
Thinking clearly in interviews — Longest Substring Without Repeating Characters
Understanding the why before the code (Rust · Python · Scala)


⚠️ Before we dive in — a recommendation for makers and builders

The Founders Corner® by Chris Tottman is one of the most practical founder newsletters out there. He writes about turning big ambition into repeatable execution, using frameworks like OKRs and SMART goals, and helping founders think clearly rather than grind blindly.
You’re walking through a busy farmers market with a friend. You agree on a simple rule: “Let’s only buy one of each item”. It sounds easy - until you realize how quickly your basket becomes a messy history of decisions. You pick up apples, then bread, then cheese… and a few stalls later you see apples again. You’re not doing anything wrong; you just forgot that apples were already in the basket.
So you pause. You don’t dump everything and start over. You don’t keep walking pretending the duplicate doesn’t exist. You do something more practical: you look back to the point where apples first showed up, and you adjust your plan so that your “current run of unique items” starts after that. Your basket still contains the past, but your current constraint (“no duplicates”) applies only to the window of choices you’re actively considering.
That little moment - realizing you’re carrying history, but you only need to reason about a moving slice of it - is a surprisingly good model for how a lot of interview problems work. Nothing is broken. The confusion comes from trying to track “everything so far” when the problem only cares about the best contiguous stretch that satisfies a rule.
Problem
Given a string, find the length of the longest substring without repeating characters.
Examples
Example 1:
Input:
“abcabcbb”Output: 3
Explanation: The answer is
“abc”, with the length of 3.Example 2:
Input:
“bbbbb”Output: 1
Explanation: The answer is
“b”, with the length of 1.Example 3:
Input:
“pwwkew”Output: 3
Explanation: The answer is
“wke”, with the length of 3.Note that the answer must be a substring,
“pwke”is a subsequence and not a substring.Constraints
No explicit constraints found in extracted text.
This is exactly the mindset behind finding the longest substring with no repeating characters: keep a clean, up-to-date “current window”, and when a repeat appears, move the start forward intelligently rather than rebuilding from scratch.
🎙️ Why interviewers like this problem
This problem looks simple on the surface: “scan a string and find the longest stretch without repeats”. But interviewers aren’t really testing whether you can write a loop. They’re testing whether you can manage state under pressure, explain an invariant, and avoid subtle off-by-one errors when the input fights back.
A strong solution requires you to recognize a classic pattern: a sliding window where the “valid region” expands and contracts as you scan. That pattern appears everywhere: rate limiting, caching, deduplication, streaming analytics, log processing, and even UI behaviors like “longest recent sequence without repeating events”.
From an interviewer’s perspective, this question reveals:
Whether you can translate an English requirement into a precise invariant. What does “substring” mean operationally? What counts as “repeating”? What does the window represent at every moment?
Whether you can optimize with intent. Many candidates start with a brute force approach and either get stuck or optimize blindly. The best candidates can say: “This is quadratic because we restart work; we need to avoid re-scanning”.
Whether you can communicate while coding. The optimal solution is not long, but it’s easy to get wrong if you can’t narrate what each pointer means.
Whether you handle edge cases calmly. Empty string, repeated characters early, repeated characters far apart, and strings with mixed character sets all stress the details.
It’s also a good “live coding” prompt because it’s small enough to finish, but rich enough to show how you think.
📖 Understanding the problem in plain language
You’re given a string. You want the length of the longest contiguous chunk (a substring) where every character appears at most once inside that chunk.
“Contiguous” is the whole point. You’re not allowed to skip characters. If the string is "pwwkew", the characters p-w-k-e exist in order, but not as one continuous slice, so that doesn’t count.
So the output is a single integer: the maximum length among all substrings that contain no duplicates.
There are a few clarifications worth saying out loud in an interview:
We’re looking for length, not the substring itself (though you can often extend the solution to return the substring).
Characters are considered repeating within the substring, not across the whole string.
The best substring can start and end anywhere. It doesn’t have to align with word boundaries or anything “semantic”.
We should assume the string can be reasonably large unless told otherwise - large enough that an obviously quadratic solution will time out or be frowned upon.
If constraints aren’t provided (as in many prompts), it’s fair to ask: “Should I assume the string can be up to, say, 100k characters?” Interviewers will usually say yes, and that immediately pushes you toward an O(n) solution.
👣 Reasoning through examples
Let’s walk through "abcabcbb" slowly, the way you’d narrate it on a whiteboard.
