
How systems handle failure — retries, circuit breakers, and idempotency
System design fundamentals


You click “Buy Now”.
The spinner turns… and turns… and then disappears.
You check your bank app - payment went through.
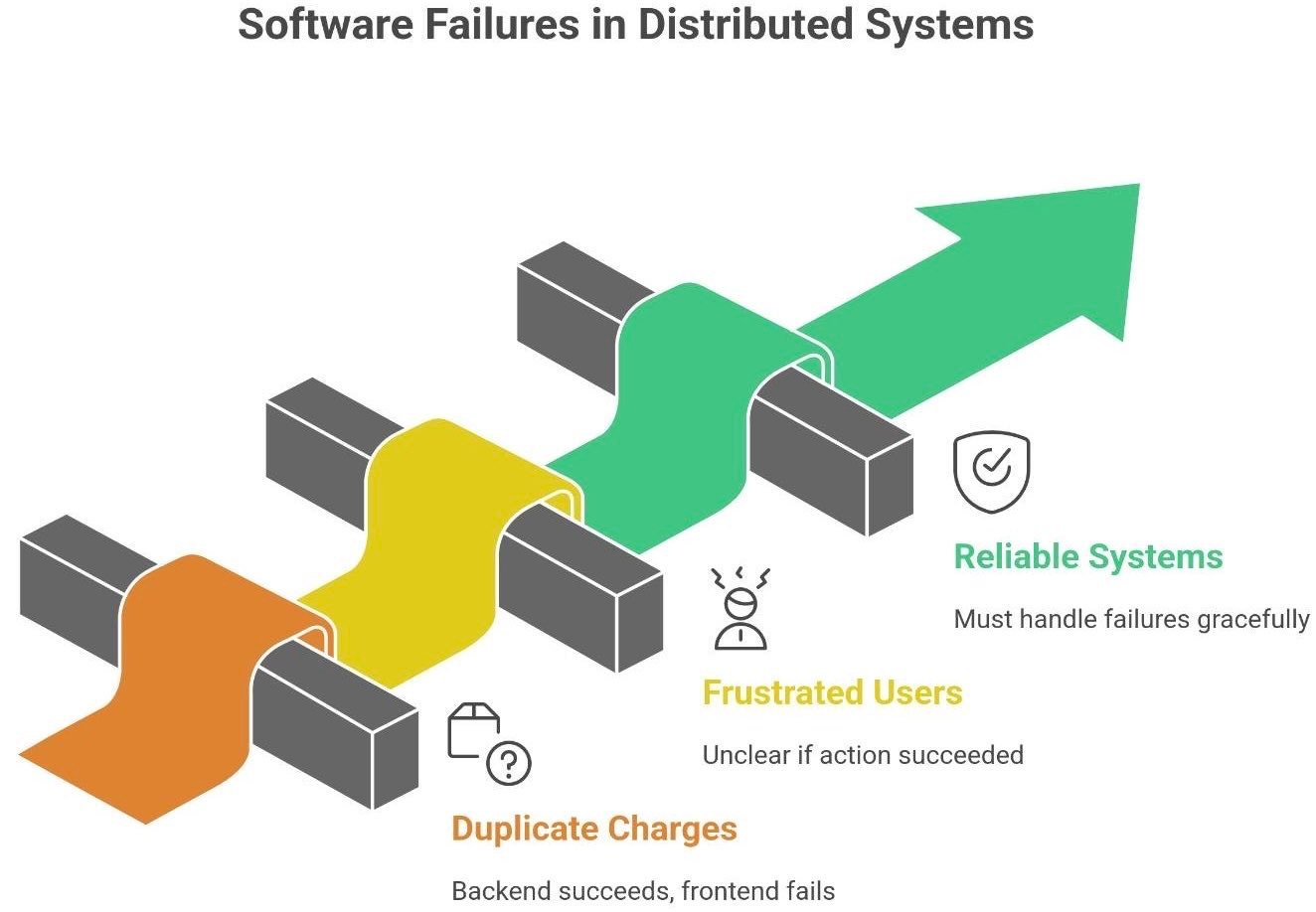
But the website shows: “Error - please try again”.Congratulations. You’ve just met the gray zone of distributed systems -
where a single operation might have succeeded, failed, or both.
Welcome to the world where software fails in confusing ways. In distributed systems, it’s possible for an action (like a payment) to actually succeed on the backend while the frontend thinks it failed. The result? Confusion, duplicate charges, and frustrated users. This scenario isn’t just a bad day for you; it’s a reality that reliable systems must handle gracefully.
In this post, we’ll explore how modern systems embrace failure without hurting the user experience. We’ll demystify how retries, circuit breakers, and idempotency work together so that even when things go wrong, they go right. By the end, you’ll see why resilient software doesn’t fear failure - it expects it, plans for it, and bounces back before anyone even notices.
💡 Before we go deeper - if you’re enjoying posts like this, consider subscribing to my publication.
I write about system design, architecture, AI, reliability, and the “behind-the-scenes” stuff that helps you grow as a developer.
Subscribing means you won’t miss new breakdowns, diagrams, or hands-on explanations - and it genuinely helps me keep creating more content like this for you.
