
CQRS — when Reads and Writes take different paths
System design fundamentals

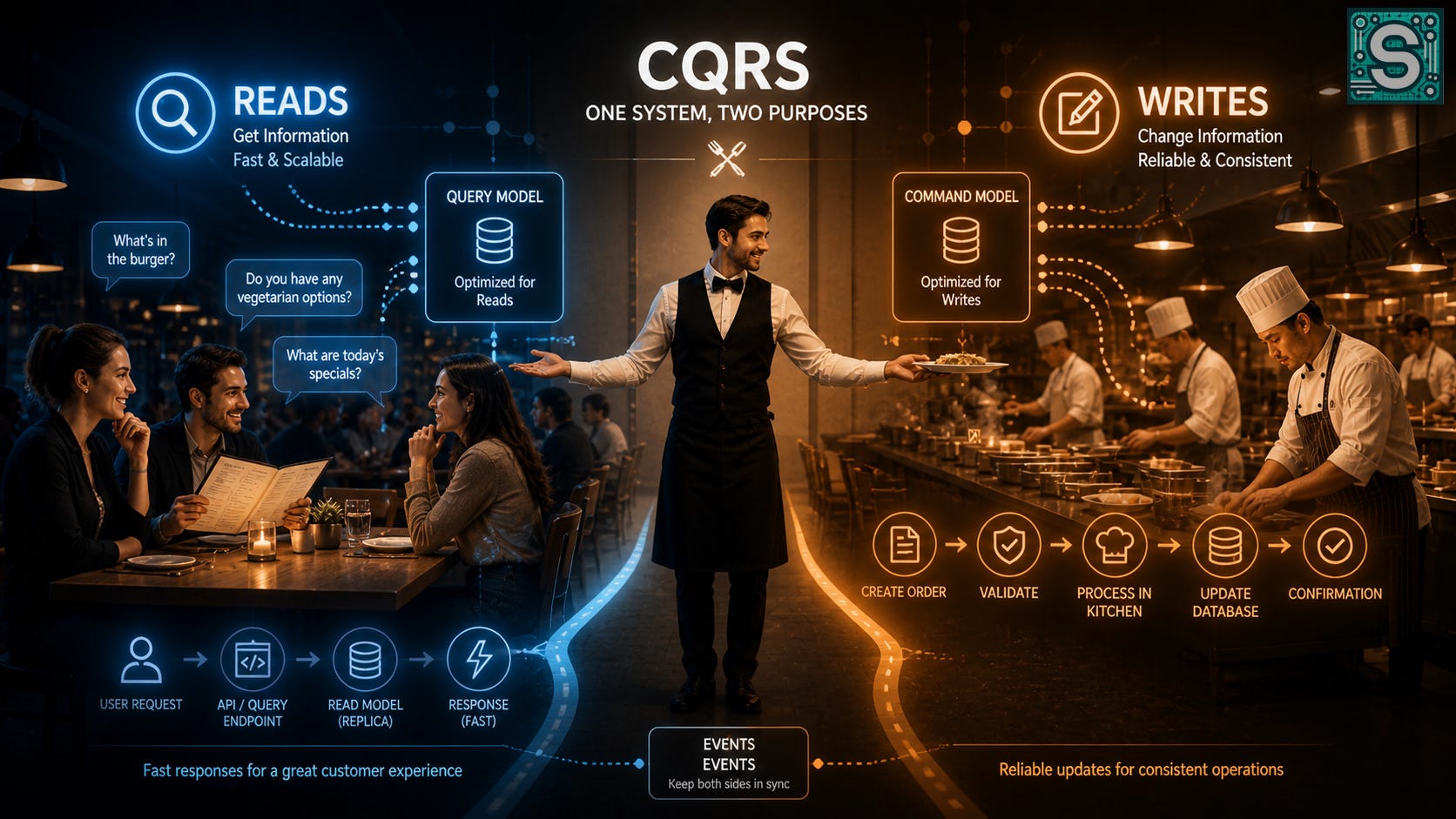
Imagine a restaurant.
Customers ask the waiter what’s on the menu - they want an answer right away. But when they place an order, the process changes: the waiter writes it down, passes it to the kitchen, and only later brings back the meal.
In that restaurant, reading and writing already take different paths. That’s exactly what CQRS is about.
In this little story, getting information (what’s on the menu) is a read operation that demands immediacy. Placing an order is a write operation that takes a longer path through preparation. We intuitively separate the two. In software systems, however, we often try to do both in the same place - and that can cause friction. Mixing reading and writing in one process is like two people trying to write on the same sheet of paper simultaneously; it’s bound to slow things down.
Reading and deciding are different modes of action, and if we force them through a single channel, they get in each other’s way. This introduction sets the scene for a pattern that formally separates reads and writes so each can do what it does best, without stepping on each other’s toes.
🧩 Why the classic approach breaks down
Before introducing CQRS, let’s understand the pain that it addresses. In a traditional architecture, we often use one database (and one data model) to handle both reads and writes (the classic CRUD approach). This is simple and works fine at small scale, but as traffic grows, problems emerge.
Contention between reads and writes. If many users are reading and writing at the same time, they start to compete. Every write operation can lock part of the data that others want to read, causing queries to wait. For example, in a SQL database, inserting or updating a row can lock a table or index that a read query needs, leading to contention.1
Performance degradation. As the single database does more work, reads and writes both slow down. Complex queries have to sift through data that is also being updated in real-time, adding load on the system. The more we try to optimize one side (say, by adding indexes for faster reads), the more we might hurt the other side (since those same indexes slow down writes).
Scaling limits. Eventually, scaling a one-database-fits-all system becomes difficult. You can scale the database vertically (more CPU, RAM), but at some point the mix of workloads (read-heavy vs write-heavy) prevents optimal scaling. The data model becomes a bottleneck because it’s trying to serve two masters with different needs.
