
Sharding vs partitioning vs replication: Embrace the key differences
Databases and system design


Modern data systems often deal with huge volumes of information and need to serve lots of users at the same time. To handle this, we use techniques to spread data across multiple places or make extra copies of it. Three common terms you’ll hear are partitioning, sharding, and replication. These concepts can be confusing for beginners because they all involve using multiple computers or storage locations to manage data. This guide will explain each concept in plain English, with real-life analogies (like libraries, pizza delivery, and grocery stores) to make the ideas easy to grasp. We’ll also discuss when to use each approach, common misunderstandings, and the pros and cons of each.

What is partitioning?
Partitioning means dividing a large dataset into smaller, more manageable pieces. Each piece is called a partition. Instead of one giant bucket holding all your data, you have several smaller buckets, each containing a portion of the data. Partitioning is a general term for splitting data into separate parts (which could be separate tables or even separate databases)1. The key idea is that each data item resides in only one of the partitions – the dataset is partitioned, not duplicated.
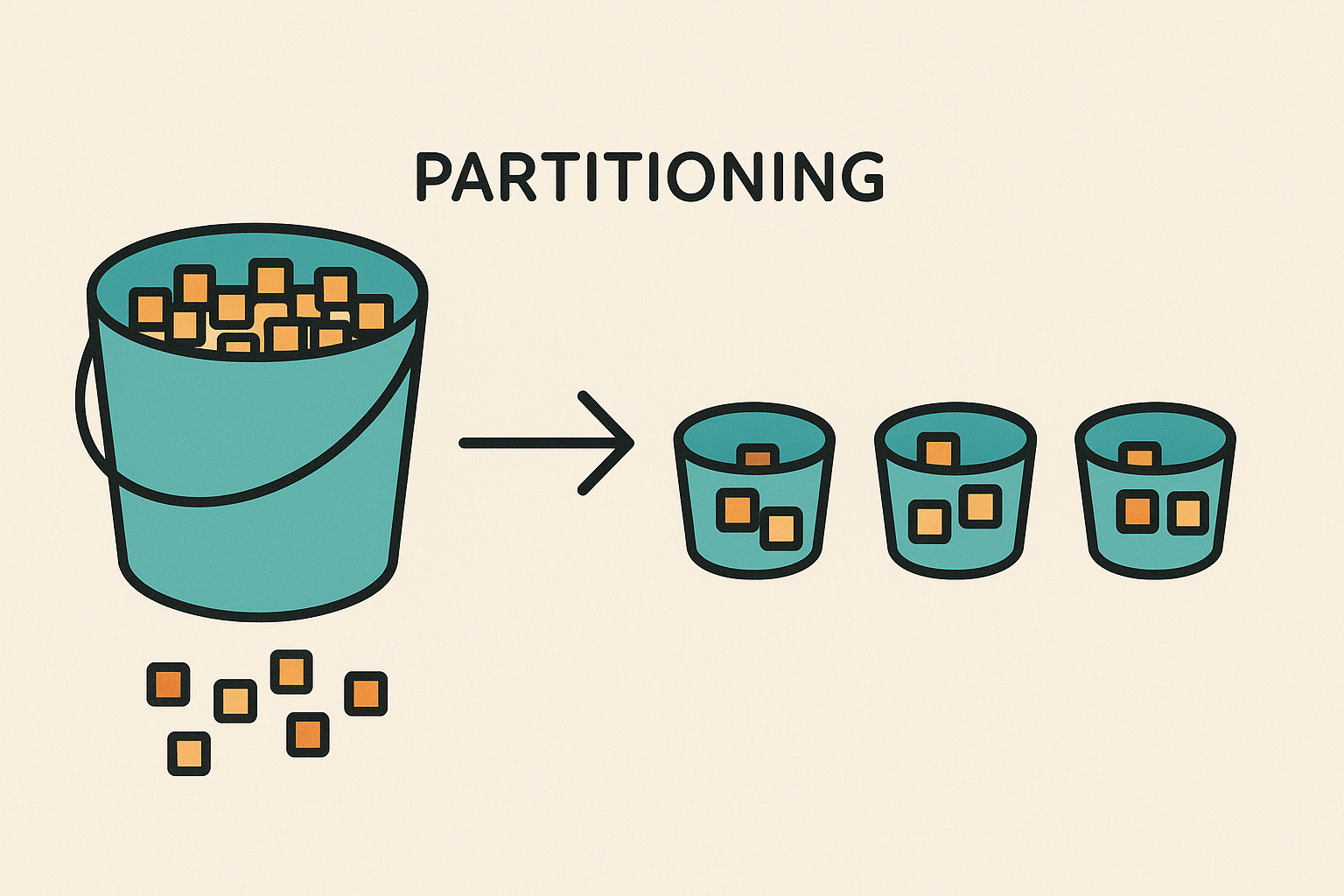
How partitioning works?
When you partition data, you choose a rule to decide which piece of data goes into which partition. For example, imagine a company has a customer database with millions of records. They might decide to split (partition) the customers by region: customers in the East in one partition and customers in the West in another. Now each partition holds a subset of the customers (East or West), and together they still represent the whole customer set. In databases, this could be done by putting rows with certain values (like Eastern region ZIP codes) into one table, and others into a different table. It’s like slicing a big pie into slices – each slice is easier to handle than the whole pie at once.