Join in if you want to learn this stuff together. 🚀
⚙️ Failure is normal in distributed systems
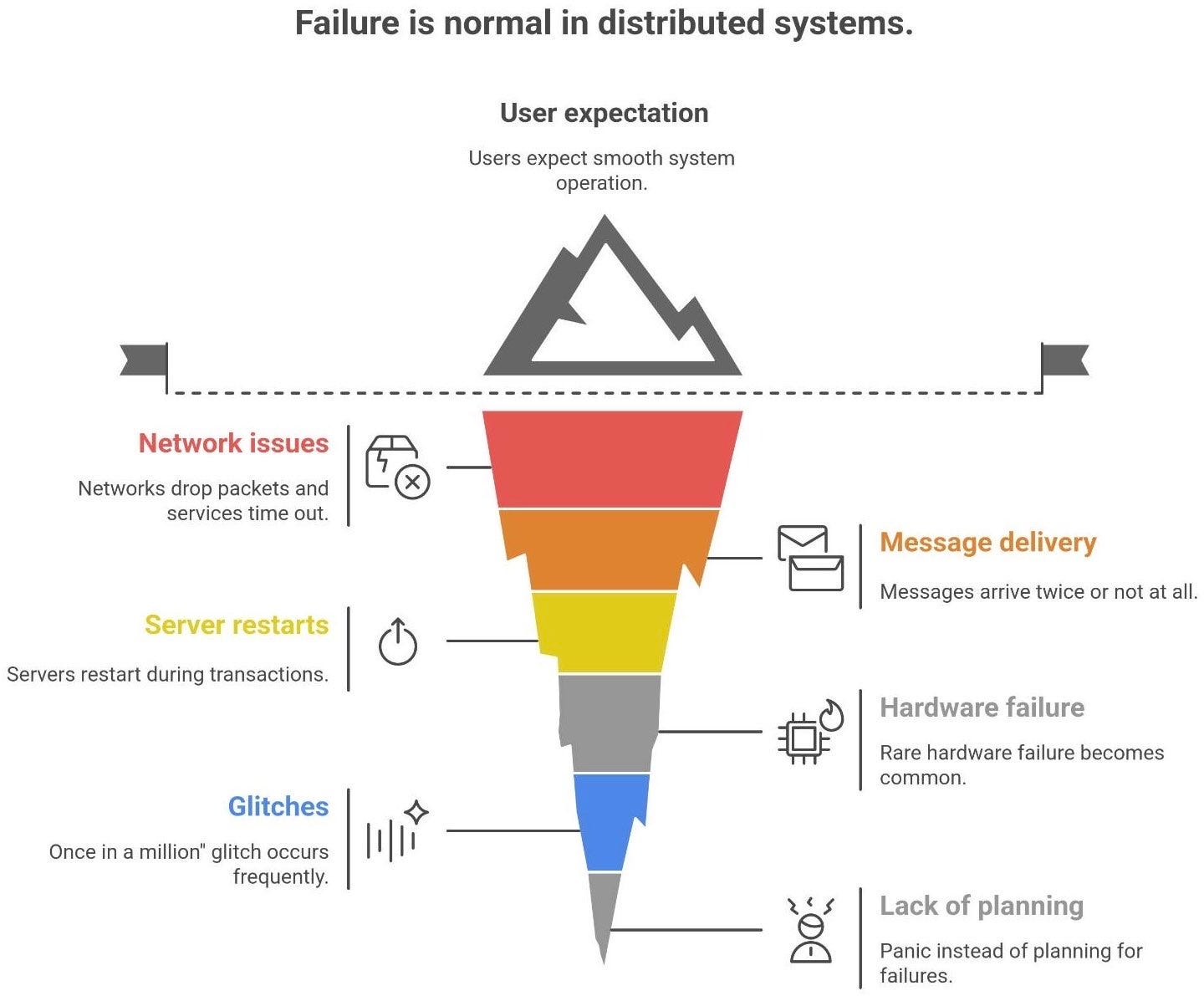
In a distributed system, failure is not an exception - it’s normal. Networks drop packets. Services time out. Messages can arrive twice (or not at all). Servers might restart right in the middle of a transaction. Yet users still expect the system to “just work” smoothly despite all that chaos happening behind the scenes.
Why so much chaos? Because once you have many components interacting over a network, the unlikely becomes likely. A hardware failure that’s rare on one machine becomes common when you have thousands1. A “once in a million” glitch might occur a few times a day across a global fleet of servers. As a classic principle of cloud computing states: “In distributed systems, failure is normal… failures are assumed, designs work around them, and software anticipates them”.
The key insight is this:
➡️ Reliability isn’t about avoiding failure; it’s about making failure uneventful. In other words, a well-designed system experiences faults all the time, but it handles them so gracefully that nobody notices. Instead of treating failures as catastrophic anomalies, resilient systems treat them as expected events and have built-in responses. Just like a car has shock absorbers for bumps in the road, distributed software has patterns to absorb the shocks of downtime, lost messages, and random errors.
So, the mindset shift is crucial: don’t panic when things go wrong - plan for it. The next sections will cover exactly how to plan for failures using retries, circuit breakers, and idempotency so that even when something breaks, your application bends without breaking.
🔁 The first line of defense — retries
When an operation fails transiently (say, a network request times out), often the simplest fix is: try again. This is the idea of retries – automatically attempting an operation again in hopes that a momentary glitch resolves. In many cases, a quick retry turns a failure into a success: the network hiccup passes, the second call reaches the server, and all is well. In fact, retries are a major reason distributed systems can mask inevitable flakiness and still meet high uptime goals2.
However, retries are a double-edged sword. If used naively, they can make things worse instead of better.
Retry storms and overload. If a service is truly down or overloaded, blind retries from many clients can create a stampede. Imagine hundreds of clients all retrying failed requests at the same time – the failing service gets bombarded with even more traffic just when it’s least able to handle it. This feedback loop is known as a retry storm, and it can turn a small outage into a cascade of failures. In one scenario, a failure in a deep call chain caused a 2^N explosion of retries, overwhelming the database and prolonging the outage. In short, retries are “selfish” - each client is just trying to succeed, but collectively they can hammer the server3.
Duplicate actions. Retrying an operation that actually did go through can trigger duplicate effects. For example, if the first “Buy Now” did charge your card but the acknowledgement got lost, a retry might charge you again. Without precautions, you could end up with two payments, two created accounts, or duplicate messages. In technical terms, at-least-once delivery means the same action might happen twice. (Ever gotten two confirmation emails for one order? That’s a duplicate caused by a retry.) Unless the system is built to handle this, a single user action could be processed multiple times4.
How do we retry safely? The answer is controlled retries, using techniques like exponential backoff and jitter.
Exponential Backoff. Instead of retrying immediately at a constant rate, exponential backoff waits progressively longer between attempts. For example, wait 1 second before the first retry, 2 seconds before the next, then 4 seconds, then 8, and so on. This gives the failing service time to recover and prevents slamming it with rapid-fire calls. It’s like knocking on a door: if no one answers, you wait a bit longer before knocking again. This pattern is extremely common for handling transient failures gracefully5.
Jitter (Random Delay). A big problem is when many clients retry in sync – even with backoff, if they all wait 1, 2, 4, 8 seconds, they’ll still line up and hit at once. Jitter introduces randomness to break the synchronization. For instance, if backoff says “wait 2 seconds”, each client actually waits a random time up to 2 seconds (maybe one waits 1.7s, another 2.3s). This spreads out the retries and avoids a thundering herd. Jitter is like adding a small random delay to your next knock on the door, so that a whole crowd of people won’t all knock in unison.
With exponential backoff and jitter, retries become polite and intelligent. They exponentially decrease the retry rate under duress and randomize the timing so that servers aren’t overwhelmed. Most cloud SDKs and HTTP clients implement these patterns by default (e.g., the AWS SDK uses capped exponential backoff with jitter to protect services).