You start at the first character:
Consider
"a": valid, length 1Extend to
"ab": still valid, length 2Extend to
"abc": still valid, length 3
Now you try to extend with the next character, which is "a" again. If you naively keep growing, you’d have "abca", which is invalid because a repeats.
Here’s the key interview moment: what do you do when you hit a repeat?
A weaker approach is: “Start over from the next character”. That leads to lots of repeated scanning.
A stronger approach is: “I already know where the previous a was. The longest valid substring ending here must start after that previous a”. So instead of restarting from scratch, you slide the start pointer forward to exclude the earlier a.
So for "abcabcbb":
When you hit the second
a(at index 3), you move the start to index 1 (right after the previousaat index 0).Your window becomes
"bca"(indices 1..3), length 3.Then you see
bagain, slide start to after the previousb, and so on.
You keep a running best: it stays 3.
Now consider "bbbbb":
Start with
"b", length 1.Next
brepeats immediately. The best valid substring ending here is still length 1, because the window collapses to just"b"each time.
And "pwwkew" is the example where intuition often fails:
You see
"p", then"pw", then"pww"becomes invalid at the secondw.Sliding the start past the first
wgives you"w"(not"pw"- because you must keep contiguity).Then you extend:
"wk","wke", length 3.
A strong candidate explicitly distinguishes “contiguous substring” from “subsequence” while narrating this. Interviewers love that, because it shows you’re reading carefully.
📏 Constraints and what they tell us
When constraints are missing, you have to infer what the interviewer expects. This is a real interview skill: use the shape of the problem to pick an approach, and confirm assumptions verbally.
There are usually three regimes:
If the string length is tiny (say, under a few thousand), you can get away with
O(n²)brute force. But that’s rarely the intent in a top-tier interview, because it doesn’t test much beyond nested loops.If the string length is moderate to large (tens of thousands or more),
O(n²)becomes risky. A 100k string would be catastrophic with a quadratic approach.If the character set is small and known (e.g., ASCII), you can optimize further using fixed-size arrays. If it’s general Unicode, you typically use a hash map.
So what should you say out loud?
“If the string can be large, we should aim for
O(n)”.“We can do that with a sliding window and a map of last-seen positions”.
“Space is
O(min(n, alphabet_size))because we store at most one entry per distinct character in the window”.
