
Understanding caching: a beginner’s guide
System Design


Caching is a technique where frequently used data is stored in a fast-access layer (like memory) so that future requests can be served quickly without recomputing or refetching the data. This dramatically improves application performance and scalability. For example, instead of running the same expensive database query for every request, a server can cache the result once and reuse it1. As a result, response times drop and the underlying database or service sees much less load. Caching can also boost reliability: if a downstream service or database becomes slow or unavailable, a cache can still serve recently stored responses.
However, remember that the cache is not the primary data store – if the cache is empty or down, the system must still fetch from the original data source.
Caching is ubiquitous in computing: CPU chips have tiny caches to speed memory access, web browsers cache images and scripts, and large-scale services (like AWS or Netflix) rely on caches to deliver millisecond response times under heavy load. In short, caching is a fundamental optimization to reduce latency and duplicate work by keeping “hot” data close at hand.

Types of caching
Caching can happen at different layers. The main types are in-memory (local) caches, distributed caches, and special-purpose caches (like HTTP/CDN caches):
In-Memory (Local) Caching: This stores data in the same machine (or even the same process) as the application, typically in RAM. For example, a Java application might use an
HashMapor Caffeine cache in its own memory. Access is extremely fast because no network calls are needed2. The downside is that the cache is limited by that machine’s memory and isn’t shared: each server has its own copy. Local caches are very easy to implement and great for single-server apps, but they don’t automatically keep data consistent across multiple instances. If you restart the app, the cache is lost. In-memory caches use eviction policies (LRU, LFU, etc.) to manage size, and must be updated or invalidated when the source data changes3.Distributed Caching: A distributed cache runs as a separate service (often on a cluster of servers). Examples include Redis, Memcached, or Apache Ignite. In a distributed cache, cached data is stored across multiple nodes in a network4. This means many application servers can share the same cache, avoiding inconsistency between instances. Distributed caches can scale to handle large volumes of data and offer features like data replication (for fault-tolerance) and partitioning/sharding. The trade-off is that accessing a distributed cache requires a network call, so it has higher latency than a local in-memory lookup. In practice, distributed caches still give low millisecond or sub-millisecond response times (e.g. Redis keeps all data in RAM), but they are always slower than a local memory access. Distributed caches are ideal for cloud or microservices architectures where many servers need a shared fast lookup.