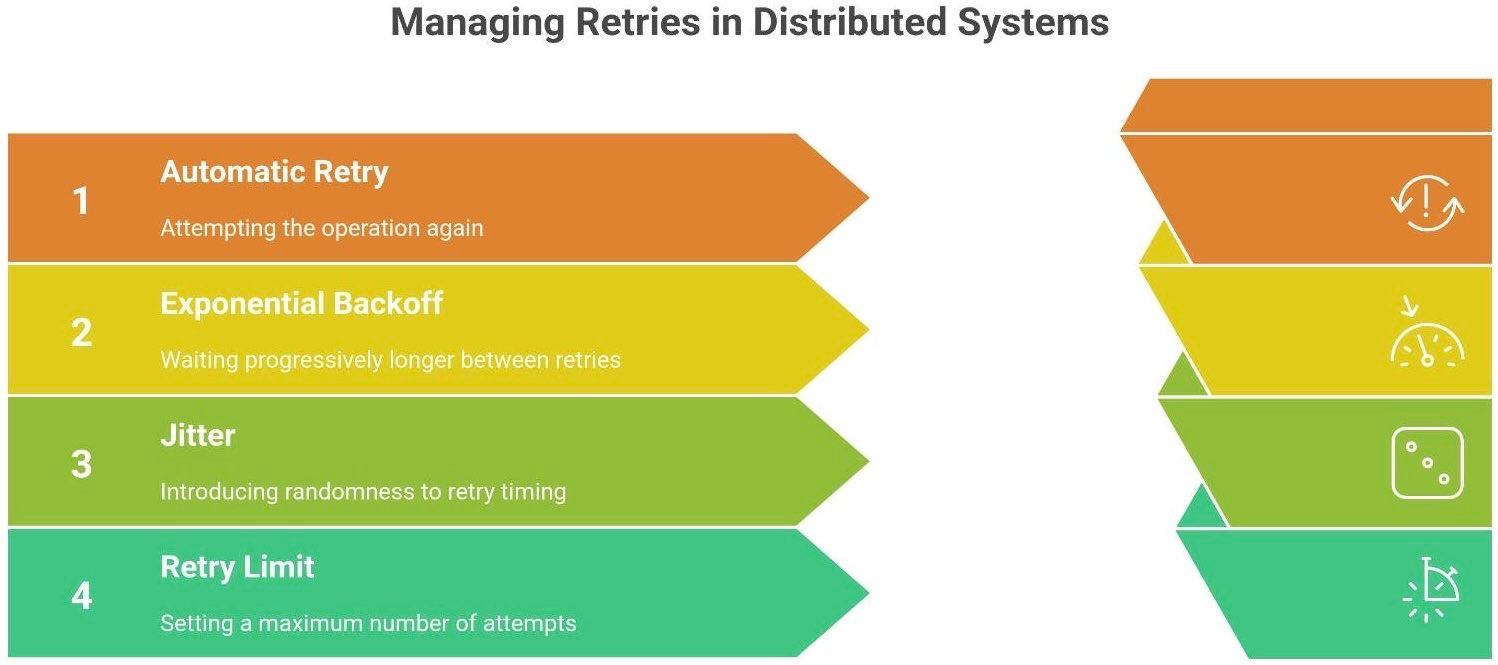
Finally, it’s critical to limit retries. Have a maximum number of attempts or a total timeout budget. Unbounded retries can loop forever or until the system collapses – definitely an anti-pattern. Many systems also differentiate errors: for example, do not retry on a 400 Bad Request (the request is invalid and won’t magically succeed later). Save retries for the maybe-fixable errors like timeouts, 5xx server errors, or network glitches.
Metaphor: Don’t shout the same question every second to someone who didn’t hear you. If you get silence or a muffled answer, pause. Wait a bit longer each time, and try again – gently. By raising your voice gradually and adding a random pause, you avoid becoming part of a chaotic shouting chorus.
⚡ Circuit breaker — knowing when to stop trying
If retries are the first line of defense, the circuit breaker pattern is the emergency stop. Sometimes the most resilient thing you can do is stop calling a failing service and give it time to heal. A circuit breaker in software plays a similar role to one in your house’s electrical panel: when too many failures occur, it “trips” to prevent further damage.
Imagine a downstream service that has been timing out for dozens of requests in a row. Instead of blindly retrying again and again, a smart client will flip the circuit open: it refuses to send more requests for a short period. This prevents wasting resources on doomed attempts and stops adding load to a service that’s already in trouble. As Martin Fowler put it, without circuit breakers a chain of failures can consume critical resources and lead to a cascading collapse of multiple systems6. The circuit breaker breaks the chain.
A typical software circuit breaker has three states:
Closed (normal operation): Everything is working, so the circuit is closed and calls flow normally. The client keeps a failure count. As long as calls succeed (or failures stay below a threshold), the breaker remains closed. It’s like the switch is “on” allowing electricity (requests) through.
Open (tripped): After a certain number of failures in a row (say 5 failures within a minute), the breaker “trips” open. In the Open state, no calls are made at all - the client fails fast, immediately returning an error or fallback response without even attempting the operation. It’s as if the switch is “off” - requests get short-circuited. The open state usually lasts for a predefined timeout interval. The idea is to stop hammering the failing service and give it a break7.
Half-open (probe/test): After the open timeout expires, the circuit goes half-open. In this state, the client will allow a limited number of test requests to see if the service has recovered. It’s like cautiously closing the circuit just a little to test the waters. If a test request succeeds, that’s a good sign - the breaker may reset to Closed (fully close the circuit) and resume normal operations, resetting the failure counter. If a test request fails, the breaker snaps back to Open and the timeout period starts over. This prevents a flapping service from getting flooded immediately as it comes back online.

These states and transitions ensure that once a service starts consistently failing, we stop persistent retries (which were just hurting) and periodically check if it’s okay again. The pattern improves overall stability and responsiveness - clients don’t hang waiting for timeouts on every request when the service is known to be down; they fail fast or fall back to a default behavior. Meanwhile, the failing component gets breathing room to recover instead of being DDoS’ed by its own clients.
Metaphor: The circuit breaker is like a friend who says: “They’re not answering and must be overwhelmed. Let’s stop calling them for a while - they clearly need time to recover.” It’s the voice of reason that prevents you from redialing a number 100 times in a minute. Only after a pause will your friend say, “Okay, try again now and see if they pick up.” If they do, great! If not, wait a bit longer and try later.
The insight here is that persistence without awareness isn’t resilience - it’s self-sabotage. A robust system needs to know when to quit and when to retry. Circuit breakers add that awareness by monitoring error rates. They essentially enforce the rule: “Don’t keep doing the same failing thing over and over”. Instead, fail fast and handle it gracefully (perhaps return a cached response or a friendly error to the user), and try again later when there’s a chance of success.
Most modern frameworks and libraries have circuit breaker implementations (Netflix’s Hystrix popularized this, and tools like Resilience4j in Java or Polly in .NET provide them). They typically allow configuration of the failure threshold, open-state timeout, and half-open trial settings. Additionally, breakers often work in tandem with retries: e.g., you might retry a few times on an error, but if failures persist, open the circuit. In fact, combining Retries + Circuit Breaker is common – retry a transient error, but if errors keep happening, stop trying for a bit.
