
How systems find each other — Service Discovery without magic
System design fundamentals


Imagine throwing a party - fifty guests, all arriving at different times.
Some leave early, others show up late. The address changes mid-party.
Yet somehow, everyone still finds the right house.
That’s the miracle of Service Discovery - systems finding each other in a world that’s constantly moving.
In a distributed system, finding the “right house” is an everyday challenge. Services are like party guests constantly coming and going. Addresses change (containers restart, servers autoscale, IPs reassign) but somehow everything still works. How? The answer is service discovery. In essence, service discovery is what keeps order in chaos, ensuring that even when locations are fluid, the connections between services remain solid. In the following sections, we’ll demystify service discovery, showing that it’s not magic at all - just smart engineering that lets services continuously find each other in a changing world.
🧩 The problem — nothing stays still in Distributed Systems
In a traditional monolithic application, every function call or component interaction happens inside one process or on one machine. Locating another part of the system is straightforward because everything lives together. There’s no question about “where” a component is - it’s in the same binary or server, so calling it is as simple as a function call.
Enjoying the metaphors so far? I write posts just like this - breaking down tech concepts with plain language and real-world comparisons.
💡 Want more like this delivered to your inbox?
In microservices (and other distributed architectures), nothing stays still. Services are split out across many processes or containers, often across many hosts. These service instances come and go dynamically. Auto-scaling might spin up new instances on the fly; new deployments replace old versions; if something crashes, it might be restarted elsewhere. In cloud environments, even the network identifiers are ephemeral - containers or VMs often get random IP addresses assigned at start, which can change next time they run.1 The number of instances isn’t fixed either; it can change based on load or schedule.
Now, if you’re a service that needs to call another service, you can’t rely on a hard-coded IP or hostname, because that might be outdated the moment it’s deployed. Hardcoding addresses in config is brittle and practically impossible to maintain in a microservices ecosystem.2 Imagine trying to keep track of 50 party guests whose addresses keep changing - that’s what it’s like in a dynamic system. The pain point is clear: in distributed systems, location is fluid. What was “here” yesterday might be gone or moved today.
Insight: Service Discovery exists because addresses are temporary - but relationships are permanent. The identity of the service (like “User Service” or “Order Service”) remains, even though its location keeps changing. We need a way to call “User Service” without caring about its current address. In other words, find the who no matter where it is now.
⚙️ What is Service Discovery (really)?
Let’s define it in simple terms. Service Discovery is how systems dynamically find and connect to each other on a network. Instead of calling a service at a fixed, known address, a service will ask a central system: “Where is the User Service today?” - and get back the current location (IP and port, for example) of an instance of that service. This means the caller doesn’t need to know in advance where the target service lives; it only needs to know the target’s name or identity, and the discovery mechanism provides the real address at runtime.
At its core, service discovery is a level of indirection that separates who you want to talk to from where they are right now. You request by a logical service name or key, and the discovery system returns the actual endpoint. This is analogous to how we use a phone’s contact list: you don’t remember the exact phone number (which might change), you just tap on “Mom” or “Alice’s Pizza” and the phone figures out the current number to dial. The number could change behind the scenes (new SIM card, updated contact info), but you don’t care - you just want to reach Mom. Similarly, a service just wants to reach “User-Service” without hardcoding its address.
To illustrate, consider a real example from a microservice framework: in a Spring Cloud/Eureka setup, one service can simply use the logical name of another. For instance, an authentication service might call “USER-SERVICE” (the name) instead of a URL; Eureka will resolve that name to an actual host:port at call time.3 The developer writes code against a service name, and service discovery takes care of mapping it to the current address. This makes the system flexible - services can be redeployed, moved, scaled, or replaced, and as long as they register themselves under the same name, other services can still find them.
In short, service discovery is the automated “phonebook” of distributed systems. It answers the ever-important question: “Where is service X right now?” and it answers it reliably even as the answer keeps changing over time.
🧠 The two flavors — Client-Side vs. Server-Side Discovery
There are two primary models of how service discovery is implemented: client-side discovery and server-side discovery. Both achieve the same goal (routing a request to an available service instance), but they split responsibilities differently between the service client and the network infrastructure.
In client-side discovery, the client is “smart”. It knows about the service registry. For example, a microservice might use a discovery library (such as Netflix Ribbon with Eureka or a Consul client) to ask the registry for all live instances of “User Service”, then apply some load balancing algorithm (random, round-robin, etc.) to choose one instance and send the request directly to it. The client contains the discovery logic. The upside is there’s no extra network hop – the client talks straight to the target. The downside is every client must implement the discovery mechanism and keep the registry up-to-date (which typically means pulling updates or subscribing to changes).
In server-side discovery, the client is simpler – it just knows to send requests to a fixed address (for example, a load balancer URL or a proxy) and that component will do the discovery. The logic lives on the server-side component (like a reverse proxy, API gateway, or dedicated load balancer). When a request comes in, the load balancer looks up where to send it - essentially performing the discovery lookup on behalf of the client - and then forwards (proxies) the request to one of the service instances. AWS Elastic Load Balancer (ELB) works this way: your service client just calls “http://my-service.loadbalancer.aws” and ELB ensures it routes to one of the actual servers behind it. Kubernetes Services (the built-in kind) also behave like a server-side discovery mechanism: each Service gets a stable IP or DNS name, and behind that facade Kubernetes will direct traffic to one of the pods that currently implement that service.
Client-side: Client → (Service Registry lookup) → Directly to Target Service
Server-side: Client → (Load Balancer/Proxy) → Target Service (after LB does lookup)The diagram above shows the difference in call flow. In summary:
Client-side discovery makes the client responsible for figuring out service locations. The client must query the registry and decide which instance to use. This requires a bit more sophistication in each client service, but avoids an extra network hop. Many open-source systems like Netflix Eureka or HashiCorp Consul operate in this mode, often with client libraries that applications include to integrate with the registry.