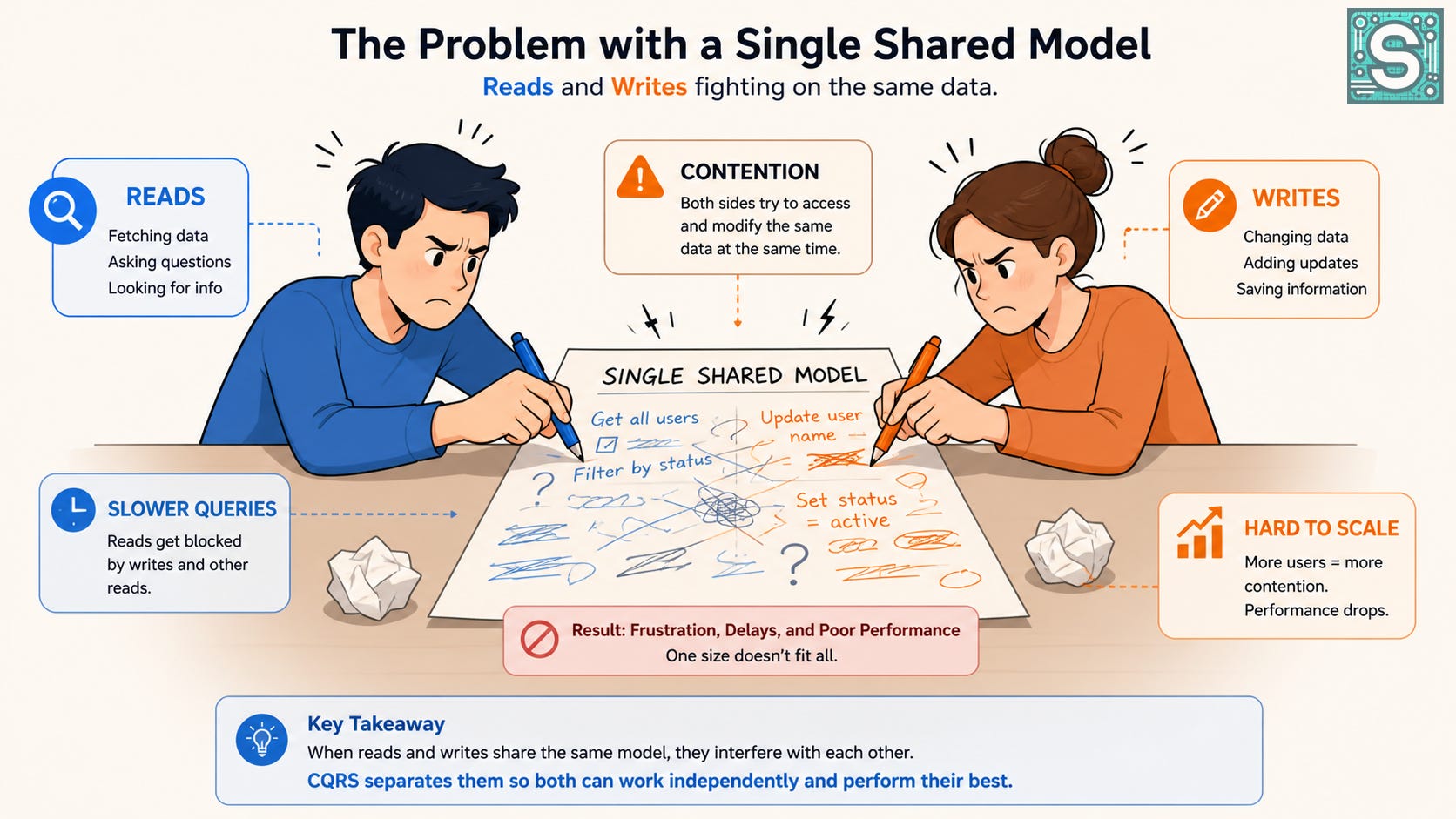
It’s like trying to take notes on the same sheet of paper where someone else is simultaneously writing – a messy and inefficient process. When reads and writes interfere with each other, everyone waits. The result is slower queries, frustrated users, and headaches when the system grows beyond a certain load.
Reading and writing in the same place is like trying to take notes on the same sheet someone else is writing on. Sooner or later, neither of you can write clearly.
In short, the classic all-in-one approach breaks down under heavy load or complex requirements. We need a better way to handle the difference in nature between querying data and changing data. Enter CQRS.
⚠️ A practical career resource worth following

Career Compass by Skill to Income by Yusup helps people turn skills into income with clear, actionable advice on job searching, freelancing, content creation, and career growth. What I like is the focus on reality: positioning, visibility, proof, and the changing rules of the job market.
⚙️ What CQRS really means
CQRS stands for Command Query Responsibility Segregation - which sounds academic, but the idea is quite straightforward. Let’s break it down in simple terms:
A Command is an operation that changes state. It’s an instruction to do something (e.g., “Place Order”, “Update Account”, “Book a Hotel Room”). In other words, commands are writes – they express an intent to modify data or trigger an action.
A Query is an operation that reads state. It’s a request for information (e.g., “Get Order Details”, “List My Orders”, “What rooms are available?”). Queries do not change data; they only retrieve it.