Real-life analogy - library sections
Think of a big library that has millions of books on all topics. If all the books were in one enormous room, finding a specific book would be slow and difficult. Libraries solve this by partitioning books into sections. For instance, all science books go to the science section, history books to the history section, fiction to another section, and so on. Each section is like a partition – it holds books of a certain category. If you want a history book, you go directly to the history partition (section) instead of searching the entire library. This makes finding and managing books easier. Similarly, in a database, if you partition customer data by region, a query for Eastern region customers only needs to look at the “East” partition, not the entire dataset.
Another analogy: Partitioning a phone directory into multiple volumes “A-M” and “N-Z” is like range partitioning. It’s analogous to how encyclopedias are split into volumes by alphabetical range2, making each volume more manageable.
Use cases - when and why to use partitioning?
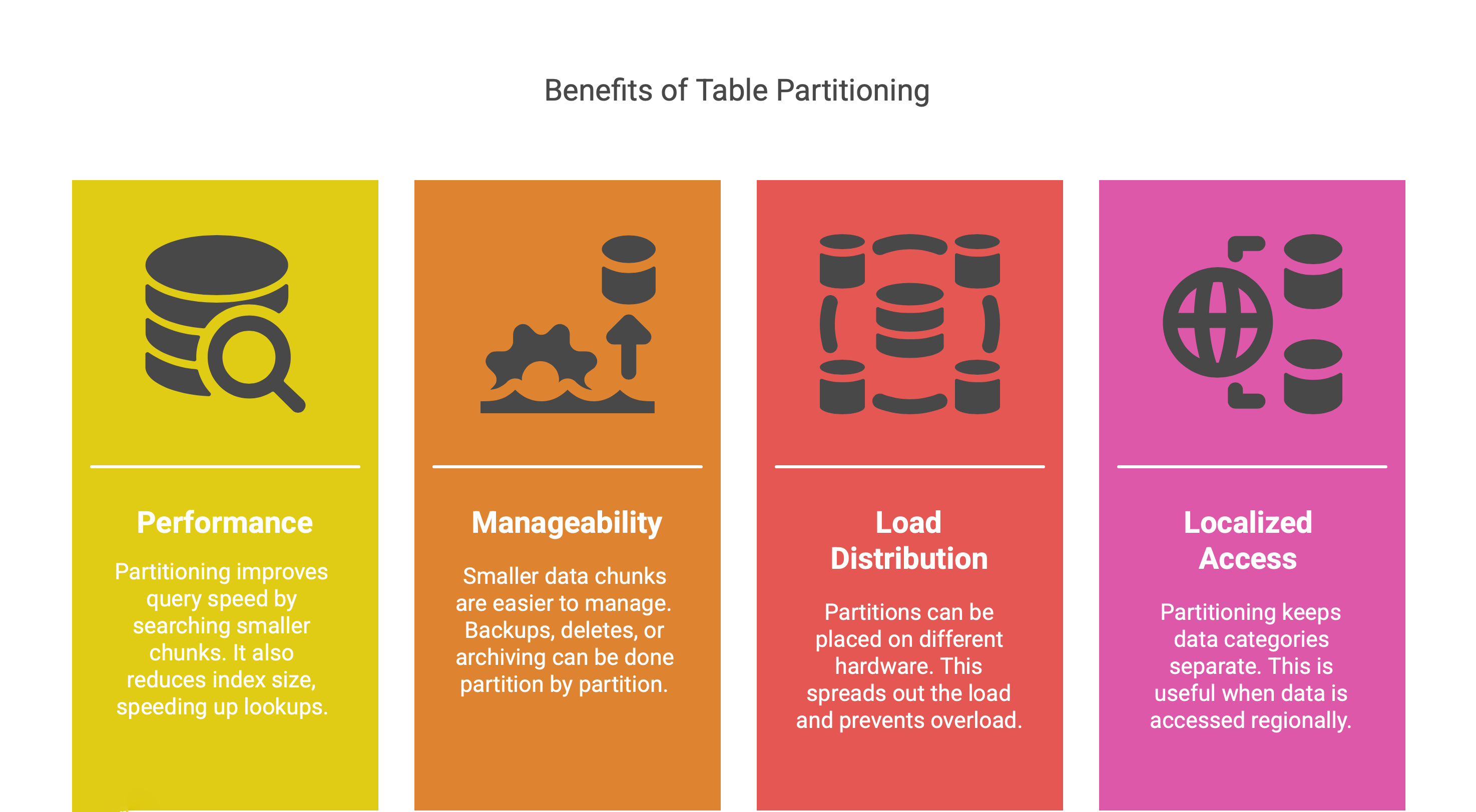
Performance with Large Data. When a single table becomes too large, partitioning it can improve query speed. For example, searching within one smaller partition is faster than searching a huge single table. It also reduces index size, which can speed up lookups.
Maintenance and Manageability. It’s easier to manage smaller chunks of data. Backups, deletes, or archiving can be done partition by partition. For instance, you could partition logs by month and easily drop the partition for an old month when it’s no longer needed.
Load Distribution. Different partitions can potentially be placed on different hardware (servers or disks) to spread out the load. If one partition gets very busy, it doesn’t directly overload the others.