Other Caching Layers: In addition to application memory caches, there are caches closer to the user. Web browsers cache images, scripts, and pages on the client side to speed up page loads. Content Delivery Networks (CDNs) like Cloudflare or Akamai cache static assets (CSS, videos, etc.) at edge servers around the world. Web servers and proxies (e.g. Varnish or Nginx) can act as HTTP caches to serve repeated requests without hitting the backend5. These HTTP/CDN caches are crucial for high-traffic websites, though they operate differently (caching entire HTTP responses or files) than in-memory key-value caches.
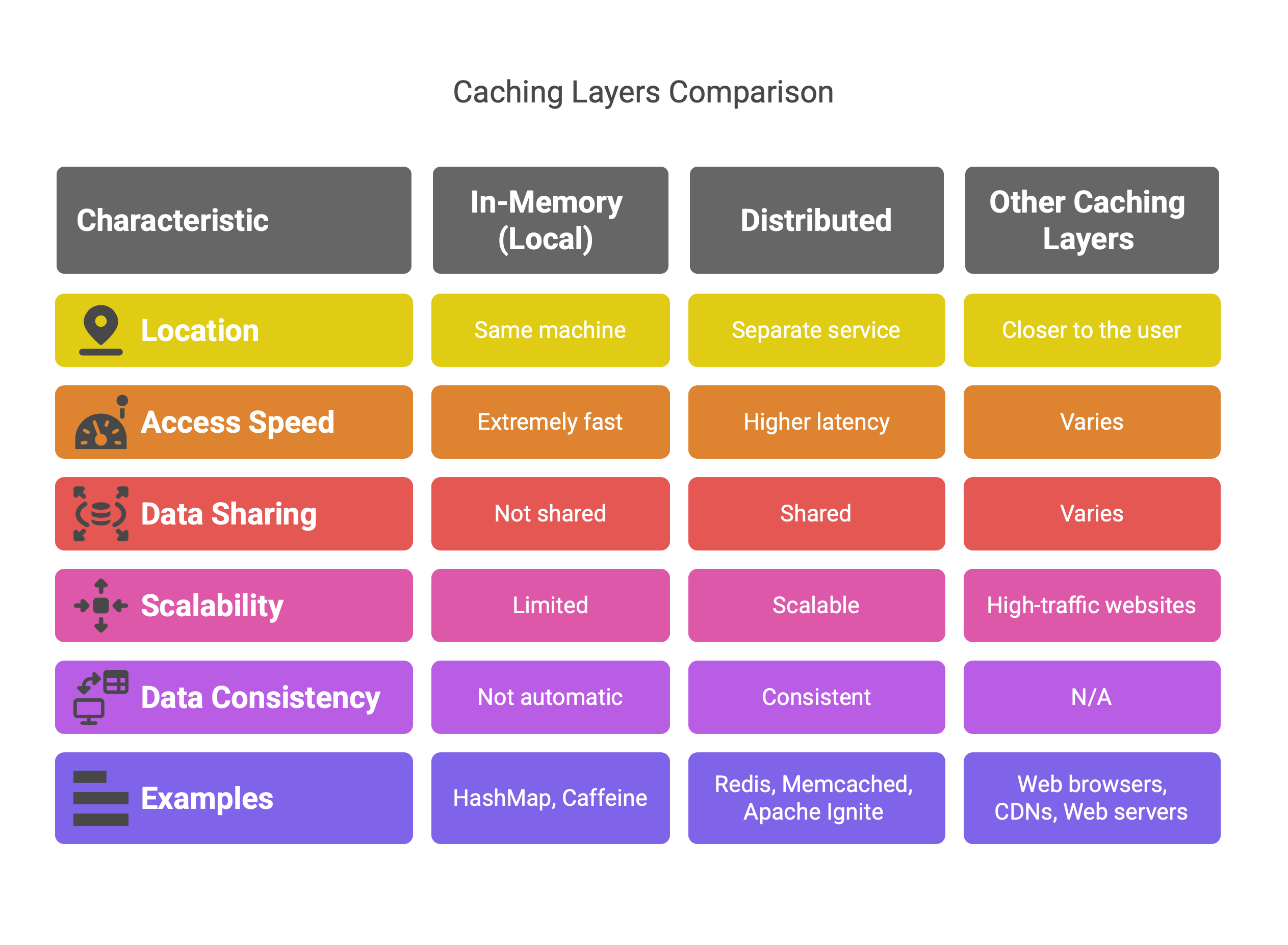
Each caching type serves a purpose: local/in-memory caches give you the fastest possible lookup but are scoped to one machine, while distributed caches sacrifice a bit of speed for much greater scalability and consistency. Often, systems use a combination (e.g. each server has an in-memory cache and they share a Redis cache for heavy data).
Caching strategies
Caching strategies define how and when data is written to or read from the cache relative to the main database. Here are the most common strategies:
Cache-Aside (Lazy Loading): In the cache-aside pattern, the application code explicitly manages the cache. When the app needs data, it first checks the cache. If the data is there (cache hit), it uses it. If not (cache miss), the app fetches from the database, then stores that result in the cache for next time6. In other words, on a miss the application “touches” the database and then populates the cache. This approach is simple and widely used: it keeps frequently accessed data close at hand and is especially good for read-heavy workloads. The downside is that the cache can become slightly stale: if the database is updated, the old value might still sit in cache until the next read forces a refresh.
In practice, you often combine cache-aside with invalidation logic to delete or update cache entries when the source data changes.
Write-Through: With write-through caching, every time the application writes new data, it writes to the cache and immediately writes through to the database. This means the cache and database stay perfectly in sync: any read after a write always sees the latest data. For example, on a write operation the app might first update the Redis cache, then flush that write to the SQL database. The advantage is strong consistency: the cache is always up-to-date with the database7. The trade-off is extra latency on writes, since you’re doing two writes sequentially. Writes become slower, but subsequent reads are fast (since the cache has the fresh data). Write-through is often used when you need guarantees that no reads will see stale data (for instance, critical financial records)8.