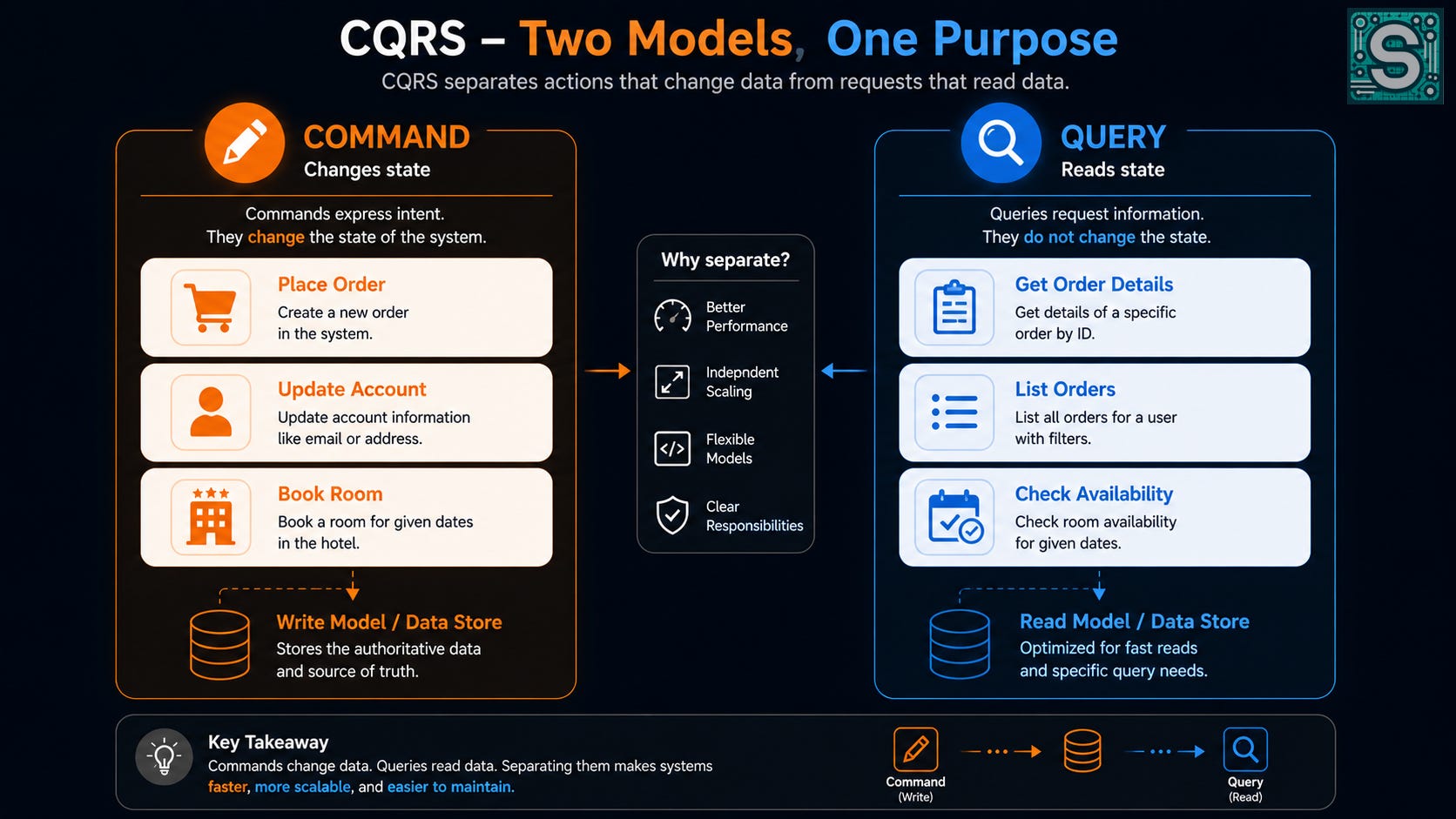
The principle of CQRS is to separate the two responsibilities so that reads and writes go through different paths or models. In traditional systems, we often use the same data structures, objects, or databases for both updating and reading data. CQRS says: don’t do that – use one model (or set of objects) for commands (writes) and a different model for queries (reads).23
Why separate? Because the way you update information can be very different from the way you read it. A single unified model often becomes a compromise that doesn’t serve either side perfectly. As Martin Fowler puts it, having the same conceptual model for commands and queries often “leads to a more complex model that does neither well”. By splitting them, each side can be simpler and more focused on its job.
🧠 What if architectural patterns are really just recurring solutions to recurring problems?
CQRS, caching, queues, sharding - each pattern exists because the same problems appear repeatedly at scale.
👉 Get more practical breakdowns - straight to your inbox.
Think of a company with two departments: one department handles orders (taking actions), and another handles information (answering questions). They are part of the same company (the overall system), but they operate differently and have different processes. If you route a request to purchase through the information desk, it’ll be inefficient; conversely, if you ask the ordering department a purely informational question, they might have to dig through records unnecessarily. It makes sense to direct queries to the information department and commands to the orders department.
Imagine an organization splitting work between two teams – one excels at taking action (processing changes), the other excels at providing answers (serving read requests). Same organization, different pace and process. CQRS formalizes this separation in software architecture.
In summary, CQRS means using different models (and possibly different paths or components) for writes and reads. A “Command” goes to the write side of the system to change something, while a “Query” goes to the read side to fetch something. By segregating these, each side can be optimized and evolved independently.