Server-side discovery offloads that work to a dedicated component (often part of the infrastructure). The client just hits a fixed endpoint and the network “smartly” routes the call to a service instance. This is convenient for clients (they just call a static address), but introduces an extra component that must scale and stay available. Examples include cloud load balancers (AWS ELB, Nginx or HAProxy with service discovery plugins) and Kubernetes’s internal service VIPs or service mesh proxies.
Client-side: Client → (Service Registry lookup) → Directly to Target Service Client-side service discovery. The diagram above illustrates client-side discovery: the client first queries a service registry to get the current list of server instances for a given service. Then the client picks one of those instances (often using a load-balancing strategy) and sends the request directly to that instance. In this model, the client is aware of the discovery system. Netflix’s Eureka is a classic example supporting client-side discovery - applications use a Eureka client to ask the registry for service addresses. Similarly, HashiCorp Consul can be used client-side via DNS or HTTP APIs: the application itself looks up the service’s address and connects to it.
Server-side: Client → (Load Balancer/Proxy) → Target Service (after LB does lookup)Server-side service discovery. The diagram above shows server-side discovery: the client sends its request to a fixed load balancer (or proxy) address. The load balancer (acting as a smart router) then consults the service registry or its own mapping of healthy instances and forwards the request to one of the service instances. The client doesn’t need to know anything about the service registry or where instances are - it just knows the address of the load balancer. Kubernetes implements this pattern with its Service abstraction (and kube-proxy), giving each service a stable IP/hostname and distributing incoming requests to available pods. Traditional hardware or software load balancers (like F5, Nginx, HAProxy) can also do service discovery by periodically polling a registry or receiving updates, so they always know where to route traffic.
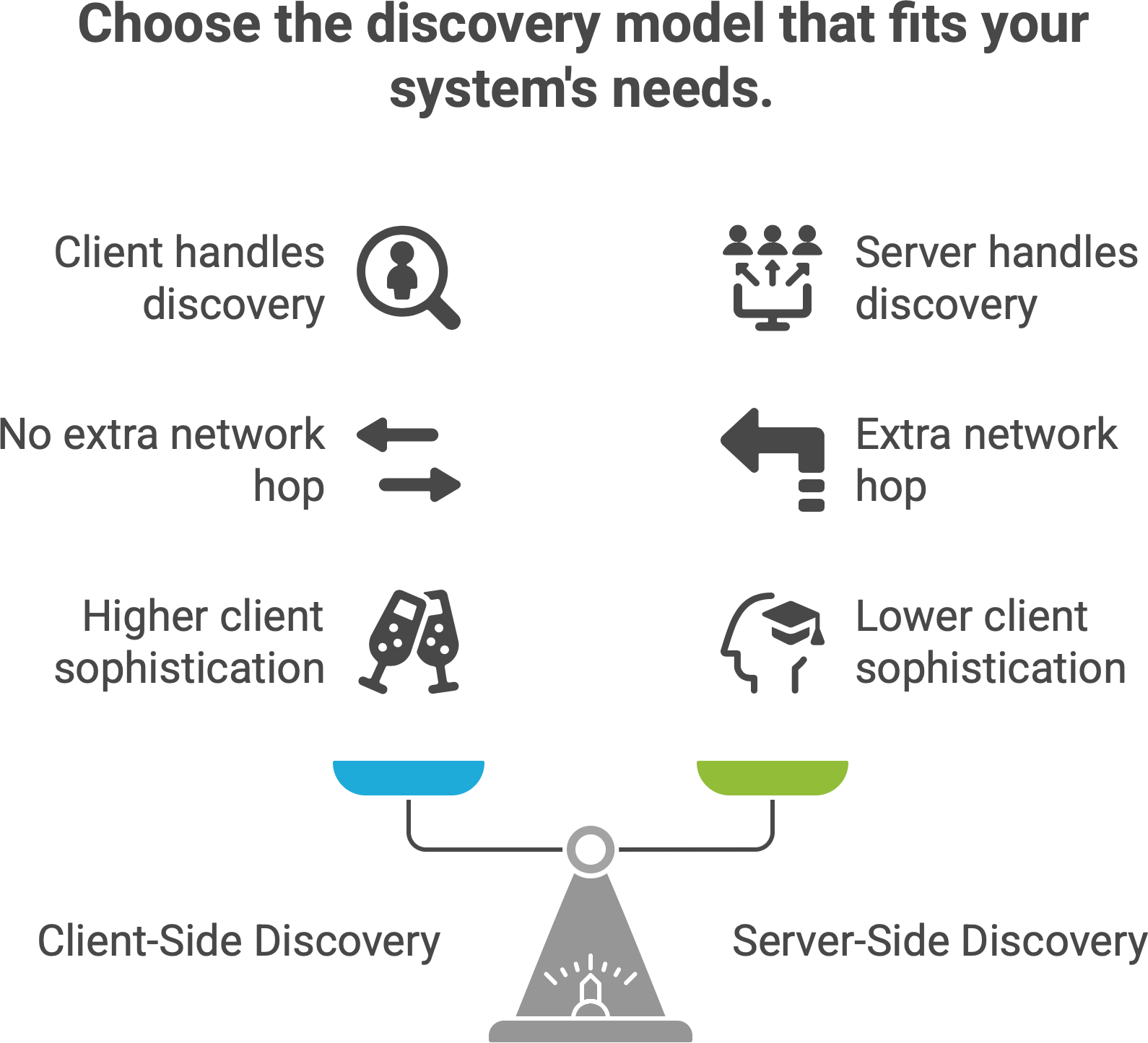
The key trade-off between the two flavors: In client-side discovery, the intelligence lives with the client (each service that calls others must handle discovery logic). In server-side discovery, the intelligence lives in the network (the platform or an intermediary handles discovery for you). Both models can achieve high availability and load balancing; which to use often depends on your ecosystem and tooling. In practice, systems like Kubernetes or service mesh proxies have made server-side discovery very popular (since the platform automates it), whereas libraries like Eureka or Consul’s API made client-side popular in early microservice architectures (like Netflix’s). Many environments actually use a mix – for example, a client might do a DNS lookup (kind of a discovery) which is served by a service mesh sidecar proxy (server-side pattern internally).