Write-Back (Write-Behind): The write-back (also called write-behind) strategy is similar to write-through, but it delays writing to the database. In this approach, the app writes data to the cache immediately, but the cache updates the database asynchronously after a short delay or in batch. This gives much faster write performance (the application thinks “done” as soon as it writes to memory) and can reduce database load by batching writes. It’s useful for write-heavy workloads where you can tolerate a slight lag. The downside is risk: if the cache crashes before flushing, recent writes can be lost. Thus write-back caching needs safeguards (write-ahead logs, replication) to avoid data loss. This strategy is complex and is best when occasional stale data (for a few seconds) is acceptable, or when performance is more critical than absolute currency.
Write-Around: In write-around (often paired with cache-aside or read-through), writes bypass the cache entirely. Instead, data is always written directly to the database, and the cache is only populated on subsequent reads. In effect, the first read after a write will miss the cache and fetch from the DB (and then fill the cache). This avoids “polluting” the cache with data that is written frequently but rarely read. Write-around is most useful when new or updated data is written infrequently read afterward. The trade-off is that the first read is slower, and the cache will not have that data until it’s loaded. But if some data is written once and never touched again, write-around saves memory and keeps the cache focused on hot items.
Refresh-Ahead (Preemptive Refresh): Refresh-ahead is a proactive read strategy. Instead of waiting for a cache entry to expire and then refilling it on demand, the cache system automatically refreshes popular items before they expire. For example, if a cached page has a 60-second TTL and a “refresh factor” of 0.5, the cache will trigger an asynchronous update when the entry’s age reaches 30 seconds, keeping it alive continuously. This minimizes cache misses for very “hot” data (like a trending social media post) at the cost of extra write traffic to the cache. It’s a bit complex to configure (you must decide which items to refresh and when), but it avoids latency spikes that happen if many users try to load an expired item at once.
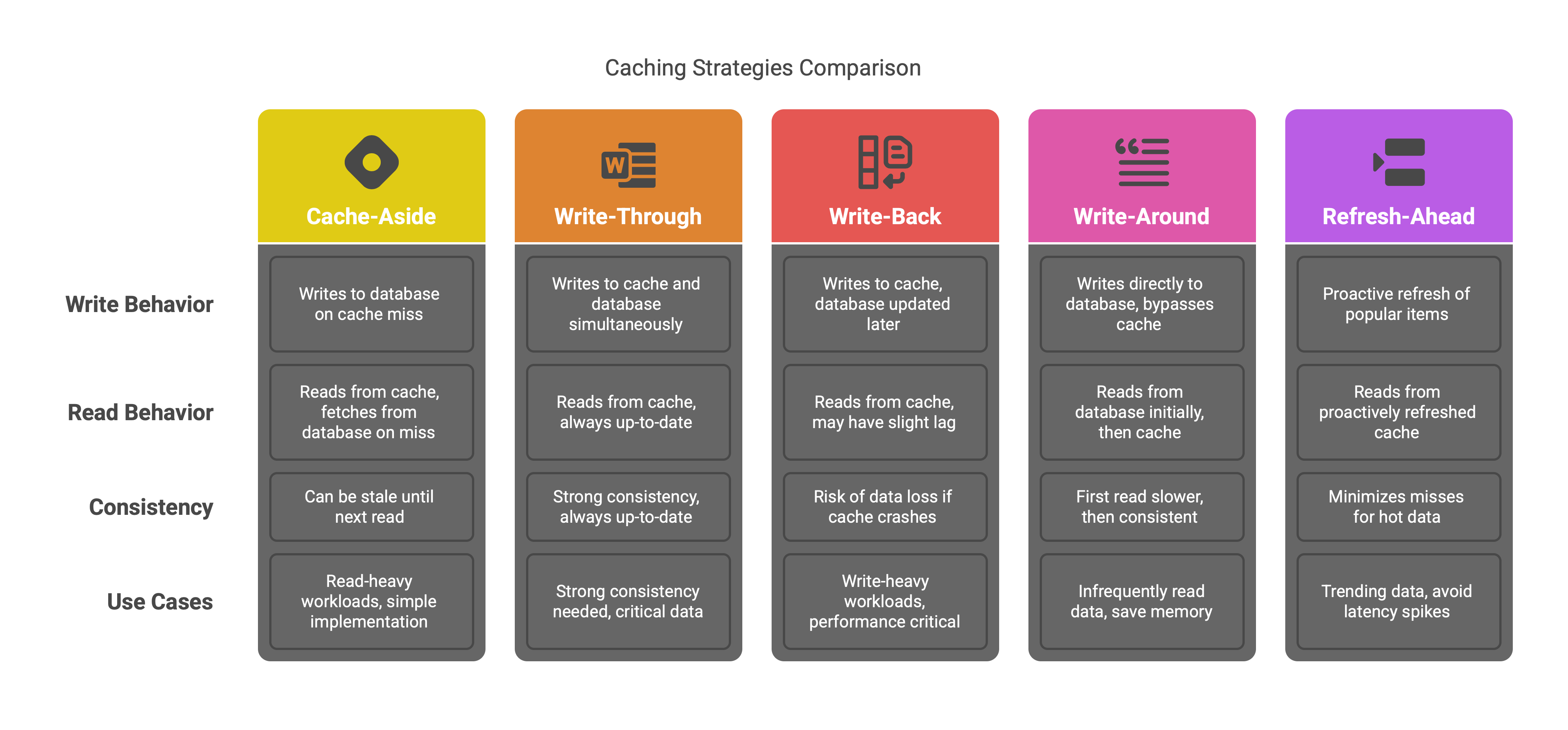
Each strategy has its use-cases. For example, cache-aside (lazy loading) is a good default for many read-heavy applications, because it’s simple and lets the cache organically fill with needed data. Write-through is chosen when data consistency is paramount (e.g., session stores or financial apps). Write-back is chosen for very write-heavy loads when you can afford a small consistency window (and often combined with replication or durability options). Write-around works when writes are much less frequent than reads, to avoid warming the cache with one-off data. And refresh-ahead suits workloads where certain items are so frequently accessed that you want to keep them always “warm” in cache. In practice, engineers often combine strategies (e.g., using write-behind for bulk updates but write-through for critical user actions) to balance speed and consistency.
Real-world analogy