🧮 How it works in practice
It’s one thing to describe CQRS in theory, but how does it actually look in a system? Let’s sketch a high-level picture of a CQRS architecture and then break down the steps:
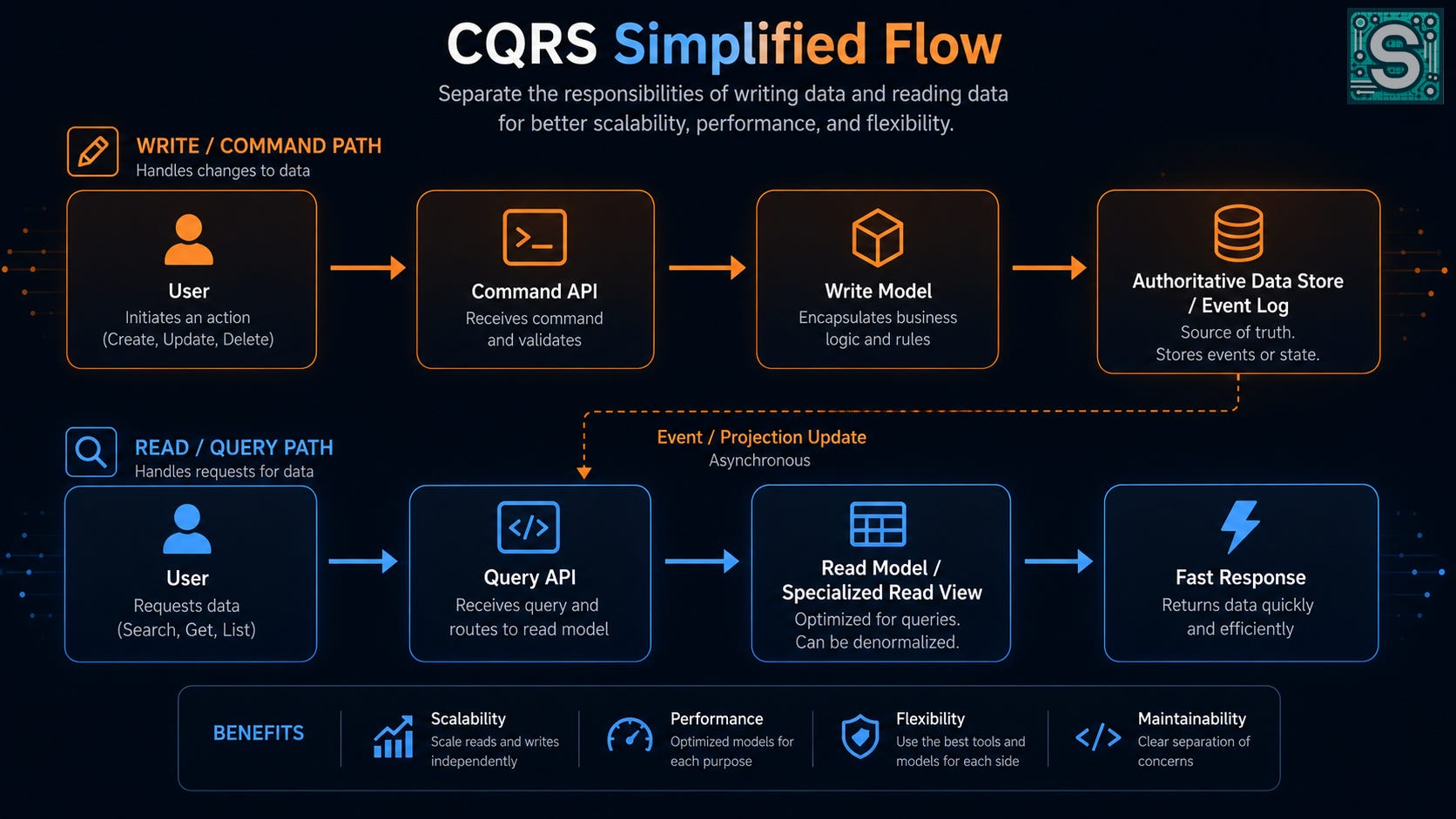
In a typical CQRS setup, you might have something like this:
The user sends a command. For example, a customer clicks “Place Order” in an e-commerce app. This request is sent to a Command API (or service) dedicated to handling write operations.
The write model processes the command. The command is validated and business logic is applied. The system updates the write model – this could mean changing the state of domain objects or, commonly, storing an event that represents the change (more on events in a moment). The write side is concerned with ensuring the command is executed correctly (all rules checked, data consistency maintained for the operation). It does not immediately update what the user sees; instead, it records the change in the system’s source of truth (for instance, saving an “OrderPlaced” event to an Event Store or updating a orders table).4
The read model updates asynchronously. Here’s where CQRS differs from a traditional approach: the system doesn’t try to serve the query from the write database in real-time. Instead, the change from step 2 (the new order event or updated data) is communicated to a read model - often via an asynchronous message or event. The read model is a separate representation of the data, typically stored in a format optimized for fast queries (it could be a denormalized SQL view, a NoSQL database, an in-memory cache, etc. - whatever makes reads speedy for the use case). A background process (sometimes called a denormalizer or projector) takes the event (“OrderPlaced”) and updates the read model accordingly, e.g. inserting a record into an “orders view” with the order’s details.5 This update happens asynchronously, meaning the user doesn’t wait on it in order to complete the command.
The user makes a query. Now suppose the user (or another system component) asks, “What’s the status of my order?” – this is a query. The query is handled by a Query API (or service) dedicated to reads. This query doesn’t hit the write database; instead, it goes straight to the read model (the optimized data store from step 3). Because that read model is built for queries, it can return the result quickly (for instance, it might return the order status and details from a precomputed view).
A key consequence of this design is that the user’s reads don’t slow down the writes, and vice versa.
The read model is a projection of the write model’s data, shaped specifically for answering questions efficiently.
Meanwhile, the write model (the source of truth) only worries about processing commands and ensuring the integrity of transactions, not about serving queries under load.
It’s worth noting that the read model might not reflect the very latest write instantly. In step 3, we updated the read model asynchronously. This means there’s a short window where the user’s query might be answered from slightly older data if the new event hasn’t been applied yet. This is known as eventual consistency: the read side will catch up and become consistent with the write side, typically very quickly, but not necessarily at the exact same millisecond as the write.6 We’ll discuss this trade-off more in the challenges section.