The end goal is the same: the caller gets connected to a living, healthy instance of the target service.
🧮 The heart of discovery — the service registry
Whether client-side or server-side, almost every service discovery system revolves around a service registry. This is the heart of discovery: a database (or directory) that holds the locations of services and keeps track of which instances are available. Think of the registry as a dynamic phone book for all the services in your system - one that is constantly updating itself.
So how does it work behind the scenes? When each service instance starts up, it registers itself with the registry. It provides details like its identity (service name), address (IP and port), and perhaps other metadata (like what version it is, or a health check endpoint). For example, if we have a User Service, when a new instance of User Service launches, it will announce “I am User-Service instance, and I’m listening on 10.1.2.3:8080” to the registry. The registry records this entry in its database.
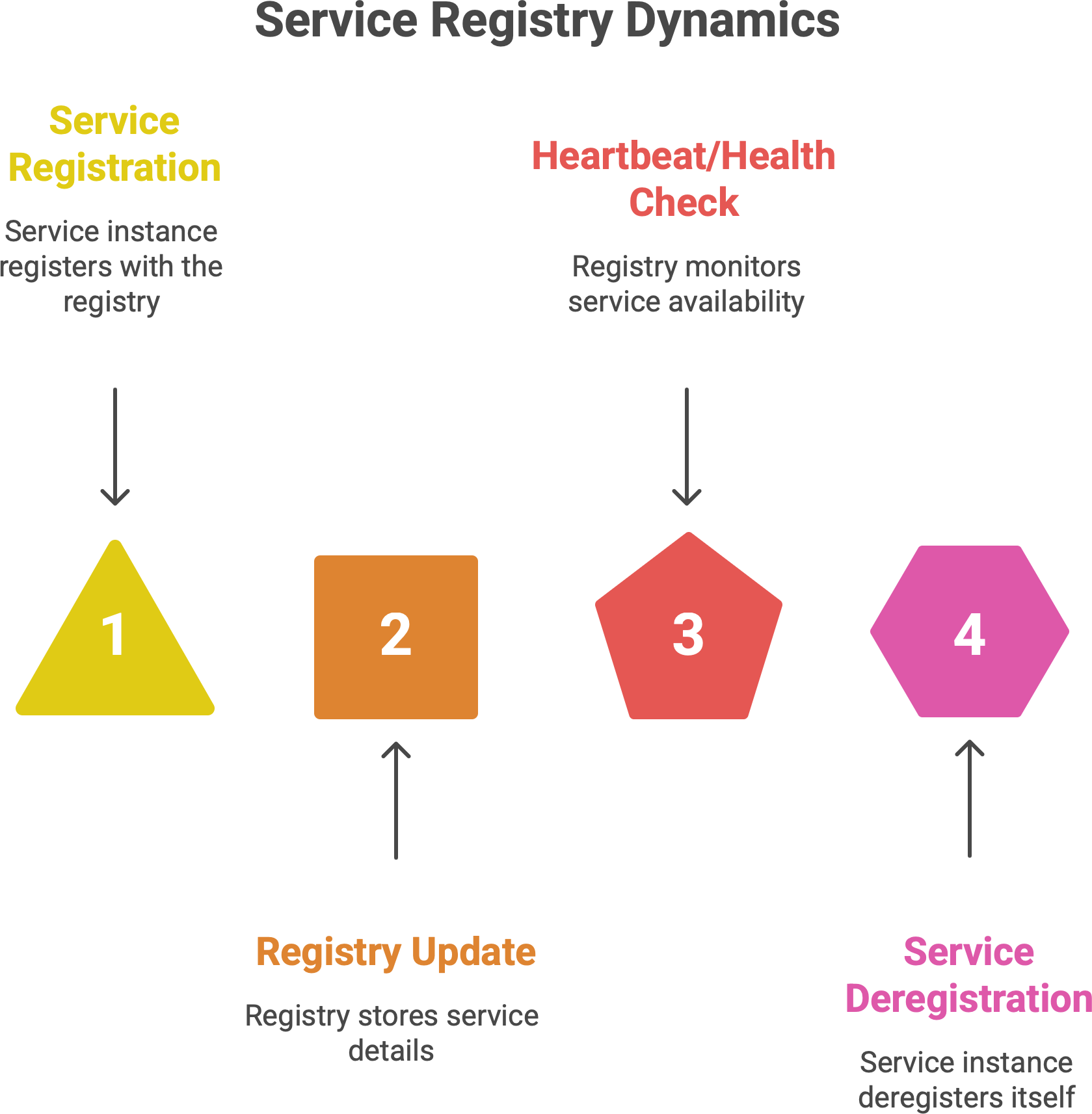
The registry isn’t just a static database; it’s actively maintained. Service instances typically renew their registration periodically (like a heartbeat) or the registry calls them to check if they’re still alive (more on health checks in the next section). When a service shuts down normally, it deregisters itself - essentially saying “take me off the list”. If a service crashes or is unreachable, the registry will notice via missing heartbeats or failed health checks and remove that entry after a grace period. This way, the registry always aims to have a fresh list of who’s out there and healthy.