Localized Access Patterns. If one category of data is accessed separately from others, partitioning keeps them apart. (E.g., an application where European customer data and Asian customer data are mostly accessed by different regional servers – partitioning by region could localize the traffic).
Note: Partitioning can be done in different ways. Horizontal partitioning (most relevant here) means splitting rows of a table into different tables or locations (each partition has the same columns/schema but different rows). Vertical partitioning means splitting by columns (storing different attributes in different places). For simplicity, when people say “partitioning” in the context of big data, they usually mean horizontal partitioning (dividing records into groups).
Now, let’s look at sharding, which is a special case of partitioning.
What is sharding?
Sharding is essentially a specific kind of partitioning – it usually refers to horizontal partitioning across multiple servers or database instances. When you “shard” a database, you break it into smaller pieces (shards) and each shard is stored on a separate database server. All shards put together contain the entire dataset, but each shard is responsible for only a portion of the data. Importantly, each shard has the same schema (structure) – like a blueprint – but just holds different rows. You can think of sharding as partitioning taken to the next level: the partitions live on different machines.
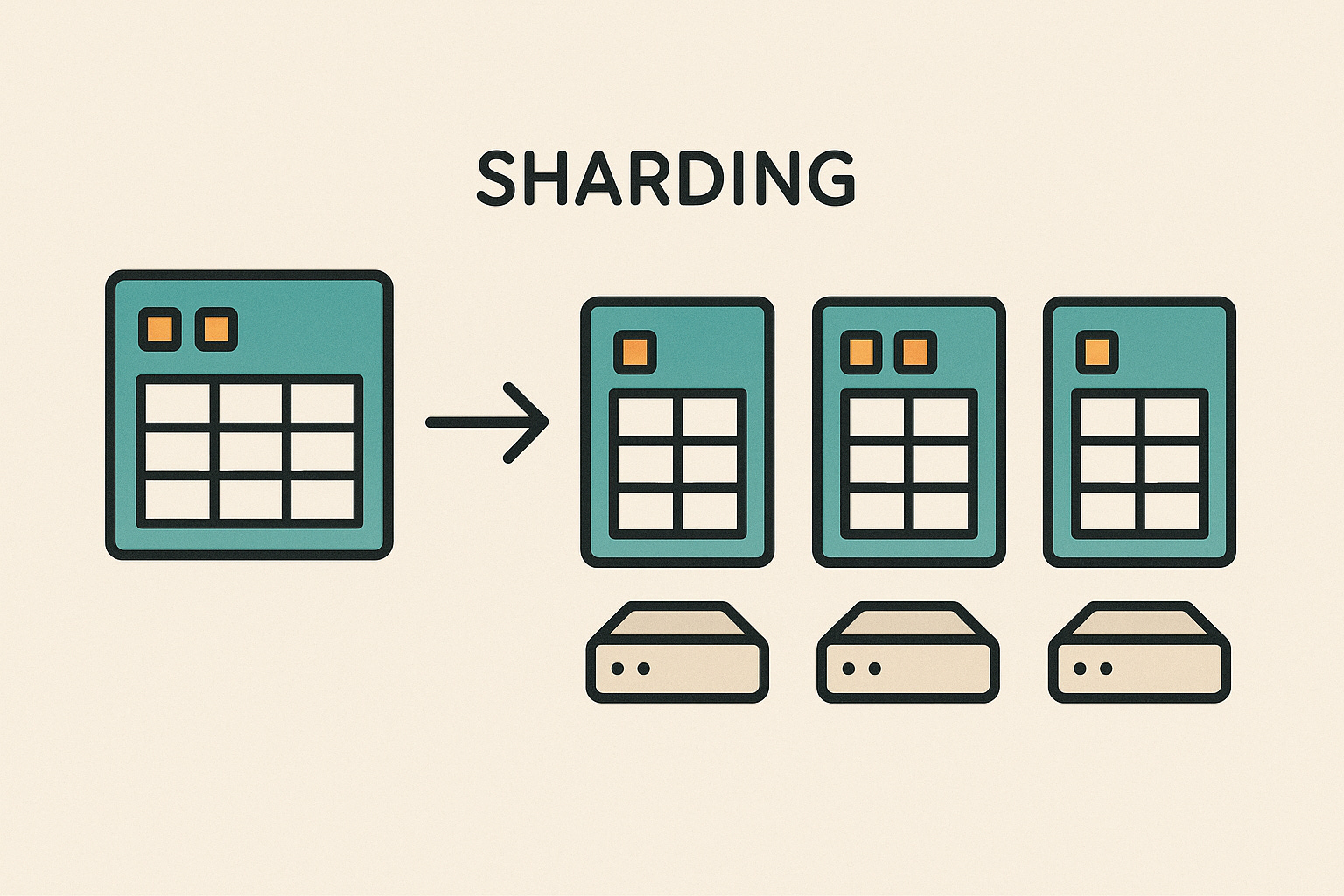
How sharding works?