Interviewers want to see you connect constraints to design choices. Even if the prompt doesn’t include them, your reasoning should.
🤔 The obvious first idea — and why it’s not enough
The natural first idea is brute force:
Enumerate every possible start index
i.From
i, expandjforward until you hit a repeated character.Track the maximum length.
To detect repeats, you keep a set of seen characters as you expand j.

This feels good because it matches how humans reason about substrings: “Try starting here, grow until it breaks”.
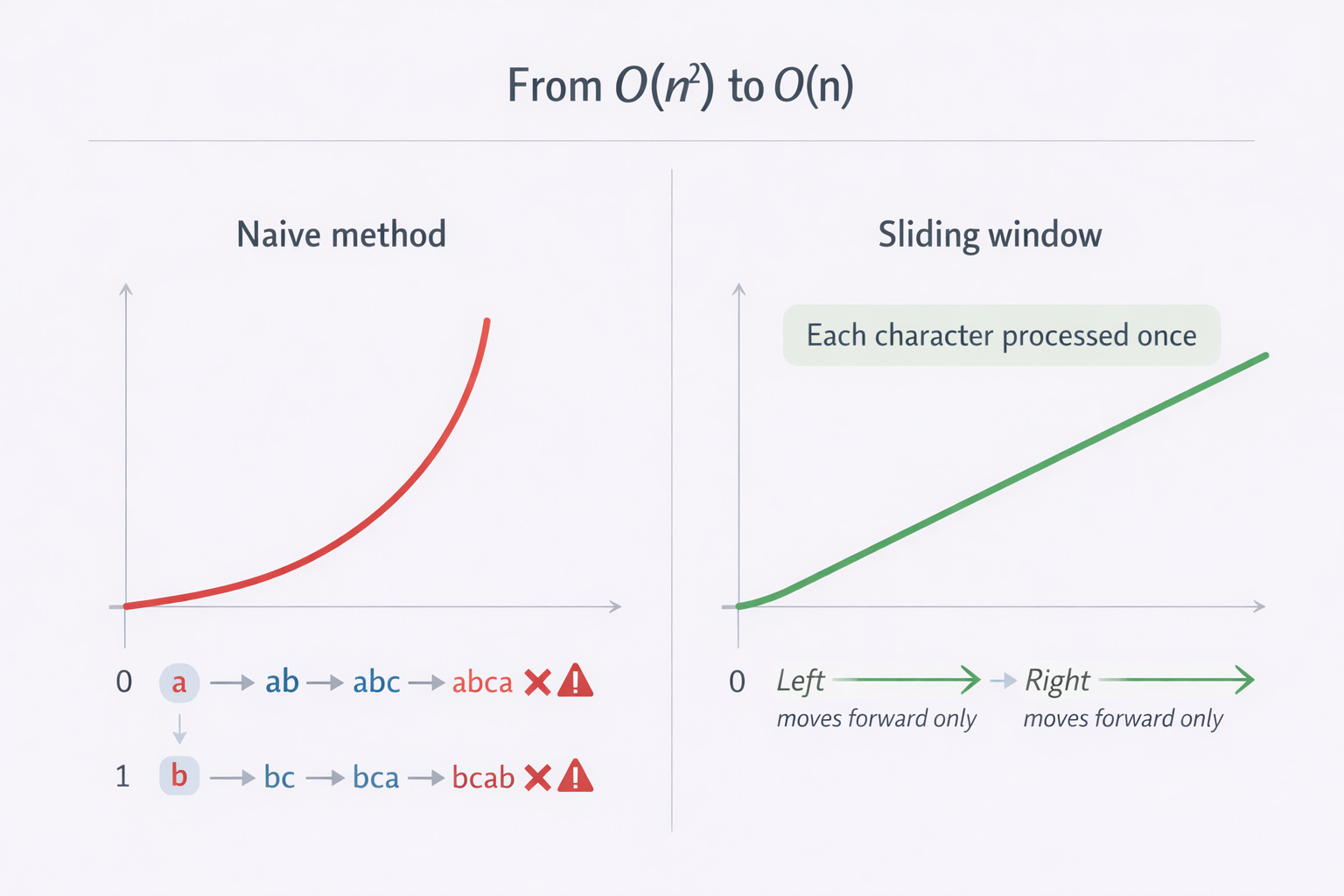
But the performance is the issue. In the worst case - like a string of all distinct characters - this does a lot of redundant work:
From index 0 you scan almost the whole string.
From index 1 you scan almost the whole string again.
And so on.
That’s O(n²) time.
In interviews, the naive approach is not “wrong”. It’s often a perfectly acceptable starting point. What matters is whether you recognize whyit’s inefficient and can articulate the source of redundancy:
“We’re re-scanning the same characters many times”.
“We need a way to move the left boundary forward without re-checking everything inside”.
That statement is the bridge to the real solution.
💡 The key insight
The turning point is realizing that you don’t need to consider all substrings explicitly. You only need to maintain the best valid substring that ends at the current position.
Think of scanning the string left to right with a moving window [left, right] such that:
The window contains no repeating characters.
rightmoves forward one step at a time.When the next character would violate the “no repeats” rule, you move
leftforward just enough to restore validity.
The subtle part - and the part that separates “good” from “strong” - is how you move left.
A common but slightly clumsy version is to move left one step at a time, removing characters from a set until the duplicate is gone. That can still be O(n) overall if implemented carefully, but it’s harder to explain and easier to get wrong live.
The cleaner version uses last seen positions:
Keep a map
lastSeen[c] = indexfor each characterc.When you see character
cat indexright, andcwas last seen at indexk:If
k < left, it’s not a problem (the previouscis outside the window).If
k >= left, it is a problem, and the new valid window must start atk + 1.
So you update: left = max(left, lastSeen[c] + 1).
That one line is the heart of the algorithm. It encodes the idea: “Jump the start forward past the previous occurrence, but never move it backward”.
💡 Did this mental shift click for you?
What was your “aha” moment while reading this?
💬 Leave a comment - I’d love to know how you think about Longest Substring Without Repeating Characters.