To solidify the concept, here’s a very simple pseudo-code illustration of a CQRS flow in action using Python-like pseudocode:
# Simple CQRS-like pseudo-code for an order system
# The write side (command handling):
event_store = [] # This will record events (our “truth” of what happened)
def place_order(order_id, customer, item):
# 1. Validate and apply business rules
if item not in inventory:
raise ValueError(”Item not in stock”)
# ... (other validations)
# 2. Record the state change as an event in the write model (event store)
event = {”type”: “OrderPlaced”, “order_id”: order_id, “customer”: customer, “item”: item}
event_store.append(event)
# Simulate publishing an event to update the read model
update_read_model(event)
return “Order placed successfully.”# Simple CQRS-like pseudo-code for an order system
# The read side (query handling):
read_database = {} # A simple read model (e.g., a denormalized view of orders)
def update_read_model(event):
# This function is called when a new event is recorded, to update the read model.
if event[”type”] == “OrderPlaced”:
order_id = event[”order_id”]
# Initialize the order record in read DB with relevant info
read_database[order_id] = {
“customer”: event[”customer”],
“item”: event[”item”],
“status”: “Placed”
}
# (In a real system, more event types and handling would be here.)
def get_order_status(order_id):
# 3. Query the read model for the current state (fast read)
order = read_database.get(order_id)
if order:
return f”Status: {order[’status’]}”
else:
return “Order not found.”# Example usage:
print(place_order(101, “Alice”, “Book”)) # User places an order (write operation)
print(get_order_status(101)) # User queries the order status (read operation)In the above pseudo-code, place_order acts as the command handler (validating and recording the command), while get_order_status is the query handler retrieving data from a read-optimized store. The update_read_model function simulates the asynchronous projection of events into the read model (here we call it directly for simplicity). In a real system, this might be done by a separate process listening to events (e.g., via a message queue or event bus).
This separation means that the read function (get_order_status) doesn’t need to traverse the whole order processing logic or the normalized write schema; it just looks up a pre-populated result (fast!). The write function (place_order) doesn’t have to worry about how to present data for queries; it just focuses on correctly handling the transaction and recording the outcome.
🧠 Why CQRS matters — the benefits
Why go through the trouble of separating reads and writes? Here are some practical advantages that CQRS can bring.
Performance and scalability. Because read operations and write operations are isolated, each can be scaled independently. If your application has 100x more reads than writes (common in many systems), you can scale out the read side (more read replicas, caching, or a high-performance query database) without over-complicating the write side. Likewise, heavy write workloads can be tuned and scaled without affecting read query performance. The decoupling leads to higher overall performance since neither side is waiting on the other. Microsoft’s Azure Architecture guide notes that as applications grow, read and write paths have different performance needs – CQRS addresses this asymmetry and allows each to be optimized without the other becoming a bottleneck.
Optimized data models for each side. In CQRS, the write model and the read model can be designed differently. The write side focuses on data consistency and business rules, often using a normalized data model or rich domain model to ensure integrity. The read side can use a totally different schema – even a different database technology – tailored for queries. For example, you might use a relational database for writes (to handle transactions and relationships) but a fast document or key-value store for the read model to retrieve data quickly. You could even have multiple read models optimized for different query scenarios (one for reporting analytics, one for real-time UI views, etc.), all derived from the same source of truth. This is a huge flexibility gain – adding a new way to present data doesn’t require rewriting the core business logic, you just build a new read model from the events or data.
Clarity and maintainability. By separating responsibilities, your code and design can become cleaner. Each part of the system has a single job – handling commands or serving queries. This separation of concerns means the intent of code is clearer: you know a command handler is all about making a decision or change, while a query handler is just about assembling data to return. It aligns with the idea that “commands decide, queries inform”. This can make the system easier to reason about and maintain. In fact, having distinct command and query models often results in simpler models that don’t have to cover every scenario in one place. The Azure guidance explicitly states that this separation “improves clarity” in design.
Independent Evolution. The read side and write side can evolve on separate timelines. If you need to change how data is displayed or aggregated for reads, you can often do so without touching the write side (as long as the necessary raw data is being captured). For instance, you might denormalize some data in the read model to speed up a new kind of query, without any changes to the transactional database. Similarly, if business rules change for writes, you update the write model and perhaps emit new events, but the read subscribers can adapt separately. This modularity adds a level of agility in development.
Naturally fits event-driven systems. CQRS pairs naturally with event-driven architecture and event sourcing (we’ll explore this more in the next section). The benefit here is that if you’re already capturing events (each state change), constructing multiple read models from those events is straightforward. You get the performance benefits described above while also retaining a full history of changes (events). As one source puts it, CQRS can give you “the benefits of event-level storage, but also much higher performance” by decoupling reads from writes. In other words, you don’t pay the price of recomputing history on each read because you compute and store the relevant views at write-time.
CQRS can make your system more scalable, more responsive, and often simpler to understand by giving reads and writes the freedom to follow their own optimal path.
In real-world complex systems (like large e-commerce platforms, high-traffic web apps, financial systems), these benefits can be the difference between an application that bogs down and one that flies. One author describes that CQRS’s separation can improve performance and maintainability, especially in complex systems.7
However, CQRS is not a silver bullet. Those improvements come at the cost of additional complexity. Let’s talk about what you have to be mindful of when using CQRS.
⚖️ The challenges and trade-offs
Every architectural pattern has its price, and CQRS is no exception. It’s important to approach it with eyes open to the trade-offs involved!
Increased complexity. You are essentially maintaining two systems where before there was one. That means more code (e.g., separate classes for commands and queries, separate database schemas or tables, messaging infrastructure to link writes to reads). Martin Fowler cautions that while CQRS can be valuable in some situations, “for most systems CQRS adds risky complexity”. If your team is small or not experienced with distributed systems, the complexity of keeping two models in sync can lead to bugs and confusion. There is also the mental overhead - developers have to think in terms of eventual consistency, asynchronous updates, and multiple data representations, which is a step up in complexity from straightforward CRUD.
Eventual consistency (latency of reads). In a CQRS system (especially one that uses separate databases for read and write), the data a user reads may not reflect the very latest write if it just happened. There’s an inherent delay in propagating changes from the write side to the read side. This is known as eventual consistency – the system guarantees that if no new updates occur, eventually all reads will catch up to the last write, but there is a time window where a query might get slightly stale data. For example, if a user just updated their profile picture, a subsequent query might still show the old picture for a short time until the read model is updated. Designing the system and user experience to handle this (e.g., showing a “your change is processing” message, or updating the UI optimistically) is important. It’s a trade-off: you gain throughput and scalability, but lose immediate consistency across reads and writes.