Just like partitioning, sharding uses a rule or key (often called a shard key) to decide where each data record goes. For example, a social media service might shard its users by user ID: users with IDs in one range go to Shard 1 (Server 1), the next range to Shard 2 (Server 2), etc. If a new user signs up, the system uses the shard key rule to assign that user’s data to one of the shards. When that user later logs in, the system knows which server to go to based on their ID. In practice, this could be done by something like a hash of the user’s ID or the first letter of their username (e.g., usernames starting A–D on shard 1, E–H on shard 2, etc. – similar to splitting by alphabet as a simple strategy). The key point is each shard/server holds unique data (no overlap), and together the shards cover the whole dataset.
Real-life analogy - city pizza delivery (sharding by region)
Imagine a large city with one pizza shop that delivers to the entire city. As the city grows, one shop can’t handle all the orders – deliveries become slow. A common solution is to open multiple pizza branches in different parts of the city, and assign each branch a region. For instance, Branch North delivers only to northern neighborhoods, Branch Southcovers the south, and so on. Now each branch is serving a subset of addresses. In this analogy, the customer addresses are partitioned (sharded) by region. Each branch has the same menu and services (the same “schema”), but they serve different customers. Together, the branches serve the whole city. This is like sharding a database: each server (branch) holds a subset of the data (customers/orders) based on a key (customer location), and all servers together cover all customers. If the city keeps growing, you can add a new branch (new shard) to handle a new area – that’s scaling by sharding.
Use cases - when and why to use sharding?
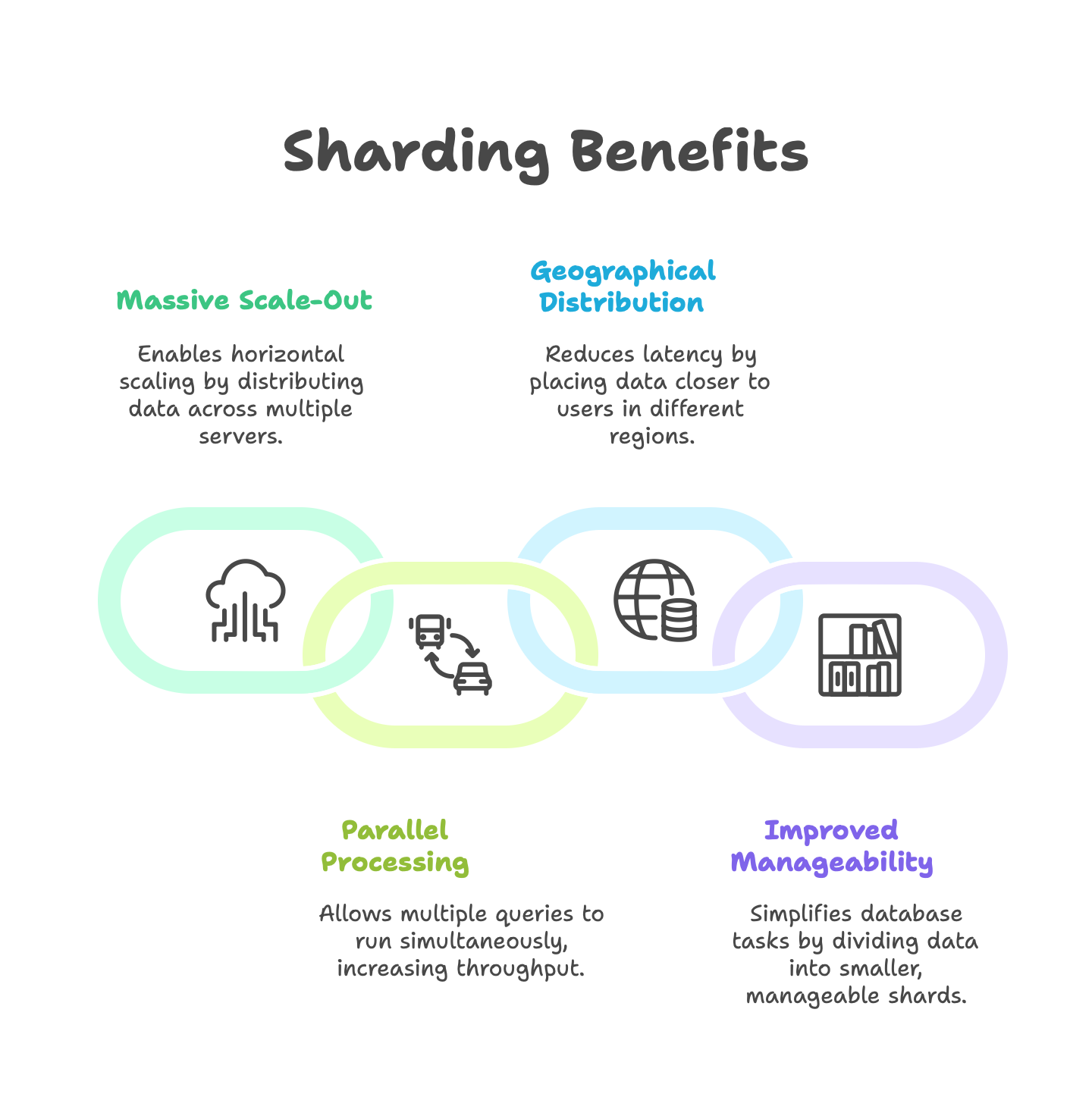
Massive Scale-Out. When your data can’t fit on one server or one server can’t handle the load (too many requests), sharding is a solution. Big web companies (social networks, large e-commerce sites) shard their user data once they outgrow a single database. It allows you to scale horizontally by adding more machines.