🧮 Idempotency — doing the same thing twice without breaking anything
Retries and circuit breakers help manage when and how to repeat operations safely. But there’s a deeper prerequisite for safe retries: the operation itself must be safe to repeat. This is where idempotency comes in.
An operation is idempotent if performing it multiple times has the same effect as doing it once. If you send the same request twice, an idempotent service will not create a mess or unintended side effects. The classic example: setting a value vs. incrementing a value.
Idempotent example: “Set user’s balance to $100”. Do it once, the balance is $100. Do it five times, the balance is still $100. No harm in the repeats.
Non-idempotent example: “Add $100 to user’s balance”. Do it once, balance increases by $100. Do it five times (accidentally), and you’ve added $500 - likely not what you intended!
In formal terms, if f(x) is an idempotent operation, then f(f(x)) = f(x). The outcome doesn’t change after the first application. Repeating it doesn’t amplify the effect.
Why is this so crucial? Because in distributed systems, you often can’t be sure if a request succeeded or not, so you may need to retry - and that retry should not cause bad side effects. If an operation is not idempotent, even a single retry can produce incorrect results. Think of charging a credit card, sending an email, or creating a user account - if those actions are duplicated, you get double charges, duplicate emails, or multiple accounts for the same user. Not good.
Key idea: Retries are safe only if the operation is idempotent (or the system has other ways to avoid double-processing). This is why many APIs that involve side effects are designed to be idempotent or provide idempotency mechanisms. For instance, HTTP GET is by definition idempotent (it’s just a read), and HTTP PUT is generally designed to be idempotent (replace resource state), whereas POST often is not (create a new resource, which if repeated creates duplicates).
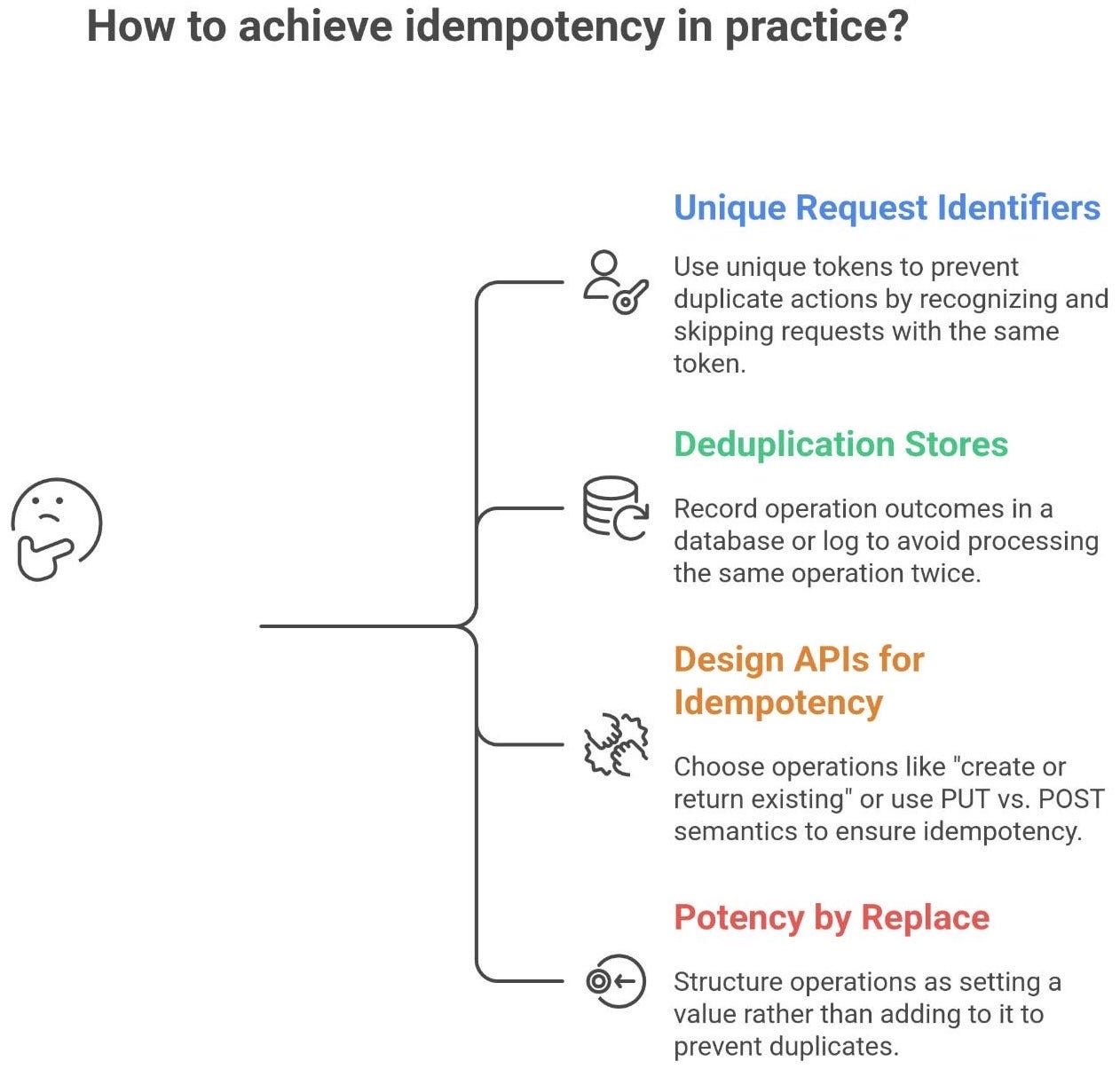
So how do we achieve idempotency in practice? A few common techniques and patterns:
Unique Request Identifiers (Idempotency keys): The client generates a unique token (say a UUID) for each logical operation and sends it with the request. The server keeps track of which tokens it has seen. If a duplicate request with the same token arrives (e.g., due to a retry), the server recognizes it and skips the duplicate action, or simply returns the same result as the original request without performing the action again89. For example, payment APIs (Stripe, PayPal, etc.) let you provide an idempotency key so that if the network flakes out after you hit “Pay”, you can safely retry with the same key and not charge the customer twice. AWS uses this approach widely - many AWS APIs (like EC2 instance creation) accept a client token, and if the same token is reused, AWS knows “Ah, I’ve already handled this request”. This shifts the ambiguity of “did it succeed or not?” into a clear record on the server side.
Deduplication stores / logs: The server can record the outcome of operations in a database or log keyed by the operation’s unique ID. For example, a service might have a processed_requests table where it inserts the request ID when processing a transaction. If it receives the same ID again, it checks the table, sees it’s already processed, and aborts or returns the previous result10. This pattern is common in message processing: consumers keep track of message IDs they’ve seen to avoid processing the same message twice. The storage could be an in-memory cache, a SQL table, or even attaching identifiers to the resource created (like tagging a database entry with the request ID that created it).