Debugging and troubleshooting. With two separate paths and eventual consistency, it can be harder to trace the flow of data. When something goes wrong (say a read model isn’t updating correctly), developers need to chase events through asynchronous handlers and possibly across different services or processes. It’s not as straightforward as looking at a single database state. Tools and practices for monitoring, logging, and tracing become essential to understand what happened. For instance, if a query returns an unexpected result, one must determine if the write didn’t occur, the event didn’t get published, or the read model logic had a bug. This distributed flow can make testing and debugging more challenging than in a simple CRUD app. (On the flip side, having an event log can aid in debugging by providing an audit trail, but analyzing it requires effort.)
Data duplication and storage costs. Often the read model contains data duplicated from the write model (perhaps in a different shape, such as denormalized form). You might be storing the same information twice – once in the write DB and once (or multiple times) in various read models. This can increase storage needs and the complexity of keeping the data in sync. There’s also the possibility of code duplication, where some logic might be repeated on both sides (though ideally commands and queries do different things, sometimes validation or data shaping logic can appear in both). Chris Richardson notes in his discussion of CQRS that one drawback can be potential code duplication and replication lag due to maintaining multiple views.
Operational overhead. With CQRS, you might need additional infrastructure. For example, to feed changes from write model to read model, many systems use a message broker or event bus (like RabbitMQ, Kafka, etc.). Operating and monitoring these components adds to the DevOps burden. There is also the need to handle failure cases – e.g., what if the read model update fails? You need a strategy (replay the event, retry mechanism, etc.) to ensure eventual consistency. All of this means CQRS can be more expensive to build and run.
In short, CQRS solves certain problems at the cost of making your overall architecture more sophisticated. As one engineering blog puts it, “CQRS is a powerful pattern ... but it also adds extra complexity to your system”. It’s like orchestrating an ensemble instead of a solo performance – when it’s in sync it’s great, but there are more parts that could fall out of tune. The key is to use this pattern when its benefits outweigh the costs, and to manage the complexity with good tooling and practices.
A good rule of thumb is to start with the simplest thing that could work (often CRUD) and only introduce CQRS if you start hitting the limitations of the simple approach (e.g., read performance issues, overly complex domain model trying to handle everything, etc.). Next, we’ll look at a scenario where CQRS particularly shines: when combined with event sourcing in an event-driven system.
⚖️ What if every architecture decision is really a trade-off?
Scalability, simplicity, consistency, flexibility - improving one thing often means sacrificing another. There’s rarely a “best” solution - only the best fit for a context.
💬 What trade-off do you think engineers underestimate the most?
🔁 CQRS + Event Sourcing - a natural match
CQRS often goes hand-in-hand with Event Sourcing, and for good reason. Let’s first clarify event sourcing in a nutshell:
Event Sourcing is a pattern where instead of storing just the current state in your database, you store a log of every change (event) that happens to your data. The system’s state at any time can be derived by replaying or aggregating these events. For example, instead of storing the final balance of a bank account, you store each deposit and withdrawal event; the current balance is the sum of all those events. This gives you a complete audit trail of all changes (every “story” that happened to the data, not just the latest chapter).
The challenge with event sourcing is that reading data directly from an event log can be slow. If you want to know the current state, you might have to crunch through a long list of events. As the number of events grows, reconstructing state on-the-fly becomes impractical. For instance, imagine having to read through 10 years of transaction events just to show a user their current account balance – that’s not efficient.
CQRS is the solution to this problem of reading from an event-sourced system. Instead of computing the state at query time, CQRS suggests computing it at write time. In other words, when an event happens, immediately update a read model (a precomputed view) for that data. This way, each event’s impact on the query-able state is processed once (when the event occurs), and subsequent reads can just fetch the already-calculated result. As the Confluent developers put it, CQRS “performs computations when the data is written, not when it’s read... each computation is performed only once, no matter how many times the data is read in the future”.
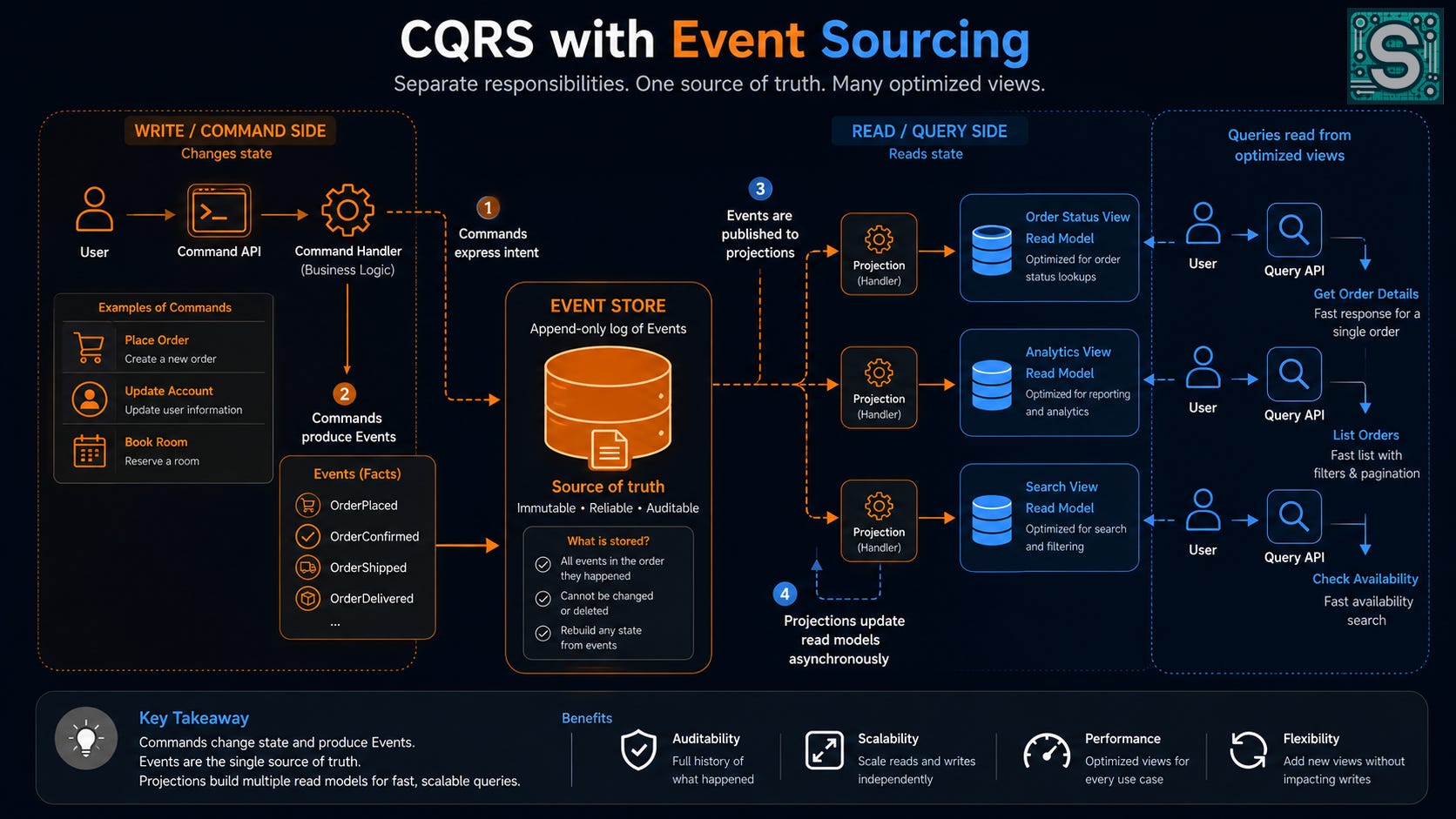
Here’s how CQRS and Event Sourcing typically work together:
The write side of the system is event-sourced. That means every command that changes state produces one or more events that are saved to an Event Store (an append-only log of events). This event store is the “truth” of what happened.