Parallel Processing. With shards on different servers, multiple queries can run in parallel on different shards. This can multiply throughput – e.g., 10 shards could potentially handle 10x the traffic of one, since each has its own CPU and disk.
Geographical Distribution. If users are worldwide, you might shard by region and place the data physically closer to users. For example, Europe user shard on a EU server, US users on a US server. This can reduce latency.
Improved Manageability at Scale. Each shard is like a smaller database. Tasks like indexing, vacuuming, or backup might be faster on each small shard than on one monolithic database.
Common misunderstanding - sharding vs partitioning
It’s easy to confuse these terms. In fact, sharding is partitioning, just implemented across multiple servers. Partitioning is a broad concept, and sharding is a specific way to do it for scalability. One way to put it: if you partitioned a big table into two smaller tables on the same database server, you partitioned but didn’t really shard. If you took those two tables and put them on two different servers, you’ve sharded the data. So, all sharding is partitioning, but not all partitioning is sharding.
Now that we’ve covered splitting data into pieces (with partitioning and sharding), let’s discuss the other strategy: copying data for redundancy, which is replication.
What is replication?
Replication means making copies of data on multiple machines or locations. Instead of each piece of data being stored in only one place (as with partitioning/sharding), replication stores the same data in two or more places3. If partitioning is like splitting a pie into slices, replication is like baking multiple identical pies. In databases, replication is often used so that if one database server fails, another copy (on a different server) can take over with the same data. The data on replicated servers is kept in sync (updated) so that each copy is nearly identical at any given time.
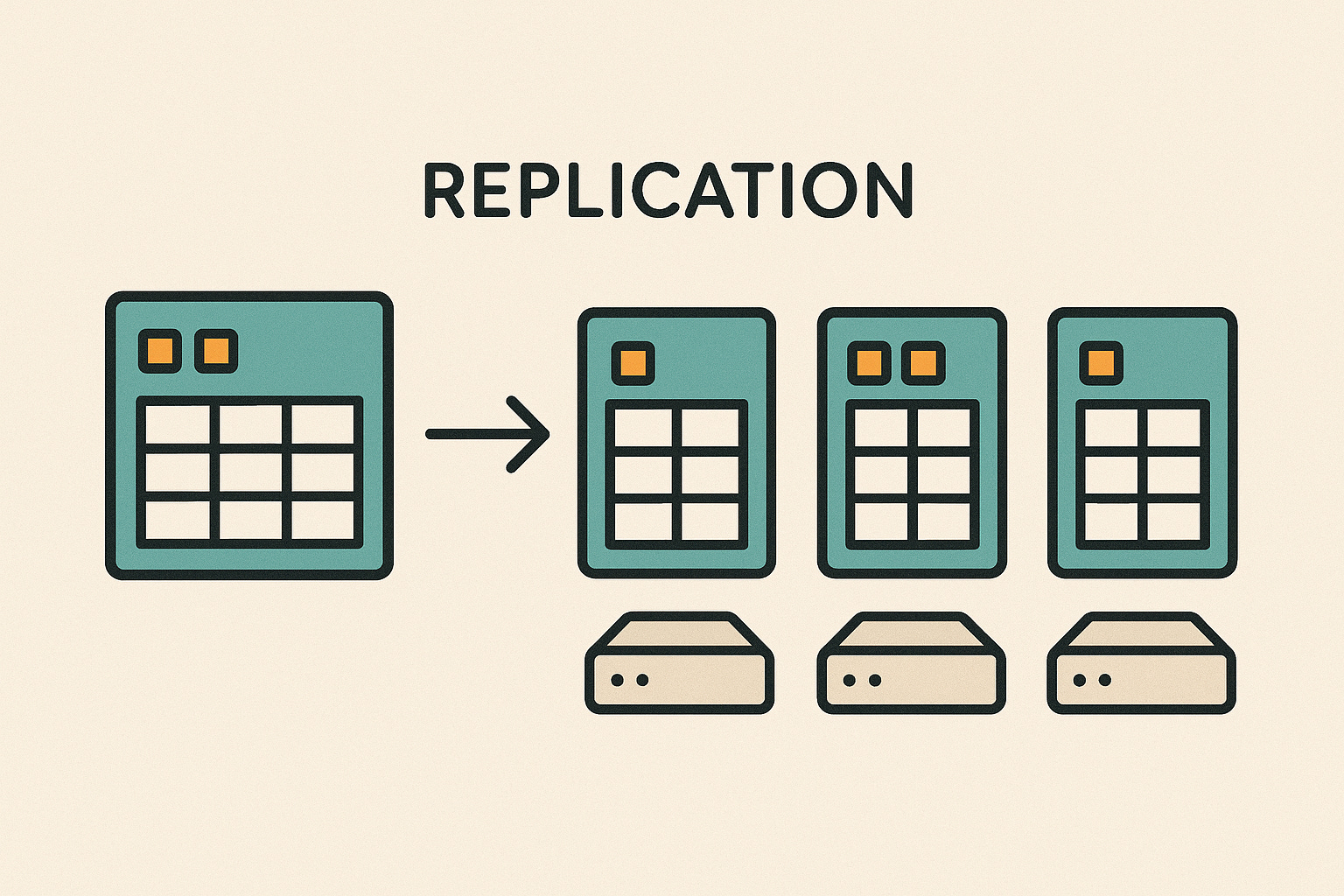
How replication works?