Now, when another service (a client) needs to find, say, User Service, it queries the registry: “Give me the instances for User-Service”. The registry replies with the current list of active instances and their addresses. The client can then use one of those addresses to make the call. If no instances are available, the registry could return an empty result or an error, and the client knows the service is (temporarily) unavailable.
Some popular service registry implementations and tools include:
HashiCorp Consul – a distributed key-value store and registry that supports health checks and offers both REST and DNS interfaces for discovery.
Netflix Eureka – part of Netflix’s open-source suite, a registry service where clients (usually with a Java client library) register and discover services. Eureka clients also use a heartbeat mechanism to stay registered.
etcd – a distributed key-value store (by CoreOS) that underpins Kubernetes. Kubernetes uses etcd to store all cluster data, including service information for discovery. In Kubernetes, you typically don’t interact with etcd directly, but it’s the source of truth for service endpoints.
Apache Zookeeper – an older but rock-solid distributed coordination system, often used in the past for service discovery and configuration in systems like Hadoop or older microservice frameworks. It maintains a hierarchical data store of service names and addresses and can notify watchers of changes.
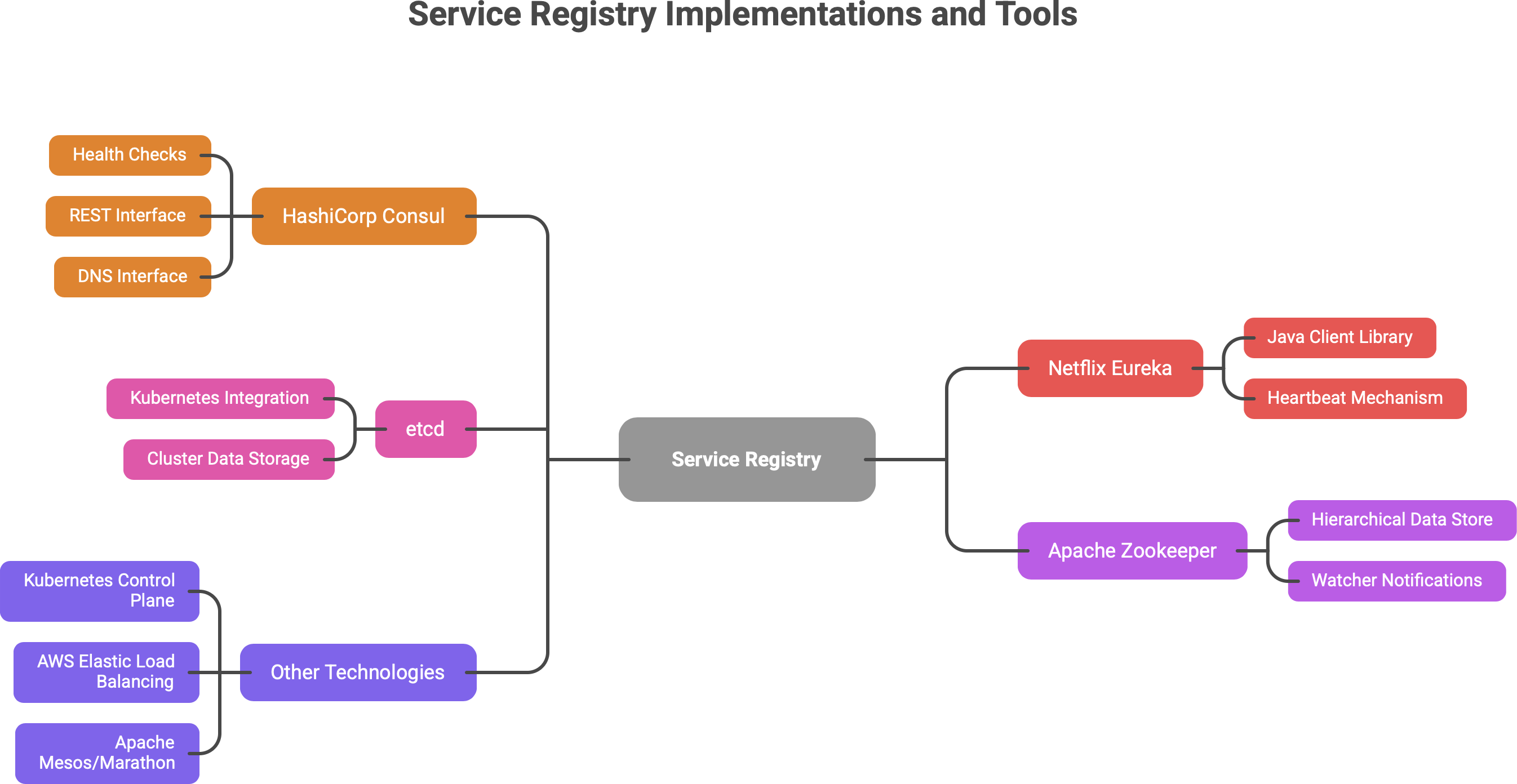
Other technologies and platforms have their own registries: for instance, Kubernetes doesn’t expose etcd directly to you for service discovery, but it effectively has an internal registry of services and endpoints (the Kubernetes control plane ensures that). AWS’s Elastic Load Balancing and ECS have a form of implicit registry (you register instances in a target group). Similarly, systems like Apache Mesos/Marathon had service registries. The pattern is universal – there’s always a repository of service locations somewhere.
🛠️ Which tools are you using?
Have you tried Consul, Zookeeper, or maybe you’re wrestling with AWS’s ELB quirks? I’d love to hear your thoughts, questions, or stories from the trenches.
Think of the registry as a phone book that updates itself every second. It’s the authoritative source that knows “what lives where” at any given moment. Without it, every service would be shouting into the void, or we’d be back to the bad old days of maintaining long lists of IP addresses in config files (which would never stay accurate). The service registry gives us a single source of truth for service locations, and service discovery is basically every participant agreeing to use that source of truth to find each other.