The read side of the system subscribes to those events. For each event, the read side updates its own database or cache. For example, if an
OrderPlacedevent is emitted, the read model (say, an “Orders View” stored in a fast lookup table) will create a new record for that order or update relevant counts.Now, when a query comes in (like “Get order status” or “Show recent orders”), the system simply reads from the read model’s database, which already has the answer in a convenient form (no complex joins or heavy computation needed at query time).
This pairing gives you the best of both worlds:
You have a complete history of all changes (thanks to the event store). This is great for auditing, debugging, or reconstructing state if needed. You can always re-build the read model from scratch by replaying events, which gives a lot of power and flexibility.
You also have fast queries (thanks to the precomputed read models). Users get their answers quickly because we did the work upfront, at the time of the writes. The read and write workloads are separated, so each can be optimized.
It’s no surprise that CQRS is “by far the most common way that event sourcing is implemented in real-world applications”. The two patterns complement each other: event sourcing ensures every state change is captured as an event, and CQRS ensures those events are turned into queryable views efficiently.
Another benefit of this combination is the ability to create multiple different projections of the same data. Since you have the log of events as the source of truth, you can build different read models for different purposes. For example, you could have one read model for real-time user-facing queries, another read model feeding an analytics dashboard, and maybe another serving a search index – all built from the same event stream. If you need a new type of view, you can create a new projector that processes the past events (since they’re all stored) and generates the new view. This gives a lot of flexibility to adapt the system to new requirements without disturbing the transactional core. Confluent’s guide notes that it’s common to create multiple views from the same event log for different use cases.
CQRS says “separate reads from writes”. Event Sourcing says “don’t throw away any of the changes – record every event”. Together, they make your system both scalable (because of the separation) and truthful (because of the complete log of events). Writes tell the full story; reads present whatever chapter of that story you need, in the form you need it.
Of course, using both patterns means you are committing to an even more sophisticated architecture – you’ll likely need robust messaging to deliver events, careful design to handle eventual consistency, and so on. But for domains where audit trails and high performance are critical (finance, ordering systems, collaborative applications), CQRS + Event Sourcing can be a game-changer.
🧩 When (and when not) to use CQRS
With all the pros and cons laid out, a natural question is: Should I apply CQRS to my project? The answer, as with most architecture decisions, is “it depends”. CQRS is not a one-size-fits-all solution – in fact, in many cases it might be overkill. Here are some guidelines:
✅ Use CQRS when
High read/write imbalance. Your system has a very high volume of reads compared to writes (or vice versa) and you need to scale them differently. For instance, an application where thousands of users mostly query data (reads) but only admins occasionally update it (writes) could benefit from separate scaling of read vs. write models.
Complex domain logic. If the write side of your system (the business logic) is complex and you want to keep that code isolated from the simpler task of data retrieval, CQRS can help. A complex domain might involve lots of validations, calculations, and rules on the command side, which you can model with rich domain objects, while keeping queries lean and straightforward.
Performance and scalability requirements. You’ve identified performance bottlenecks due to the read/write contention or you anticipate scaling challenges. CQRS can be a way to break those bottlenecks by tuning each side separately. Large, data-intensive applications (e.g., an e-commerce site with heavy product catalog reads and fewer writes for orders, or a social media platform where reads of profiles and posts far exceed writes) are potential candidates.
Multiple view or integration requirements. If you foresee the need for multiple representations of the data (perhaps different services or UI views that each need the data shaped differently), CQRS can provide a clean path to maintain several read models. Also, if you are integrating with other systems via events, CQRS naturally feeds into that by treating writes as events that other components can subscribe to.
Event sourcing or audit log needed. As discussed, if having an audit log of all changes is valuable (compliance, debugging, analytic replays), and you want to utilize event sourcing, then CQRS will likely be a beneficial companion pattern. In fact, some experts say CQRS is almost necessary to effectively query an event-sourced system.
Independent team development. In some large organizations, you might even separate teams for developing the read side and write side (since they require different expertise – e.g., database optimization for reads vs business logic for writes). CQRS can enforce a boundary that teams can work on without too much stepping on each other.