To make these ideas concrete, here are some analogies beginners might relate to - kitchen and pantry. Think of your kitchen counter vs the pantry in the basement. If you know you’ll use spices often, you keep them on the counter (a “cache”) for easy reach. The pantry (like the database) is further away. When you run out, you go downstairs and restock the counter. That’s like cache-aside: you fetch ingredients from the pantry only when needed, and put them in easy reach. If you always write through (like write-through caching), it’s like updating your kitchen recipe book every time you cook and then immediately noting it in the family cookbook (both places) – it’s accurate but takes extra time. Refresh-ahead is like noticing the salt is half-used and refilling it before it runs out, so you never run out at dinner time.
Use cases
Web application example: An e-commerce site might use a distributed cache (e.g. Redis) to store product information and user session data. When customers browse products, the app fetches data from Redis instead of the (slower) database, yielding faster page loads. Similarly, user login sessions can be kept in a Redis cache so that any web server can validate a session quickly. For rarely changing data (e.g. archived product details), a write-around strategy might be used so that infrequent writes don’t crowd out frequently-read items.
Microservices and APIs: In a microservices architecture, different services might share a common cache layer. For instance, a “hotel availability” service could cache search results for popular queries so that the booking service doesn’t have to always recalc availability. If many requests target the same data, refresh-ahead could keep those results from expiring during peak times. If a user places an order (a write operation), a write-through cache would ensure the cache and database reflect that purchase simultaneously, avoiding race conditions.
Social media / News feeds: Trending posts or news stories that get thousands of views per minute are perfect for refresh-ahead. Rather than let the cache entry expire (causing a slow database fetch that might under-serve some users), the system proactively refreshes the cache entry while it’s still in heavy use. If a post’s TTL is 60 seconds and it’s being read frequently, the cache might auto-refresh when the TTL hits 30s, so users always see cached data with minimal delay.
These examples show when to use each method. In general, if reads dominate and data changes infrequently, cache-aside or write-around works well. If data needs strong freshness, write-through (or even no caching) might be best. If writes are intense but you want some caching benefits, write-back can help. Thinking in terms of everyday analogies (kitchen items, library books, etc.) can also help beginners internalize the trade-offs.
Comparing Strategies
Below is a simplified comparison of caching strategies. It highlights how each approach affects reads, writes, data freshness, and complexity. (This is a guideline – exact behavior can vary by implementation.)
Each column summarizes the trade-offs. For example, write-through has good data freshness (cache always in sync) but higher write latency because every write hits two stores. Write-back has fast writes but weaker fault tolerance (if the cache fails, recent data can be lost). Cache-aside is very simple and works well for read-heavy loads, but you must handle cache misses manually. Refresh-ahead is a special case that proactively updates “hot” cache entries (often used in CDNs or in-memory caches with TTLs) to avoid expensive misses.
