: in critical hotspots, consider a redesign that removes locks, albeit with higher complexity, for maximum scalability.
We also touched on other ideas like read-write locks and avoiding shared state when possible, all with the aim of making threads wait less. By applying these methods (often a combination), you can transform a program with heavy contention into one that scales much better with threads.
In summary, think of designing concurrent code like designing an efficient public facility: provide enough “resources” (locks or lock-free pathways) so that people (threads) rarely have to line up, and make sure when they do use a resource, they do it quickly and get out. Locks are a useful tool to keep things orderly (preventing race condition “collisions”), but we must use them judiciously to avoid turning multi-threaded software into a single-file line. With careful strategy, you can have both safety and performance – ensuring your multi-threaded programs run smoothly even at scale, without everyone stuck waiting at the door.