🔍 Health Checks — knowing who’s alive
Finding a service is one thing – but finding a working service is another. If our registry simply kept every service that ever registered listed forever, it would quickly accumulate stale entries (dead instances) and mislead clients. That’s why health checks are a crucial part of service discovery.
A health check is a simple probe (often an HTTP GET to a /health endpoint, a ping, or a heartbeat signal) used to verify that a service instance is alive and functioning. Service registries use health checks to keep their data accurate:
Active heartbeats: Some systems (like Eureka) have the service instances periodically send heartbeats to the registry. If heartbeats stop, the registry marks the instance as dead after a timeout.
Pull health checks: Other systems (like Consul, Zookeeper) have the registry actively ping or check each service at intervals. For example, Consul can be configured with a health check command or HTTP check for each service; if the check fails, Consul will flag that instance as unhealthy.
Integration with orchestration: In platforms like Kubernetes, health status is often integrated – if a pod fails its liveness or readiness probes, Kubernetes can remove it from service endpoints. That information propagates to discovery (so DNS won’t include a failing pod, etc.).
The result is that the registry (or discovery system) maintains a list of healthy instances. When a client asks for a service, it ideally only gets back instances that are up and passing health checks. If an instance goes down unexpectedly, the health mechanism ensures it will be removed from the registry, often within seconds. Conversely, when an instance comes back or a new one is added, it will start passing health checks and get included.
Without health checks, service discovery would be giving out potentially bad phone numbers - you’d call, and nobody picks up. It would be like having a phone book full of businesses that have shut down; you keep dialing dead lines. Thus, any robust discovery system pairs registration with monitoring of health. Some registries allow a grace period or a TTL (time-to-live) for registrations - a service must renew before the TTL expires or it’s assumed dead. Others use push-based failure detection. The end goal is the same: only live services should be discoverable.
One more aspect is health metadata - sometimes an instance is alive but not healthy to serve (e.g., it’s overloaded or in maintenance mode). Advanced discovery setups propagate health states (like “passing”, “warning”, “failing”) so that clients can decide to avoid instances that are in warning state, etc. But for most cases, it’s a binary: in or out.
So, service discovery is continuous. It’s not a one-time mapping of names to addresses – it’s an ever-evolving directory. Registries continuously reconcile the real world (which instances are up) with their internal records. This dynamic nature is what makes service discovery powerful: it turns an unpredictable, changing network into something applications can trust, by constantly expiring and refreshing information. As one source neatly put it: discovery without health checks would leave you “with a phone book full of disconnected numbers”, which isn’t very useful.
🌐 Discovery in the cloud-native world
Modern cloud-native platforms have made service discovery almost invisible to developers. If you use Kubernetes or a similar orchestration system, you might be using service discovery features without even realizing it - it just feels like the platform magically makes services reachable by name. But under the hood, it’s the same principles we’ve discussed.
Take Kubernetes for example. In Kubernetes, when you deploy a set of pods running “User Service”, you typically define a Service object (let’s say named “user-service”). Kubernetes will allocate a stable virtual IP address for that Service (within the cluster) and set up a DNS name like user-service.default.svc.cluster.local (assuming it’s in the “default” namespace). Now any other service in the cluster can simply refer to
http://user-service (Kubernetes’ DNS can shorten the full domain) and get routed to one of the pods. It feels like magic – you didn’t personally implement a registry or a lookup – but Kubernetes did it for you.
What’s happening behind the scenes? Kubernetes uses a few cooperating components for discovery:
Etcd as registry: Kubernetes’ control plane (specifically the API server) uses etcd as its backing store for all cluster data. This includes the endpoints for each service. Whenever pods come and go, the Kubernetes controllers update the list of endpoints for a Service (which is stored in etcd).4 In essence, etcd is the service registry, keeping track of which pod IPs are tied to “user-service” at any time.
DNS and environment variables: Kubernetes runs an internal DNS service (like CoreDNS) that watches for service changes. It automatically creates DNS A records so that
user-service.default.svc.cluster.localmaps to the Service’s cluster IP. It also can inject environment variables into pods (likeUSER_SERVICE_SERVICE_HOST=10.3.245.7) giving another way to find the service IP. This means as a developer you can just use the service name and trust that DNS will resolve it to the right IP.Kube-proxy or networking for routing: The cluster IP itself (and corresponding DNS name) is virtual – it’s handled by
kube-proxyon each node (or by advanced routing in newer implementations like kube-proxy IPVS or Cilium). Kube-proxy maintains iptables or IPVS rules that map the Service IP to the set of current Pod IPs for that service. When you hit the Service IP, the request gets load balanced to one of the pod endpoints that’s actually alive. If pods are added or removed, kube-proxy updates the rules. This is server-side discovery internalized: your request goes to a stable IP, and the cluster networking finds an appropriate instance.