Designing APIs for idempotency: Sometimes it’s as simple as choosing the right operation semantics. If you design an API call as “create or return existing” (like a put-if-absent), it can be made idempotent. For instance, an API might treat duplicate create requests as a no-op after the first time. Another approach is using PUT vs. POST semantics: e.g., PUT /orders/{id} with the same order ID can be made to either create the order if not exists or return the existing one if it does, ensuring that retrying the PUT doesn’t create multiple orders. Good API design encourages making operations idempotent whenever possible. In fact, one of Amazon’s best practices is: “design APIs to be idempotent, meaning they can be safely retried”.
Potency by “Replace” Instead of “Add”: As mentioned, structure operations as set to a value rather than add a value, or idempotent upsert instead of insert. For example, if an event says “user paid $100 on order #123”, record that specific event once rather than something like “increase balance by 100” which can’t be repeated. In databases, use UPSERT (update-or-insert) so that applying the same record twice results in one record (updated) not duplicates. Idempotent design often requires thinking in terms of final state (“ensure it ends up like this”) rather than one-time actions (“do this once”).
It’s worth noting that idempotency sometimes requires extra work on the backend - keeping logs of request IDs, handling more complex logic - but it significantly improves reliability. It removes ambiguity. In our initial story, the reason it’s a gray zone is because the system wasn’t fully idempotent from the user’s perspective. The payment went through (state changed) but the website didn’t see the result, and it couldn’t safely retry the exact operation without risking a double charge. With an idempotent design (say the site had sent a charge request with an idempotency key), the client could retry the charge call safely - the payment service would say “I already did that, here’s the result, no double charge”.
Metaphor: Idempotency is like saying, “I already told you once - doing it again shouldn’t change the outcome”. If you ask a friend to turn off the light, and they did it, asking again won’t plunge the room into double darkness - it’s just off. But if you asked them to “turn the dimmer down by 20%”, asking twice would make it twice as dark. Idempotency is preferring the first style of request (“set it to this state”) so that repeating the request doesn’t cause chaos.
Before we move on, an important link: Idempotency + Retries + Circuit Breakers all dance together. Idempotency makes retries safe, and circuit breakers stop futile retries from overwhelming anyone. In the next section, we’ll see how these patterns combine to create a system that can heal itself in the face of failure.
🧠 Putting it together — a system that heals itself
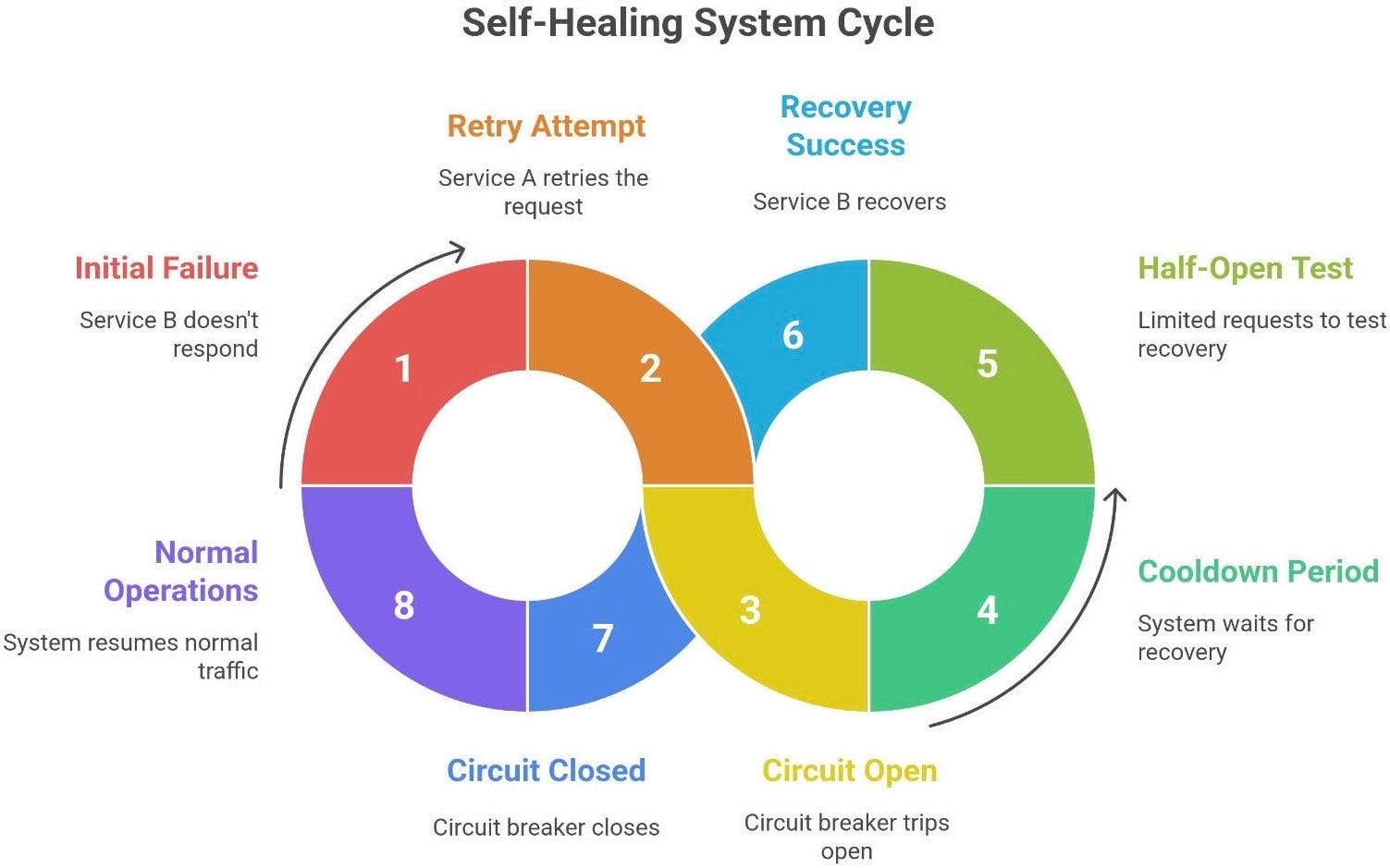
Let’s walk through a failure scenario and see how retries, circuit breakers, and idempotency complement each other to save the day:
Scenario: You have a service A (perhaps a frontend service) that calls service B (say, a payment service). A user initiates an action that triggers A -> B call.