⚙️ The final approach
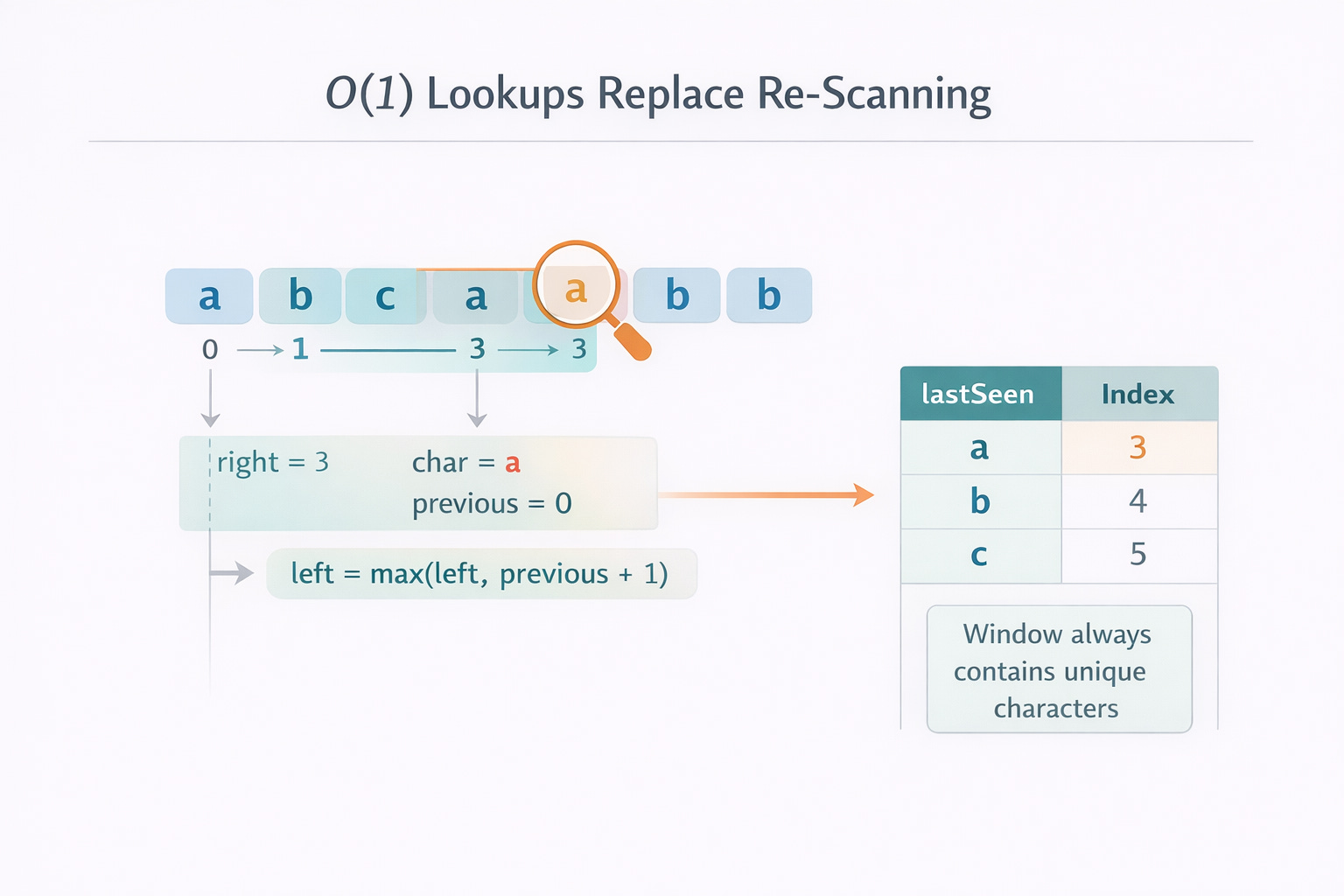
Narratively, here’s what you do:
You walk right from the start of the string to the end. You maintain:
left: the start index of the current window (the best candidate window ending atrightthat has no repeats).lastSeen: a mapping from character to the most recent index where it appeared.best: the maximum window length seen so far.
At each character c = s[right]:
If
chas been seen before at indexkandkis inside the current window (k >= left), then the window is about to contain a duplicate. Slidelefttok + 1.Update
lastSeen[c] = right.Compute current window length as
right - left + 1, updatebest.
Correctness comes from maintaining an invariant:
After processing each position
right, the substrings[left..right]contains no repeated characters.Among all valid substrings that end at
right,s[left..right]is the longest (becauseleftis as far left as possible while staying valid).
Edge cases are naturally handled:
Empty string:
beststays 0.All same character: window repeatedly collapses to length 1.