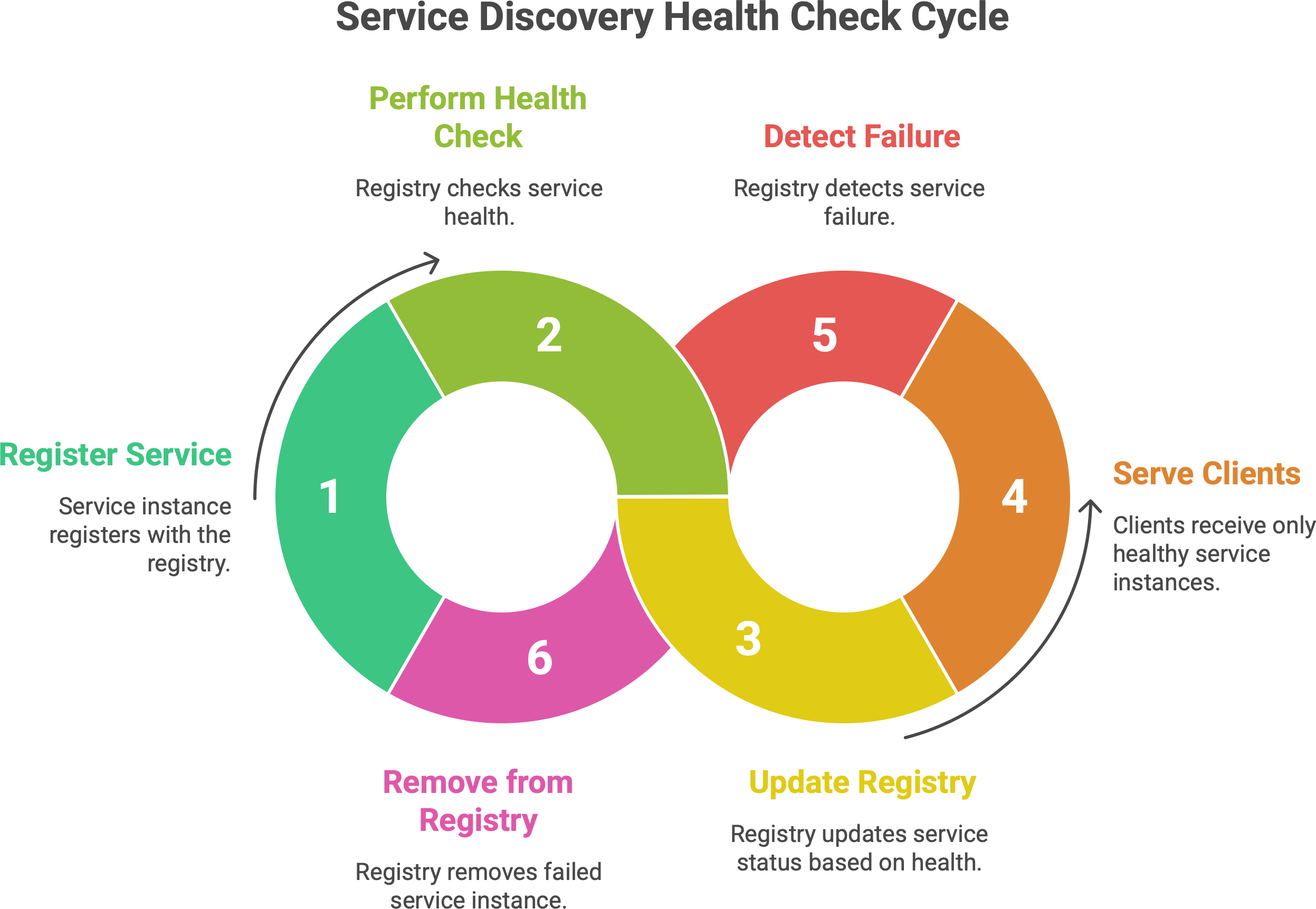
The upshot is that the platform handles registration and discovery for you. When a new pod comes up, Kubernetes will automatically add it to the endpoints of the Service (registering it). If a pod dies, it’s removed. Health checks (readiness probes) integrate so that if a pod is not ready, it’s temporarily removed from endpoints. All of this happens without the service authors writing any discovery code. You just name the service you want to call, and Kubernetes ensures that name resolves to something that works. It’s the same idea of service discovery, but baked into the infrastructure as an automated, built-in feature.
Service meshes (like Istio, Linkerd, etc.) go even further. They often leverage the existing discovery (from Kubernetes or another system) but add a layer of proxies that can do more intelligent routing (like per-request load balancing, traffic shifting, etc.). Even in those cases, the fundamental discovery (knowing what instances exist for a service) still often comes from the service registry (e.g., Istio taps into Kubernetes’ service registry and adds its own logic on top).
To give a concrete example: imagine our User Service in Kubernetes. If it’s scaled to 5 pods, the Kubernetes registry (etcd) knows there are 5 endpoints. The DNS name user-service.default.svc.cluster.local will resolve (round-robin or via kube-proxy VIP) to one of those pod IPs. From our perspective, we just do GET http://user-service:8080/api/profile and we reach one of the five pods. If we deploy a new version of User Service (blue-green deploy) under the hood Kubernetes might switch the endpoints to 5 new pods and remove the old 5 – but as a caller, you still hit user-service and magically get the new pods. No code change, no manual update – discovery handled it. It’s “magic” in the sense that you don’t have to think about it, but underneath it’s the same machinery: a constantly updated mapping of service name to instance addresses.
➡️ Mini insight: In modern cloud-native systems, what feels like “magic” is really just automation doing the tedious work for you. Service discovery in Kubernetes (and similar platforms) is essentially automated service registry + automated client or server-side discovery. You could do it yourself, but you don’t have to, because the platform engineers have done it once in a generic way for everyone. The principles remain the same: separate naming from addressing, keep track of health, update everyone’s “phone book” continuously.