Step 1: Initial failure and retry. Service B doesn’t respond (maybe it’s slow or temporarily down). Service A’s request to B times out. Now, A doesn’t immediately give up; it knows this could be a transient fault. Thanks to a retry policy, A retries the request to B after, say, 1 second. Importantly, the operation is designed to be idempotent - perhaps it includes a unique transaction ID for this payment. Therefore, if B actually got the first request and processed it, the second request will be recognized as a duplicate and ignored (or B will return the previous result). If the first request never hit B, then the retry is truly needed. Either way, retrying won’t cause a double effect. The retry gives B a second chance to do the work, in case the issue was a fluke.
Step 2: Multiple failures and circuit open. Unfortunately, service B is having a bad time - it’s still unresponsive on the retry attempt. A times out again. At this point, our retry policy might attempt again with exponential backoff (wait 2 seconds, try again). Let’s say we try a couple of times, but all attempts within a short window keep failing. Now the circuit breaker logic kicks in: after, say, 3 failed tries in a row, A’s circuit breaker for calls to B trips open. This means for the next 30 seconds, A will not send any requests to B at all. Any user actions that would call B immediately get a failure or fallback response. This sounds harsh, but it prevents A from continuously piling requests onto B when B is definitely down. It’s containing the damage. Users might get a quick error message like “Service unavailable, please try after some time” immediately rather than staring at spinners that will inevitably timeout. Meanwhile, B gets a breather without traffic.
Step 3: Self-healing test (Half-open). After the cooldown period (30s) passes, A’s circuit breaker moves to half-open. It will now allow a limited test through - maybe it lets one or a few requests go to B instead of all of them. So the next user action triggers a real call to B. If B is still down and this call fails, the breaker snaps back to Open and the cycle repeats (wait longer). But suppose by now the team fixed B or it recovered on its own. That test request succeeds. Great! The circuit breaker takes this as a signal that B is healthy again. It transitions back to Closed state, resetting the failure count. Now A resumes normal operations and starts sending all requests to B again.
Step 4: Graceful recovery and continuation. Traffic flows normally; the system healed itself. Users maybe noticed a brief hiccup, but the system didn’t meltdown. If idempotency keys were in play, any retried operations during the half-open testing are safe and don’t double-execute. If some actions couldn’t be completed while the circuit was open, perhaps A queued them or returned an error that the user can retry. But importantly, when B came back, it wasn’t immediately crushed by a thundering herd, because the circuit breaker let only a trickle of requests through to confirm health before fully opening the gates.
Throughout this dance, observability (which we’ll discuss next) would be tracking what’s happening: metrics like “how many retries occurred” or “is the circuit breaker open right now” would alert engineers that B was failing and recovering.
Insight: Resilient systems aren’t perfect; they expect things to break. The magic is in how they fail:
They fail fast when needed (circuit open),
They retry calmly when it’s worth it (controlled retries with backoff),
They avoid dangerous side effects (idempotent operations),
And they recover automatically (circuit half-open to closed transition).
In essence, the system “takes a deep breath” during an outage: it stops pressing on the broken part, waits a bit, tries again carefully, and then continues as normal. This is often referred to as graceful degradation and self-healing. Users might see slightly slower responses or a friendly error message, but not a catastrophic failure or inconsistent data.
Real-world example: Netflix (which pioneered a lot of these patterns) will show you older cached content or a “Netflix is temporarily unavailable” screen rather than just crash, if its backend services are failing. After a few seconds, it will transparently retry connecting. You, as the user, are only mildly inconvenienced instead of being completely unable to use the service.
🧩 Observability — seeing failures before users do
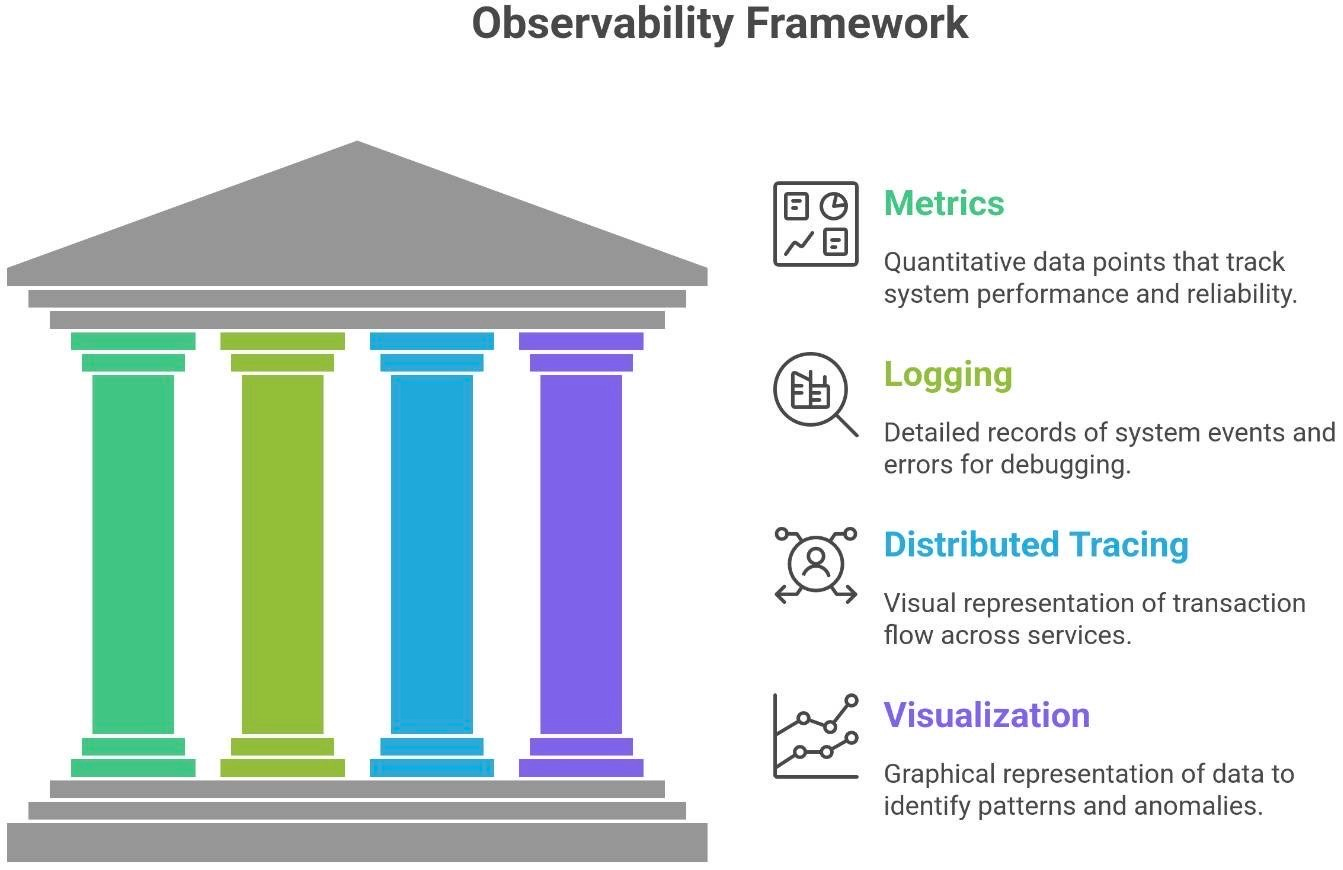
All these resilience patterns (retries, breakers, idempotency) work best when you can see what’s happening inside your system. That’s where observability comes in. Observability means having the right data (logs, metrics, traces) to understand the system’s behavior and catch issues early. It’s the nervous system of your software that lets you sense trouble and react before users are impacted.