Repeats far apart:
leftjumps forward, never backward.
This is exactly what you want in an interview solution: simple moving parts, one clear invariant, and no backtracking.
⏱️ Performance under interview constraints
Time complexity is O(n) because each index is processed once, and left only moves forward. The map operations are expected O(1) on average.
Space complexity is O(k), where k is the number of distinct characters you track. In the worst case it can be O(n) if the string has all unique characters, but practically it’s bounded by the character set size.
How do you justify this verbally?
“
rightmoves from 0 to n-1 exactly once”.“
leftonly ever increases, at most n times”.“Each character’s last-seen index is updated once per occurrence; we do
O(1)expected work per character”.
If the interviewer presses on worst-case hash map behavior, a calm response is:
“In practice, standard library hash maps give good average behavior. If the character set is known to be small (like ASCII), we can replace the map with a fixed array to guarantee
O(1)worst-case lookups.”
That’s the kind of trade-off talk that reads as engineering maturity.
⚠️ Know someone preparing for interviews?
Send this to them - it might save them from an avoidable mistake.
🔁 Share this post with a friend grinding interview prep.
💻 Implementation
In interviews, implementation is secondary to clarity of thought - but the code still has to be correct, readable, and robust.
The most common implementation bugs here are:
Updating
leftincorrectly (moving it backward, or not takingmax).Miscomputing window length (
right - leftinstead of+ 1).Confusing “seen ever” with “seen in current window”.
So when you code, keep the structure aligned with the invariant:
Read
right, compute newleftif needed, then updatelastSeen, then updatebest.
🐍 Python implementation
Python is ideal for demonstrating the idea cleanly. Use a dictionary from character to last index.
from typing import Dict
def length_of_longest_substring(s: str) -> int:
last_seen: Dict[str, int] = {}
left = 0
best = 0
for right, ch in enumerate(s):
if ch in last_seen and last_seen[ch] >= left:
# ch repeats inside the current window; jump left past the previous ch
left = last_seen[ch] + 1
last_seen[ch] = right
best = max(best, right - left + 1)
return bestA good way to narrate this while typing:
“
leftis the start of my current unique window”.“
last_seentells me where I last saw each character”.“When I see a repeat inside the window, I jump
leftforward”.“Then I compute the window length and update the best”.
If asked to return the substring itself, you can store best window boundaries (best_left, best_right) when updating best.
🦀 Rust implementation
Rust adds one twist: String is UTF-8, and indexing by position is not allowed because indices are byte offsets, not character offsets. For this problem, we can iterate over chars() and treat “length” as the number of Unicode scalar values processed. That’s typically acceptable unless the interviewer explicitly wants byte-based behavior.
We’ll keep a HashMap<char, usize> storing the last seen character index (not byte index), maintained via enumerate() over chars().
use std::collections::HashMap;
pub fn length_of_longest_substring(s: &str) -> usize {
let mut last_seen: HashMap<char, usize> = HashMap::new();
let mut left: usize = 0;
let mut best: usize = 0;
for (right, ch) in s.chars().enumerate() {
if let Some(&prev) = last_seen.get(&ch) {
if prev >= left {
left = prev + 1;
}
}
last_seen.insert(ch, right);
let window_len = right - left + 1;
if window_len > best {
best = window_len;
}
}
best
}What to say out loud in a Rust interview:
“I’m iterating by
chars(), so my indices are character positions”.“Rust strings are UTF-8, so I avoid direct indexing”.
“Ownership is simple here: I borrow
&str, storecharkeys in the map, and store integer indices”.
If the interviewer wants maximum performance under an ASCII assumption, you can mention an optimization:
Replace the
HashMapwith a[i32; 256]or[usize; 128]array (initialized to sentinel values), which avoids hashing entirely.
🟣 Scala implementation
In Scala, a straightforward approach uses a mutable map and integer indices. Scala’s String indexing uses UTF-16 code units, which is usually what interviewers assume when they say “string” in a typical backend context.
import scala.collection.mutable
object LongestUniqueSubstring {
def lengthOfLongestSubstring(s: String): Int = {
val lastSeen = mutable.Map[Char, Int]()
var left = 0
var best = 0
for (right <- s.indices) {
val ch = s.charAt(right)
lastSeen.get(ch) match {
case Some(prev) if prev >= left =>
left = prev + 1
case _ =>
// no action
}
lastSeen.update(ch, right)
val windowLen = right - left + 1
if (windowLen > best) best = windowLen
}
best
}
}Design choices worth briefly mentioning:
Using a mutable map keeps the code close to the sliding window idea and avoids copying.