Common Caching Tools and Libraries
Many libraries and systems help implement caching. Some popular ones are:
Redis: An open-source, in-memory key-value store. Redis supports many data types (strings, lists, hashes, etc.) and is often used as a distributed cache. It’s extremely fast and handles millions of operations per second. Redis can be used for simple key-value caching, session stores, leaderboards, and more. It can also persist data to disk if needed, but its main strength is pure RAM speed.
Memcached: A simple distributed memory object caching system. Memcached is very lightweight and fast. It stores data in memory across multiple nodes and is often used to cache database query results or API responses. Unlike Redis, Memcached only supports basic string values (no advanced data structures), but this simplicity yields very predictable performance. Memcached does not persist data to disk and has no built-in replication, so it’s usually used where temporary cache is okay.
Ehcache: A widely used Java-based cache library. Ehcache stores objects in local JVM memory (and can overflow to disk) and integrates easily with Java applications or frameworks (like Spring). It provides many features like expiration policies, eviction strategies, and even a distributed mode. Ehcache is designed to be fast and scalable for large Java apps.
In-process caches: Many languages have lightweight caching libraries. For example, Caffeine or Guava in Java, or
lru_cachedecorators in Python. These are local (in-memory) caches optimized for the language runtime.HTTP/CDN caches: Tools like Varnish (an HTTP accelerator) or the caching features of Nginx/Apache serve web content very quickly. They are not key-value stores but cache entire HTTP responses or files. CDNs (Content Delivery Networks) also act as distributed caches for static assets on the internet.
Other distributed caches: Systems like Apache Ignite or Hazelcast offer in-memory data grids for extremely high performance caching, often with additional compute features. These are used in large-scale enterprise systems.