You can’t fix what you can’t see. Instrument your system to track the crucial signals:
Metrics: Define and watch metrics that relate to reliability. For example:
Retry counts and rates - how often are retries happening? A spike in retries might mean a downstream service is flaking out.
Circuit breaker state - expose whether the circuit is open, half-open, or closed, and count how many times it opens. If a circuit breaker is tripping frequently, something is wrong downstream (or your threshold is too sensitive).
Error rates and latency - increased error percentage or slow responses can warn of impending failures (which might trigger retries or breaker trips).
Idempotency rejections or duplicates - if you track how many duplicate requests were detected and suppressed, it could indicate clients are retrying a lot (or misbehaving).
Use tools like Prometheus or CloudWatch to collect these metrics. Set up alerts when thresholds are breached (e.g., alert if circuit opens more than X times in an hour, or if retry rate > Y%). A well-tuned alert can notify you of a failing dependency before users start calling support.
Logging with context (Correlation IDs): When errors do occur, logs are invaluable for debugging - but only if you can trace what happened. Implement correlation IDs (also called trace IDs) that flow through your system: from the user request through all the microservices it touches. By logging the ID with every error or important event, you can reconstruct the path of a request. For instance, if a user’s payment failed after 3 retries, you’d see one correlation ID with logs from service A’s retries, and maybe logs in service B if it was reached. Structured logs (JSON logs with key fields like
requestId,userId, etc.) make it easier to filter and search. As an example, a log entry might containcorrelationId: abc-123along with an error message – using that ID you pull all related logs across services. This way, when something goes wrong, you don’t have a needle in a haystack; you have a thread to pull.Distributed Tracing: Traces are like an x-ray of how a single transaction flows through multiple services. Tools like OpenTelemetry (with Jaeger, Zipkin, etc.) allow you to capture timings and causality: e.g., Service A called B, which called C. If a request is slow or fails, a trace can pinpoint where. Maybe 95% of the time was spent waiting on a database call in service C, or maybe service B had a 5-second pause. Tracing lets you visualize that call graph and timings. This is incredibly useful for failures that aren’t obvious - for example, a trace might reveal that your retries are all hitting the same instance of a service that is down, whereas if the load balancer sent one to a different instance it would work (maybe indicating you need smarter retry logic or that a whole zone is down). Many organizations sample traces and have dashboards to see error traces in near-real-time.
Visualization & Dashboards: Platforms like Grafana can chart your metrics over time - you might see a spike in “retry_count” or “circuit_breaker_open{service=B}” on a graph, correlating with a dip in throughput. Dashboards help connect the dots, and when an incident happens, you can quickly assess which part of the system is the bottleneck or failing.
To sum up observability: collect, instrument, and monitor everything important. It’s not just for reacting, but proacting. If you notice a retry storm building or a database getting slower, you can intervene (maybe increase capacity or roll out a fix) before it full-on crashes. Observability is the difference between randomly discovering failures when users scream versus detecting a problem at 3 AM and fixing it before the morning rush.
As a metaphor: Observability is the dashboard in your car with the check-engine lights and temperature gauges. You want to know if the engine is overheating before it explodes, and you want a speedometer to know if you’re going too fast around those reliability curves. Without a dashboard, you’re driving blind. Without software observability, you’re flying blind in production.
In practice, implement basic monitoring on all these resilience mechanisms. Track how many times you are retrying, how long those retries wait, when circuits open/close, and any anomalies with duplicate request handling. Many libraries emit events for these (e.g., Hystrix had a stream of metrics you could tap into). Use that data to continually tune your thresholds too - maybe your circuit breaker is too sensitive (opening on one failure) or not sensitive enough (waiting until 100 failures). Observability guides those improvements.
💬 I’d really love to hear from you.
What part of retry logic, circuit breakers, or idempotency clicked the most for you?
Or - what still feels confusing or “magical”?
Drop a comment below. I respond to everyone, and your questions often inspire new posts I wouldn’t have thought of on my own.
Don’t be shy - this is a friendly corner of the internet. 🙂
⚖️ Failure design as a mindset
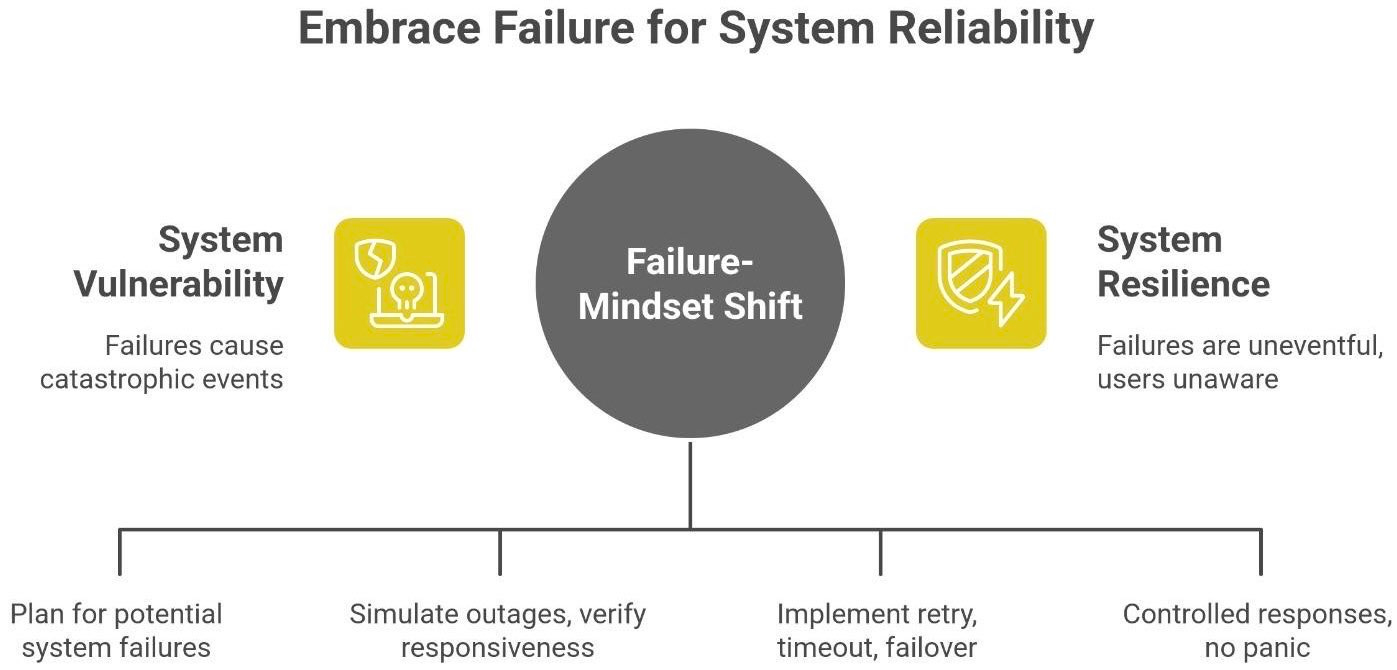
Let’s step back from the technical details and talk philosophy. Building reliable systems isn’t about never making mistakes or preventing every failure. It’s about expecting failures, accepting that they will happen, and designing your system’s behavior in those moments so that nothing catastrophic occurs. In other words, embrace the chaos, but be ready for it.