Typically, you have a primary copy of the data and one or more secondary copies. Whenever data is written (or changed) on the primary, those changes are sent to the secondary copies to apply the same changes. For example, imagine you have a customer database on Server A and you set up a replica on Server B. If you add a new customer or update an address on Server A, the system will propagate that change to Server B so that Server B’s data remains an exact copy. Depending on the system, this replication can happen almost instantly (synchronous replication) or with a slight delay (asynchronous replication). The end result is that each replica has the full dataset. If you query any replica for a piece of data, ideally you get the same answer because they all have the same information.
Real-life analogy - multiple grocery stores (replication of products)
Consider a popular grocery store chain in a city. To serve customers conveniently, the chain opens multiple stores in different neighborhoods. Importantly, each store carries the same products (more or less). The downtown store, the uptown store, and the suburb store all have the same items for sale. This is analogous to replication: each store is a copy of the same inventory and services. If the downtown store runs out of an item or closes for a day, you can go to another branch and likely find the item because they replicate the inventory across stores. The chain ensures that new products and updates (price changes, etc.) are sent to all stores, just as a database would propagate updates to all replicas. In this way, having multiple stores (replicas) increases availability – customers have multiple places to go – and resilience – one store closing doesn’t stop the business from serving customers at another location.
Another simple analogy: making photocopies of a document. The original document is like the primary database, and each photocopy is a replica. If the original gets coffee spilled on it, you have exact copies saved. Everyone can read the same content from their own copy – similar to multiple servers all having the same data.
Use cases - when and why to use replication?
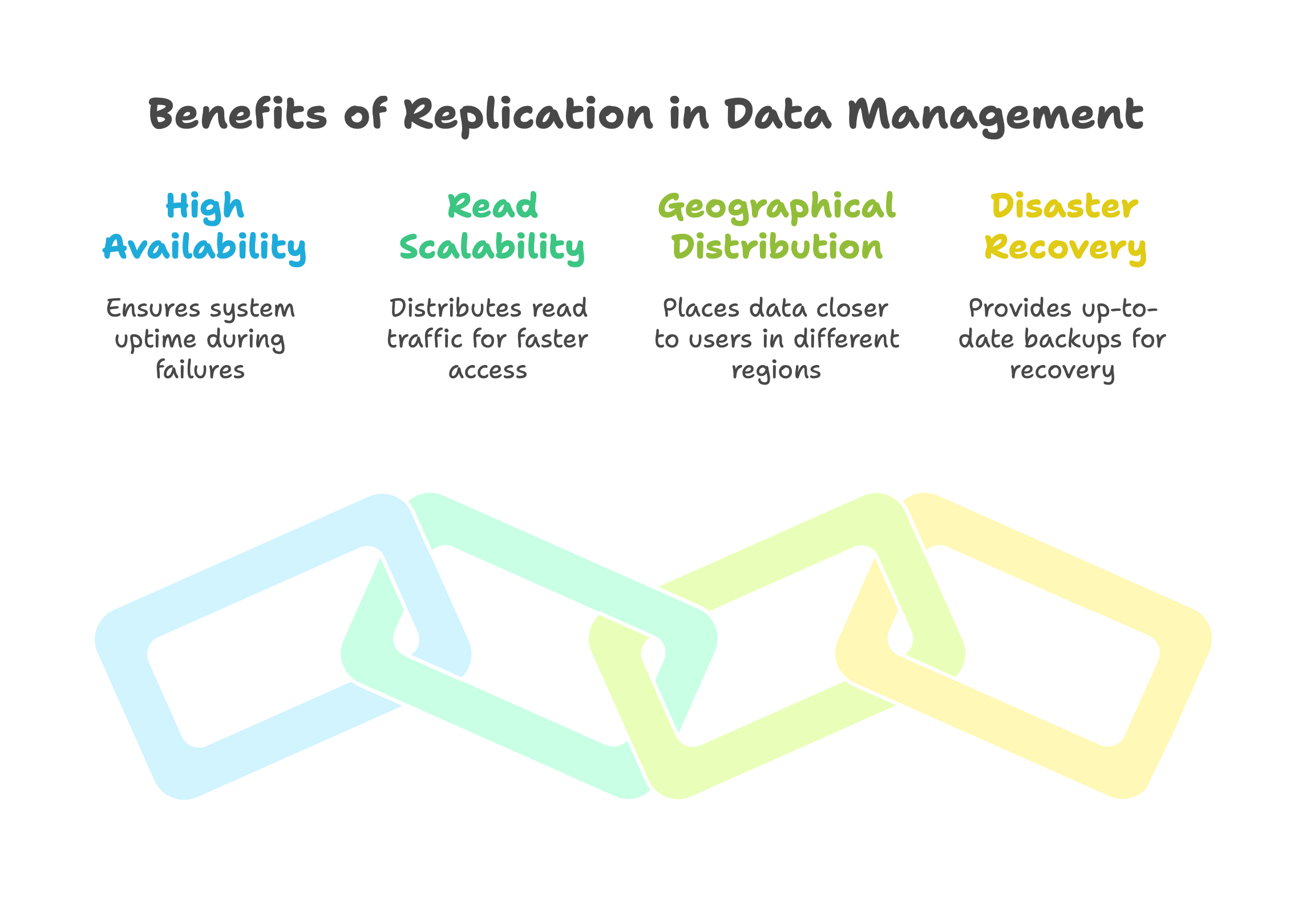
High Availability and Fault Tolerance. The top reason for replication is to ensure the system stays up even if something fails. If one database server crashes, a replica can take over with the same data, minimizing downtime. This is like having a backup generator – if one goes out, the other kicks in without losing power (or in this case, without losing data).