🧩 When things go wrong
Service discovery makes distributed systems feasible, but it doesn’t make them infallible. Like any distributed system component, a service discovery system can experience issues. It’s important to be aware of common failure modes and challenges:
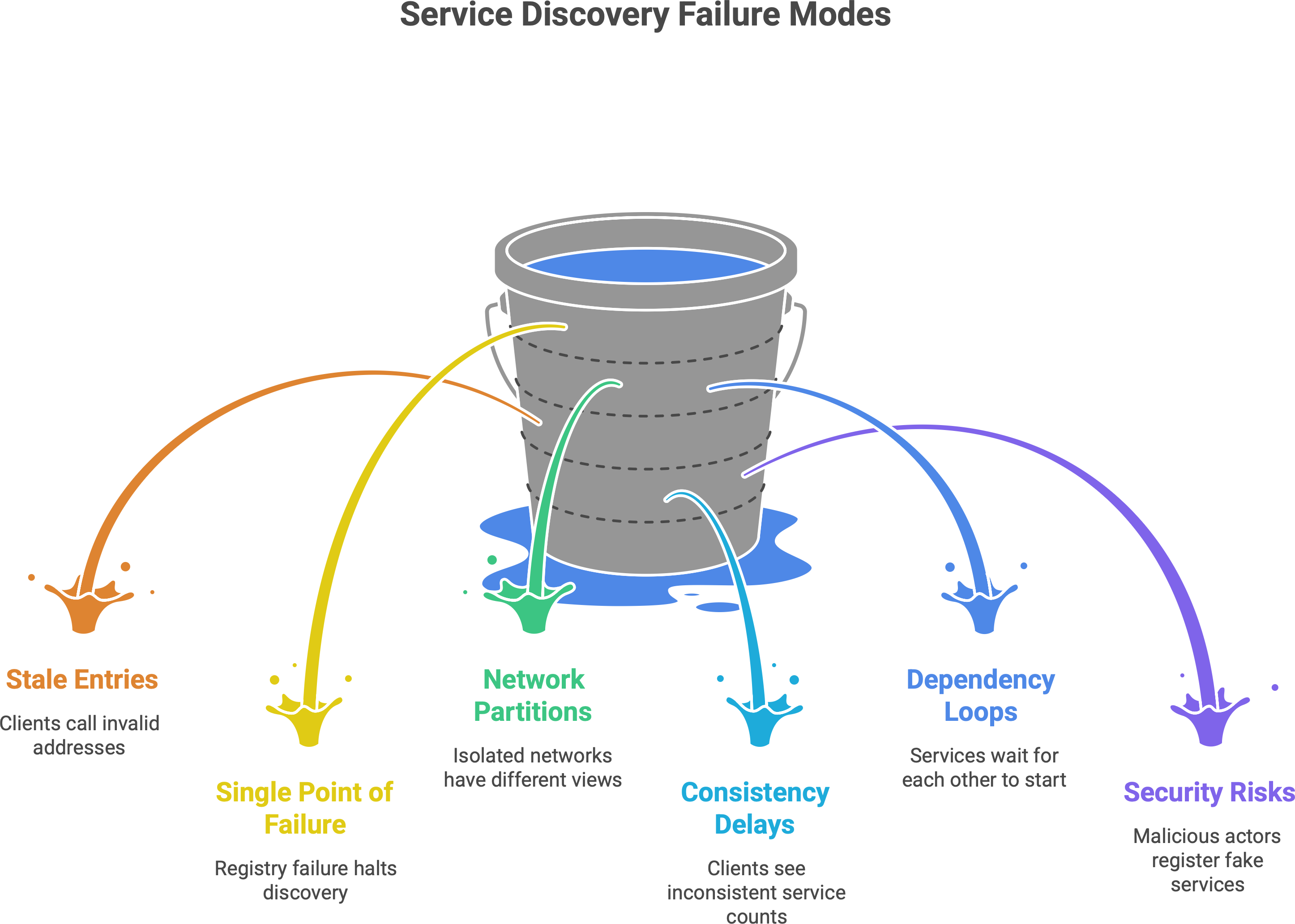
Stale Entries: There’s a period of time between a service going down and the registry noticing. If that interval is too long (or if heartbeats/health checks fail to promptly remove a dead instance), clients might still be sent to an address that’s no longer valid. This results in errors when calling a service that is actually down. For example, if a registry has a long TTL or a health check that runs once a minute, there could be up to a minute where a dead service is still “discoverable”. The solution is to use aggressive health checks and shorter TTLs so that information is refreshed quickly. Still, a balance is needed: make it too short and you might flap or remove instances that have brief hiccups. Tuning is key.
Single Point of Failure / Overloaded Registry: The service registry itself is a critical component. If the registry goes down, the whole discovery mechanism grinds to a halt (at that point, services can’t find each other, except through perhaps cached data which will become outdated). Also, if the registry is under heavy load (imagine hundreds of services registering and hundreds of clients querying every second), it can become a bottleneck. That’s why registries must be designed to be highly available and scalable. Typically, they are run as clusters themselves (e.g., multiple Consul servers, Eureka in cluster mode) to avoid a single point of failure. Caching on the client side can mitigate read load – many discovery libraries cache the last known good addresses for a service and fall back to them if the registry is momentarily unreachable. But ultimately, you need to treat the registry like an absolutely critical infra component (because it is). If it fails or lags, it’s like the phone book is missing pages or not updating – chaos can ensue.
Network Partitions: In a distributed system, sometimes parts of the network can become isolated (the dreaded “split brain” scenario). In such a case, you might have partitioned views of service discovery. For example, half of the instances and half of the clients can’t reach the other half. Each side might have a registry that thinks the other side’s services are down. This can lead to situations where services that are actually healthy (on the other side of the partition) are seen as unavailable. Or worse, when the partition heals, two registries might have conflicting data. Robust systems handle this with techniques like zone-aware routing (so clients prefer local instances), or by ensuring the registry has a consistent view when partitioned (which often devolves to choosing one side as the source of truth). Network partitions are tricky – essentially, if your discovery mechanism itself is distributed, it has to deal with consensus and partition tolerance (per the CAP theorem). Zookeeper, for instance, will refuse to operate if it loses quorum (to avoid serving stale data). Eureka by default is more AP (available), which means it might serve stale data during a partition rather than be unavailable.5 There’s no silver bullet; it’s the classic trade-off.