Think of it this way: if you deploy code to thousands of servers, at any given time something is probably slightly broken. Hard drives crash, networks partition, a bug slips through. A novice might react with “Oh no, everything must be 100% perfect or we’re doomed!” But an expert mindset is, “Failures will happen - let’s make sure when they do, it’s no big deal”. This mindset shift is at the heart of Site Reliability Engineering (SRE) principles at companies like Google. They even intentionally introduce failures (chaos engineering) to test that their systems can handle them.
So, design for graceful failure. It’s an art:
Expect failures: Every external call might not return. Every write to disk might fail. Plan for it.
Embrace them in testing: Simulate random outages or slowdowns and verify your system stays responsive (even if in degraded mode).
Design recovery paths: As we’ve seen - wait, retry, timeout, failover, fallback. Always ask, “If this part breaks, what will the user experience? Can we do better?”
Stay calm under pressure: A good system doesn’t panic when things break. It has that “deep breath” behavior we described. No frantic infinite loops or cascades, just controlled responses.
One great quote that encapsulates this: “The goal isn’t to prevent all failures, but to handle them so gracefully that users never notice”. A perfectly resilient system could be on fire behind the scenes, but from the user’s perspective, it’s running smoothly or only minimally affected. Maybe some features are temporarily limited, or a loading spinner takes a second longer, but the overall service remains available.
In practical terms, this mindset means investing in things like redundancy (so one failure doesn’t take you completely down), graceful degradation (if one component is offline, others still provide value), and automatic recovery (services restart, self-heal, reroute traffic, etc.). It also means not treating the engineers who caused a failure as villains – instead, treat each incident as a learning exercise to improve the system (this is more on the human/process side, blameless post-mortems, etc., but it’s part of the reliability culture).
To conclude this section, let’s re-imagine our opening story with a happier ending: You click “Buy Now”. The payment service does charge your card but fails to respond. The website’s client side has a retry with an idempotency key in place, so it automatically tries again after a moment. The payment service sees the duplicate request, realizes it’s the same transaction, and instead of charging twice, it returns “OK, got it” along with the receipt from the first charge. The website gets the successful response on the second attempt and shows “Order confirmed!” to you. You never even knew there was a hiccup. That’s a failure that was made uneventful - by design.
❤️ If this post helped you understand failure handling in distributed systems, consider sharing it.
It helps more people - especially beginners - discover practical explanations without the gatekeeping.
Sharing the post is one of the best ways you can support my work. Thank you. 🙌
✍️ Summary
We covered a lot, so let’s summarize the key points of how systems handle failure gracefully:
Failures happen constantly in distributed systems - networks glitch, servers crash, messages duplicate. Reliability comes from managing failures, not magically avoiding them. Design your mindset and system with the expectation of failure.
Retries are the first tool to handle transient issues. By retrying operations that might have failed due to a temporary issue, systems can turn flakiness into success. But retries must be used judiciously: apply exponential backoff and jitter to avoid thundering herds. Always cap the number of retries. Done right, retries significantly boost availability (e.g., achieving that extra “nine” of uptime); done wrong, they cause retry storms that amplify outages.
Circuit Breakers act as a safety valve. When a service is consistently failing, the circuit breaker “opens” to stop further attempts, preventing overload and giving time to recover. It’s a protective measure to fail fast and avoid cascading failures. With closed, open, half-open states, circuit breakers can gracefully recover and resume operations once the failures subside. Think of it as the system knowing when to say “enough for now” for its own good.
Idempotency is the unsung hero that ensures retries (and unexpected repeats) don’t cause chaos. An idempotent operation yields the same result no matter how many times it’s performed. By designing APIs and actions to be idempotent (using unique request IDs, deduplication, and careful state management), we make safe retries possible. Idempotency prevents the nightmare of duplicate side effects – no double charges, no extra emails - even if a message or request is processed twice.
Together, these techniques form a self-healing system. Imagine a scenario: a service hiccups, clients retry (thanks to idempotency, without side effects), a persistent failure triggers a circuit breaker to stop the bleeding, and after a pause the system recovers and continues as normal. Each component (retry, breaker, idempotent design) covers a different aspect, and combined they allow a system to withstand failures large and small without collapsing.
Observability underpins all of this. You need to monitor and measure retries, failures, and recovery actions. Metrics, logs, and traces give you the visibility to tune the system and catch problems early. It’s how you verify that your retries aren’t causing harm, or that your circuit breaker isn’t tripping too often. Observability is your early warning system and debugging aid.
Finally, remember that resilience is a mindset and a continuous process. As the saying goes, distributed systems will fail - and that’s okay. Our job is to build systems that “take a deep breath, wait, retry, and carry on” when things go wrong. By embracing failure and designing for it, we create software that doesn’t just avoid crashing, but rather learns to live with failures in a way that users barely notice. That is the art of reliable system design: not preventing rain from ever falling, but carrying an umbrella and wearing waterproof boots so a little rain never stops the parade.
Incredible resource on the invisible safety nets that make modern apps feel reliable. I really appreciate how you link these patterns to that frustrating gray zone, when you're unsure whether your payment went through.
Brilliant breakdown of the messiness behind the scenes! Loved how you framed failure as something to design around rather than fear. Especially liked the metaphor about retries being like knocking with increasing politeness - genius. And you’re absolutely right: retries are only safe when your ops are idempotent. Have you seen any real-world examples where circuit breakers caused unexpected issues instead of preventing them?