Read Scalability and Performance. If many users need to read data (but not necessarily write), having multiple copies allows spreading the read traffic. For instance, popular websites often have one primary database for writes and multiple read-only replicas to handle search or browsing queries. This means many people can read the data in parallel from different servers, speeding up responses.
Geographical Distribution for Speed. Replication is used to put data closer to users in different regions. If users in Europe and Asia both need access to the same data, you might keep a copy in a European data center and another in an Asian data center. Each region’s users get faster access from their nearest copy.
Disaster Recovery. Replication provides an up-to-date backup. If a data center is hit by a disaster (fire, flood), a replica in another location still has all the data. This greatly improves the ability to recover without data loss.
Common misunderstanding - replication vs backup
While both create copies of data, replication usually means online copies that are actively kept in sync for quick failover or load balancing, whereas a backup is often an offline copy (like a snapshot) that isn’t continuously updated. Backups are for restoring data long-term; replicas are for keeping the service running without interruption. Also, replication by itself doesn’t split the data or increase total capacity for distinct data – it’s duplicating the same data for safety and accessibility, not dividing different data across servers.
Comparing the approaches and clearing confusion
Now that we’ve defined partitioning, sharding, and replication, let’s compare them side by side and address some common points of confusion:
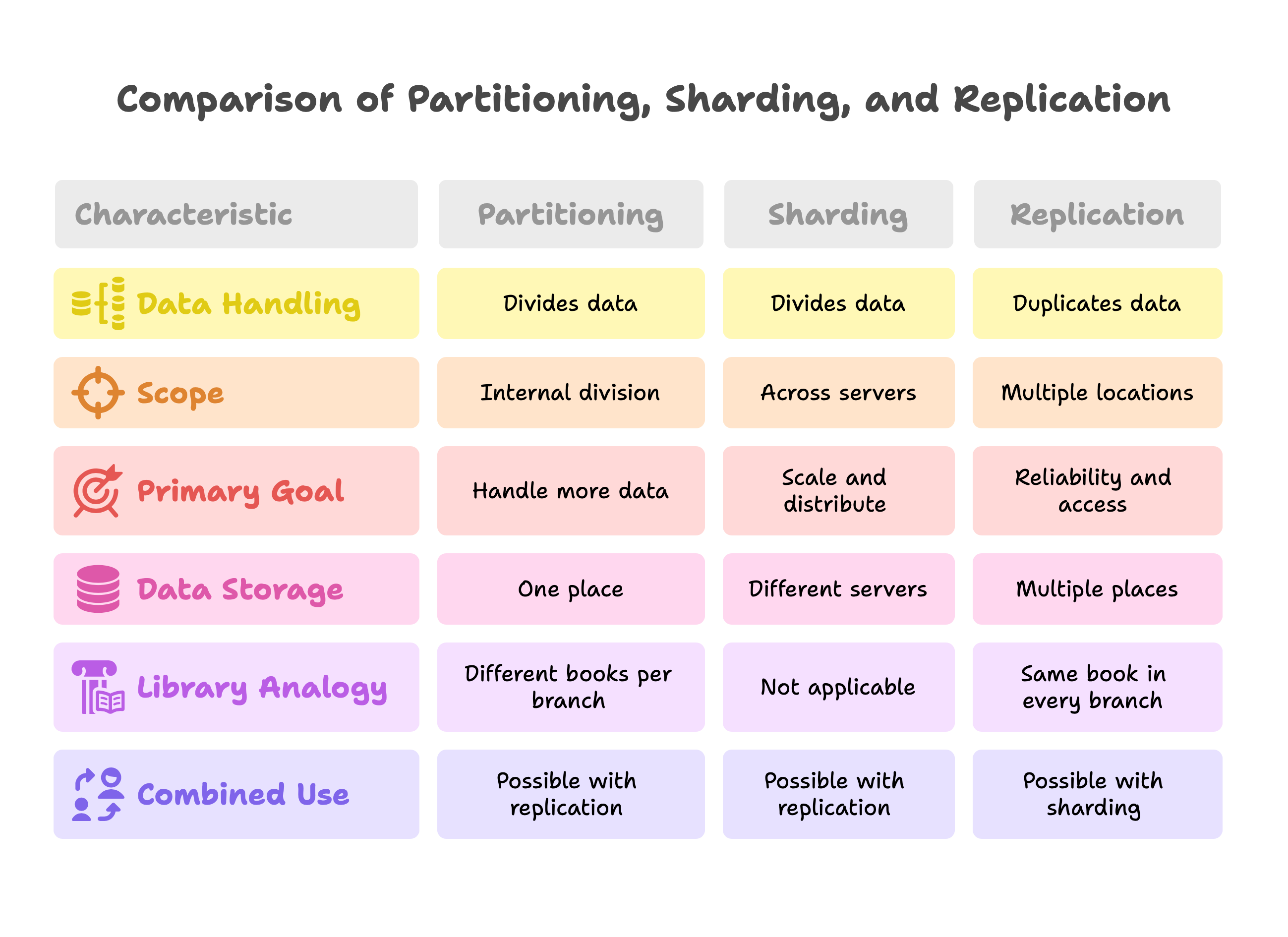
Partitioning vs. Sharding. These are closely related. Remember, sharding is basically horizontal partitioning on multiple servers. Both involve splitting a dataset into parts. The difference is mostly in scope: partitioning can be just an internal division (e.g., splitting a database table into parts on one server), while sharding usually implies those parts are on separate servers to scale out. If you hear someone say “we partitioned the data by date into yearly tables”, that could be on one server. If they say “we sharded our database by customer region”, they likely mean each region’s data lives on a different server or database instance. In summary, sharding is a kind of partitioning aimed at distributing load across multiple machines for scalability.