Consistency and Convergence Delays: In larger systems, there may be a slight delay from the moment a service registers/deregisters to the moment all clients become aware. If your registry uses a push model (e.g., it notifies clients or a sidecar of changes), there’s propagation time. If clients poll periodically, there’s a window of staleness. Usually these delays are seconds or less, but in extreme cases they can cause brief inconsistencies (one client thinks there are 5 instances, another thinks 4). Most of the time this isn’t a huge problem (a request might fail and then retry and succeed), but it’s good to design with the expectation that discovery info is eventually consistent rather than instantly consistent.
Dependency Loops: This is more of an architectural pitfall – if Service A and Service B depend on each other to start up via discovery, you can get a deadlock. For example, Service A won’t register as ready until it talks to B, and B won’t start until A is available. If both are waiting on discovery, they’ll wait forever. This is not the registry’s fault per se, but a usage pitfall. The way to avoid it is to design services such that there aren’t circular startup dependencies (or break the loop with some timeout or default behavior). It’s like two friends each waiting for the other to call first – sometimes someone has to just proceed.
Security and Trust: If not properly secured, a malicious actor could potentially register fake services or deregister others. Real-world service registries often have authentication and ACLs, and in zero-trust environments, discovery info might be distributed via secure channels. This isn’t a “when things go wrong” in the failure sense, but it’s a risk if not addressed. After all, if the phone book can be tampered with, you might call the wrong number (and that number might be an attacker).
To sum up, service discovery systems are themselves distributed systems. They have to be designed with failure in mind. As one metaphor would put it: even the best p
hone book is useless if the printing press fails halfway (or if the post office loses half the pages). In practice, solutions include running multiple registry servers (with consensus or leader election), client-side caching and fallbacks, health check tuning, and partition-aware setups (like multi-region registries that sync gradually). The good news is that mature solutions like Consul, Eureka, etcd, and Zookeeper have thought through many of these edge cases – but as an engineer, it’s still wise to be aware of them when designing your system’s architecture.
💬 Service Discovery as a philosophy
At this point, we’ve covered the mechanics of service discovery. Let’s step back and view it from a higher altitude – almost philosophically.
In a way, Service Discovery isn’t magic - it’s trust. It’s a silent agreement among all the services in a system, a sort of social contract of software: “I’ll tell you where I am, if you promise to remember and find me when I move.” Every service that comes online says “Here I am, here’s how to reach me.” The discovery system (and by extension all the other services) replies, “Got it. We’ll keep track. If you go away or relocate, just let us know (or we’ll find out), and we’ll adapt.”
This mutual trust – that services will announce themselves and the system will faithfully keep that information up-to-date – is what allows order to emerge from chaos. In a vast sea of ephemeral instances popping in and out of existence, service discovery is the handshake that keeps everything coordinated. It turns what would be a cacophony of “hello, where are you?” into a well-orchestrated conversation.
In practical terms, service discovery embodies the principle of loose coupling. Services don’t need to know the internal details or exact location of others, only a stable identity. It’s like focusing on who you need, not where they are. This decoupling of identity from location is deeply powerful – it underpins the scalability and resilience of microservices. You can deploy a hundred instances or scale down to one, move them across data centers, upgrade them, or take them down for maintenance, all without breaking the contract. As long as you uphold the discovery protocol (register/unregister or pass health checks), the rest of the system will gracefully adapt.
So, beyond the technicalities, think of service discovery as the invisible glue or the neural network of your architecture’s brain. It’s constantly sensing and communicating changes in the system’s topology so that every part knows how to reach every other part. It is, fundamentally, about ensuring connectivity in a fluid world. It’s not magic at all – it’s solid engineering – but from the outside it can sure feel magical that no matter how much things move around, nothing gets lost.
In summary: Service discovery is the unsung hero that turns chaos into coordination — the invisible handshake that keeps distributed systems together.
Know someone who’s just getting into backend development or cloud architecture
If this post helped you, pass it along - help them level up too. 👇
✍️ Summary
In distributed systems, nothing stays put. Unlike a monolith (where everything’s in one place), microservice instances are constantly changing – scaling up, shutting down, moving across hosts. Hard-coding their locations isn’t feasible.
Service Discovery is the solution. It allows services to find each other dynamically, asking “Where is X now?” and getting a current answer. This separates the service identity (fixed) from the service location (fluid).
Two discovery models – client vs server side. In client-side discovery, the calling service does the work of looking up the target’s location (e.g., using a library to query a registry). In server-side discovery, the caller just goes to a fixed entry point (like a load balancer) and that component looks up and forwards to the target. Both achieve the same end result, and many systems use a mix of both patterns.
Service Registry as the source of truth. A registry is like a constantly updated phone book of all service instances. Services register themselves on startup and deregister on shutdown (or are removed if they crash). Examples include Consul, Eureka, etcd, Zookeeper, or even Kubernetes’s built-in etcd-based registry. The registry stores where each service lives at the moment.
Health checks keep it accurate. The discovery system performs regular health checks or heartbeats to ensure that only healthy, alive instances are considered. Unhealthy ones are dropped until they recover. This way, “discovering a service” usually means discovering an available service.
Cloud-native platforms automate discovery. Kubernetes, for instance, gives every service a stable DNS name and does the discovery and load balancing under the hood. Developers don’t have to manually query registries – the platform’s networking does it. It feels like magic, but it’s really just the same service discovery principles applied automatically.
Things can still go wrong! Be mindful of issues like stale registry data, registry downtime, network partitions, etc., when designing your system. Use robust, highly available registry setups and perhaps client-side caching or fallbacks. And avoid circular dependencies where services depend on each other’s presence in awkward ways.
Service discovery turns “finding” into a first-class capability of your system. It answers the question “Who serves this request?” in real-time, every time. By doing so, it enables trust among moving parts – every service can move about freely, confident that others will still be able to find it. In the end, service discovery is what allows distributed systems to be dynamic, scalable, and fault-tolerant without losing connectivity. It’s not magic, but it sure makes the impossible possible.