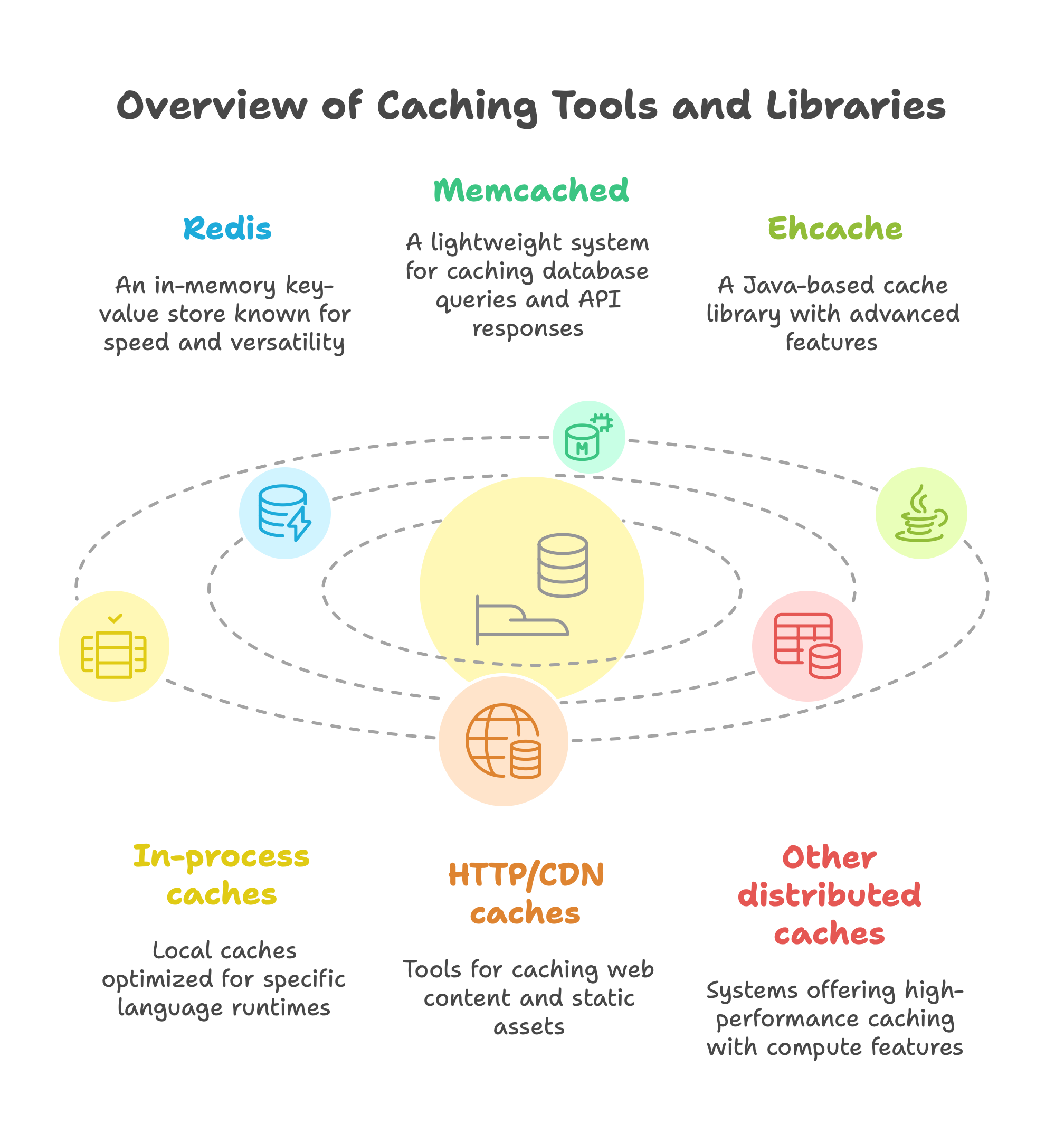
When choosing a caching tool, consider language support, data structures needed, scaling model (cluster vs local), and whether persistence or advanced features are required. For most web apps, Redis and Memcached are go-to choices.
Best practices and pitfalls
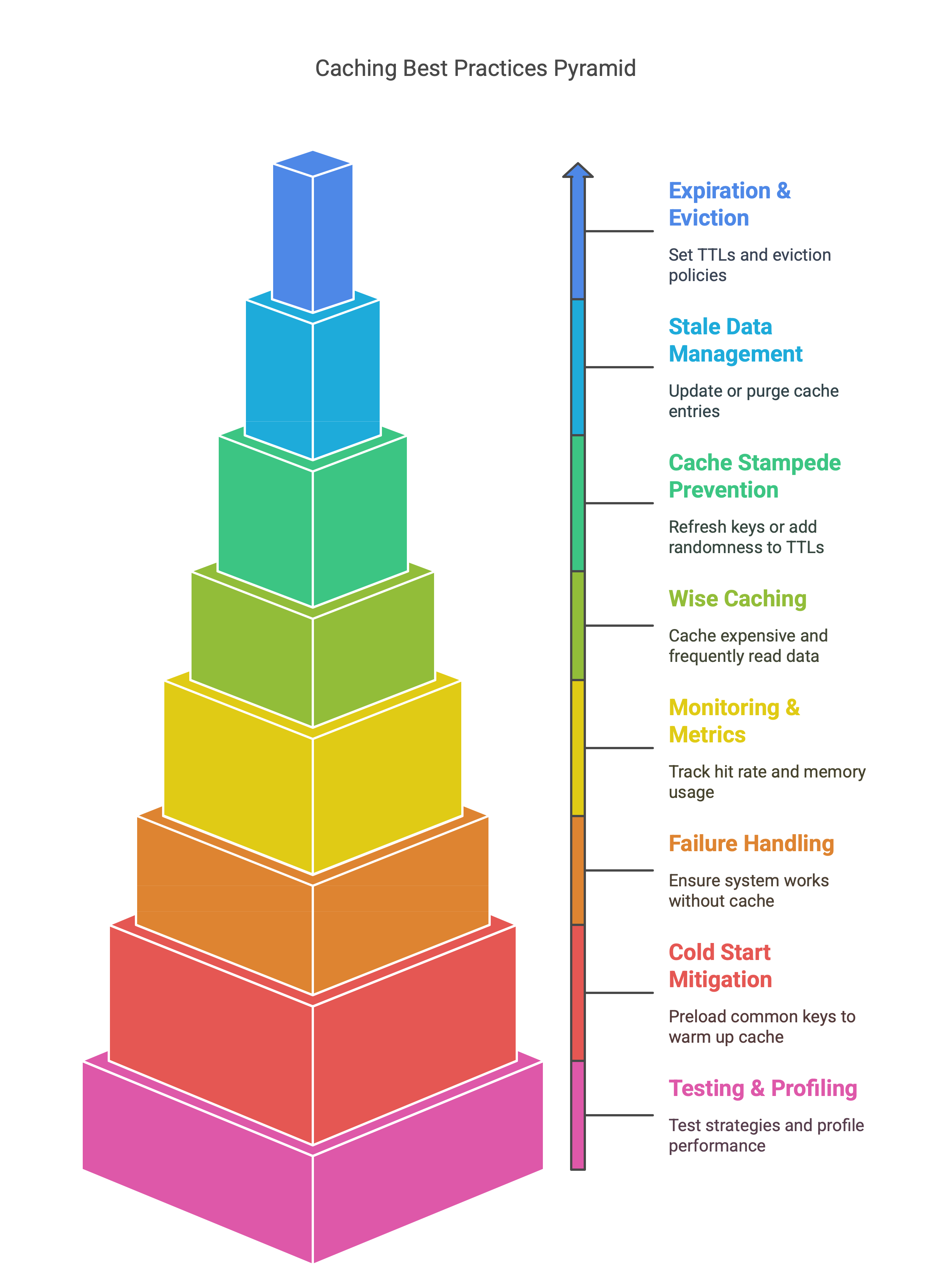
Implementing caching can greatly improve performance, but there are common pitfalls. Keep these best practices in mind:
Set appropriate expiration (TTL) and eviction policies: Always configure how long data should live in the cache. Without TTLs or eviction, caches can grow out of control or serve stale data9. Use policies like LRU (least-recently-used) or LFU to evict old entries. For dynamic content, consider “cache busting” (invalidating entries when data changes).
Be careful with stale data: Cached data can become outdated. Since “cache invalidation” is notoriously one of the hardest problems in CS10, plan carefully how you will update or purge cache entries when the source data changes. For example, after an update to the database, you might delete the affected cache key (cache-aside) or let the short TTL expire. Without this, users might see old values.
Prevent cache stampedes (thundering herd): If a popular item expires and many clients request it at once, all those requests might hit the database simultaneously. Mitigate this by techniques like refreshing popular keys before they expire, adding randomness to TTLs, or using locking/mutex so only one request repopulates the cache. The “refresh-ahead” strategy is one way to avoid stampedes.
Cache wisely – don’t over-cache: Only cache data that is expensive to compute or fetch and read frequently. Caching every database row or API call can waste memory and add complexity. Focus on “hot” items. Over-reliance on caching can also hide bugs – always make sure your application correctly handles cache misses and fallbacks.