You could implement a purely functional version, but it tends to obscure the invariant under interview time constraints.
If you know the input is limited to ASCII, an array of size 128 or 256 is faster and simpler than hashing.
⚠️ Common interview mistakes
The most frequent mistake is forgetting that repeats only matter inside the current window, not “ever”. Candidates will sometimes do:
“If I’ve seen this character before, move left”,
…but without checking whether the previous occurrence is still inside the active window. That breaks cases like "abba".
In "abba", when you reach the last 'a', the previous 'a' is at index 0, but the window might already start at index 2. If you move leftback to 1, you violate the sliding window invariant. That’s why the condition lastSeen[ch] >= left is non-negotiable.
Another classic mistake is updating left without taking max (in variants that compute left = lastSeen[ch] + 1 unconditionally). If you don’t guard against moving left backward, you can “re-include” duplicates and produce inflated lengths.
Off-by-one errors show up constantly:
Window length is
right - left + 1.If you set
left = previnstead ofprev + 1, you haven’t actually removed the duplicate.
Finally, candidates sometimes choose a “remove from set one-by-one” approach and then get stuck in implementation details - forgetting to remove correctly, or accidentally making it quadratic by repeatedly re-scanning. It can be done correctly, but the last-seen-index jump is typically clearer and more robust under time pressure.
🔍 Edge cases interviewers love to ask about
Interviewers often probe whether you truly understand the invariant by throwing targeted cases at you.
An empty string should return 0. This sounds trivial, but it tests whether your initialization is thoughtful or accidental. In many languages, it also tests whether you handle loops that never execute.
Strings with immediate repeats like "aa" or "abba" test the correctness of the left update logic. "abba" in particular is a favorite because it punishes “move left to lastSeen + 1 without checking window boundaries.”
Strings with spaces and punctuation (like "a b!a") test whether you treat “character” broadly, not just letters. In most interpretations, every distinct character counts, including whitespace.
Very long strings test whether your method is truly linear. If you propose brute force, a good interviewer will ask, “What happens at 100k characters?” The best response isn’t panic - it’s a calm complexity argument and a shift to sliding window.
Sometimes you’ll get a follow-up: “Can you return the substring, not just its length?” If you wrote the window logic correctly, this is easy: track the best window boundaries whenever you update best. It’s also an opportunity to show you understand what your variables mean.
Another follow-up: “What if the input is streaming and you can’t store the entire string?” This pushes you to reason about what state you actually need (last seen positions and current index) and how you might handle eviction. It’s not always solvable perfectly without storing something, but the discussion itself reveals engineering judgment.
🎓 What this problem trains you to do
This problem trains a specific kind of interview competence: maintaining a small, precise state that summarizes “everything that matters so far”.
You’re not memorizing a trick. You’re practicing how to:
Define an invariant (“this window is always valid”).
Update state incrementally without recomputation.
Use auxiliary memory (a map) to convert “searching backward” into
O(1)jumps.Explain correctness as a story: “When I see a repeat, the only way to restore validity is to move the left boundary past the previous occurrence”.
Once you internalize that, you start seeing the same shape in many other problems:
Longest or shortest subarray satisfying a constraint.
Counting distinct elements in a window.
Minimum window containing a set of required characters.
Two-pointer techniques on arrays (sum constraints, unique constraints).
Streaming de-duplication with “most recent occurrence” metadata.
More importantly, it teaches you how to stay calm when requirements are deceptively small. The interviewer isn’t asking for heroics. They’re asking whether you can be precise.
🌱 Closing thoughts
The core skill here is resisting the urge to “restart” whenever you hit a problem. In live coding, restarts show up as nested loops, rescans, and tangled conditionals - symptoms of not having a stable invariant.
A sliding window solution is what it looks like when you trust your state: you keep a clear boundary around what’s currently valid, and when reality violates your expectation, you adjust the boundary instead of throwing away your work.
If you practice explaining this problem out loud - what left means, why left never moves backward, and how lastSeen prevents rescanning - you’ll notice a shift. You stop sounding like someone searching for a solution and start sounding like someone executing a plan.
🧠 If you want to build real interview intuition…
I write deep, calm breakdowns of classic problems - without tricks or memorization.
📬 Subscribe to get the next one directly.