Partitioning vs. Replication. Here the difference is fundamental: Partitioning divides the data, while Replication duplicates the data. With partitioning, each piece of data is stored in one place (one partition). With replication, each piece of data is stored in multiple places (multiple replicas). You partition to handle more data or traffic by spreading it out (different data to different servers), and you replicate to protect against failures or to handle more read load (same data on multiple servers). Think of a library analogy: partitioning is like splitting the library’s catalog so each branch has different books (no branch has it all, but together they cover everything), whereas replication is like every branch having the same copy of a popular book so many people in different places can read it. Often systems use both: for example, a library might split books by topic between branches (partition), but have a few extremely popular books available in all branches (replication of those particular books).
Sharding vs. Replication. Sharding (a form of partitioning) and replication solve different problems. Sharding is about scale and distributing different subsets of data to different servers, while replication is about reliability and distributing copies of the same data to different servers. In practice, these are often combined. For instance, you might shard a user database by user ID into 10 shards (each shard gets 10% of users), and then replicate each shard to have one primary and one secondary copy. In that scenario, each user’s data lives on exactly one shard (partition) but also on two machines (primary and its replica). If a primary for shard 7 fails, its replica can take over, but that user’s data is not found on shards 1-6 because it’s partitioned to shard 7. This combination gives both scalability (via sharding) and fault tolerance (via replication). It’s important not to mix up the two concepts: adding more replicas won’t let you store more unique data (it just copies the same data), and adding more shards without replication won’t protect you if a server dies (because each piece of data was only on that one shard).
Summary of who gets what
In partitioning/sharding, each server/node gets a different slice of the data. (e.g., Node A has customers A-M, Node B has customers N-Z – no overlap in data between A and B).
In replication, each server/node gets the same copy of data. (e.g., Node A and Node B both have all customers A-Z – full overlap of data).
You can do one, the other, or both together, depending on your goals.
Choosing the right approach
If your database is getting too large or slow to handle on one machine, consider partitioning or sharding. This will help scale out the data across multiple machines and keep each machine’s load manageable. You’ll need to plan how to split the data (by user, by region, by product category, etc.). Remember, this adds complexity, so it’s usually done when you truly need to handle big scale.
If your main concern is staying online and preventing data loss, or serving many read requests quickly, consider replication. Even small systems benefit from a replica as a standby backup or to separate read traffic from writes. It’s a fundamental strategy for high availability.
Often, the real world uses a mix: for scaling reads and fault tolerance, you might replicate; for scaling writes or total data size, you partition/shard. They are not mutually exclusive and actually complement each other.
Common misunderstandings recap
“Sharding is totally different from partitioning” – Actually, sharding is just a form of partitioning (horizontal partitioning across servers). People sometimes use the terms interchangeably, but context matters.
“Replication will improve write scaling” – Not exactly. Replication helps with reads and fault tolerance. All writes still have to go somewhere and be copied, so it doesn’t multiply write capacity the way sharding can.
“Partitioning automatically gives you backups” – No, if you just partition without replication, you haven’t made any copies. If a partition is lost, that data is gone. Partitioning alone isn’t about fault tolerance; you’d need replication for that.
“Having multiple servers means we sharded” – Only if each server holds a different subset of data. If all your servers have the same data (like a cluster of identical replicas behind a load balancer), that’s replication and load balancing, not sharding.
Conclusion
In summary, partitioning/sharding and replication are two fundamental strategies for managing large-scale data. Partitioning (including sharding) is like splitting the data into chunks so each chunk is easier to handle (great for scaling out data volume and write/load capacity). Replication is like copying the data so it’s safer and more accessible (great for high availability and read scaling). By understanding these concepts, even beginners can design systems that handle growth and failures more gracefully. Remember our analogies: if your data system were a library or pizza delivery network, partitioning/sharding is dividing the work by sections or regions, and replication is making duplicate resources to serve more people and survive mishaps. With these basics in mind, you can better appreciate how big websites and databases stay fast and reliable by using the right mix of sharding, partitioning, and replication.
Enjoy building data systems with these tools, and don’t be afraid to refer back to these concepts as your datasets (or traffic) grow!
This is the nice article i came through cleared my all doubts....
Thankyou