Monitor cache metrics: Track cache hit rate, memory usage, and eviction counts. If the hit rate is low, the cache may not be useful; if memory is full, consider raising limits or adding nodes. Monitoring helps you detect issues like memory leaks (unbounded growth) or unusually high misses.
Handle failure gracefully: The application must work even if the cache is down (fallback to the database). Design your system so the cache is an optimization layer, not a single point of failure. For write-behind caches, ensure that unflushed writes are not lost (use persistence or replication).
Beware of cold starts: A fresh cache (e.g. after deployment or restart) will be empty and incur a surge of database reads. You can “warm up” the cache by preloading common keys. Otherwise, expect some initial slowness after start-up.
Test and profile: Caching can introduce subtle bugs (stale reads, race conditions). Start with simple strategies and test thoroughly. Use profiling tools or counters (cache hits vs misses) to verify that caching is actually improving performance.
By following these practices, you’ll get the most benefit from caching while avoiding common issues like stale data, excessive memory use, or race conditions. Remember Martin Fowler’s words: cache invalidation is hard, so invest effort in cache design and clearly define when data should expire or be refreshed.
Invite a friend & score a $50 voucher! 🎉

Together, we’ve built an incredible community, and now… it’s time to grow it even bigger!
Summary
Caching is a powerful technique that bridges the gap between speed and scalability in modern applications. By understanding different caching methodologies - from simple in-memory caches to distributed systems and advanced strategies like write-back and refresh-ahead - developers can choose the right approach for their use case. While caching offers significant performance gains, it comes with trade-offs: complexity, potential data staleness, and the ever-challenging problem of invalidation. Start with clear goals, keep it simple where possible, and evolve your strategy as your system grows.
With the right mindset, caching transforms from a performance hack into a cornerstone of robust software design!