❌ Avoid CQRS when:
Simple or small applications. If your application is small, straightforward, or has low throughput, CQRS is probably unnecessary. For example, a personal notes app or a simple blog website with low traffic doesn’t need this level of architectural separation – a single well-designed database and model will do just fine, and will be easier to build. As one source puts it, if you don’t have significant performance or scaling issues, CQRS might be “overkill”. You won’t gain much, and you’ll pay a complexity tax.
Tightly coupled operations. If every action in your system immediately needs a result that depends on up-to-the-moment data (strong consistency requirements), the asynchronous nature of CQRS can be troublesome. For instance, if you have a workflow where a write is immediately followed by a read of the same data in the same user flow, and you cannot tolerate stale data, you might need to stick to a linear, strongly-consistent approach (or implement CQRS with careful workarounds, which complicates things).
Lack of resources or expertise. Implementing CQRS (especially with event sourcing) successfully requires understanding of distributed systems, messaging, eventual consistency, etc. If your team is very small or new to these concepts, and the project timeline is tight, adopting CQRS could introduce risk. As one expert humorously summarized: “When should you avoid CQRS? The answer is most of the time”.8 This doesn’t mean CQRS is never useful – it means default to simpler architecture unless you have a clear reason to use CQRS.
Already sufficient solutions. Sometimes, you can solve performance issues with simpler tweaks like read replicas of your database, or caching, without a full CQRS split. Read replicas (database copies for serving queries) can alleviate read load on the primary database and might be much easier to implement. If that works for your scenario, it’s a lot less effort than a whole CQRS rewrite. CQRS is a more extreme measure and should be justified by requirements that truly need it.
CQRS makes sense in an e-commerce platform that gets, say, 100 read requests (product views, searches, recommendations) for every 1 write request (placing an order, updating a cart). Such a system benefits from scaling out many read databases or caching layers, and isolating the complex ordering logic on the write side.
On the other hand, CQRS is overkill for a personal notes app that one user interacts with; the volume is low and a single database can handle both reads and writes easily.
It’s also worth mentioning that you don’t have to apply CQRS to the entire system. In many cases, hybrid approaches are used – only the hot spots or complex subsystems use CQRS, while other parts of the application remain simple. For example, you might use CQRS+Event Sourcing for the core domain (like orders and payments), but use a straightforward CRUD approach for something like user profile management if it’s simple and low-volume. One engineering article advises not to use CQRS for the whole system, only for the parts where the complexity and scale demand it.
Martin Fowler also suggests that CQRS should be used only where it really adds value, because it’s a “significant mental leap” and can cause serious difficulties if done inappropriately. In summary, evaluate CQRS like any tool: great for some jobs, a liability for others.
Before we conclude, one more thing: What about implementation in practice? CQRS is a pattern, not tied to a specific technology. It can be implemented in any programming language or platform. There are frameworks that help with CQRS:
In the .NET/Java world, for instance, libraries like MediatR (for .NET), Axon Framework (Java), or Apache Camel (for routing events) can assist in setting up pipelines for commands and queries.
In Python, there are libraries like Diator which provide abstractions for Command Handlers, Query Handlers, and integrate with message brokers for event handling.9 These frameworks handle some of the boilerplate, allowing you to focus on your business logic. For example, Diator allows you to define command classes and handlers, query classes and handlers, and wires up the messaging so that when a command is executed, events are published to update query models, etc. Using such a library can accelerate development if you choose to go the CQRS route.
Ultimately, whether or not to use CQRS boils down to the specific needs of your project.
Start by asking: Do I really need to separate reads and writes to meet my goals?
If yes, CQRS is a powerful pattern to consider. If not, keeping things simple is usually the wise choice.
💬 CQRS is a way of thinking
As we wrap up, it’s worth reflecting that CQRS isn’t just a technical pattern – it’s almost a philosophy in system design. It forces you to think about operations in two distinct modes: the act of making a decision or change, and the act of retrieving information. This separation can influence how you design APIs, how you model your data, and how you think about consistency and user experience.
Many problems in software (and even in everyday life) become simpler when you acknowledge that not everything that asks a question needs to trigger an immediate change, and not every action should require an immediate answer. CQRS embodies this idea. It says: let the writes (decisions) happen in their own pipeline, and let the reads (questions) happen in their own pipeline. Each at its own speed, with its own optimizations.
Think back to the restaurant analogy in the introduction. The waiter doesn’t try to cook your food on the spot when you ask for it, nor does the chef come out to recite the menu to you. They have a system that matches the nature of the task: quick answers versus slower fulfillment. CQRS, in a sense, is applying that common-sense separation to software design.
In a world where users demand both real-time information and complex processing of their requests, CQRS offers a way to deliver both by not forcing one mode to always wait for the other. It’s about acknowledging the different speeds and purposes of questions versus commands.
To close on a slightly philosophical note: In life, when we make decisions (commands), we often need time to see their effects play out; when we seek information (queries), we value quick and clear responses. CQRS mirrors this in software. It’s a pattern that reminds us that focus and flow matter – do one thing at a time, do it well, and don’t let unrelated tasks impede each other.
Not every system needs CQRS, just like not every situation demands a formal separation of duties. But understanding this pattern gives you one more lens through which to view system design: sometimes, splitting things by their nature (write vs read) can turn a sluggish, tangled system into one that’s more elegant and efficient.
🧩 What if system design is really about managing complexity?
Most architectural patterns exist to make complexity easier to control - not disappear. Good architecture doesn’t remove trade-offs - it makes them visible. As systems grow, complexity becomes the real scaling problem.
🔁 Share this with someone learning system design.
✍️ Recap
CQRS (Command Query Responsibility Segregation) is an architectural pattern where you separate write operations (commands) from read operations (queries). Instead of one model or database doing double duty, you have distinct pathways for modifications and for queries.
It’s like a restaurant with a separate process for taking orders and answering questions - each task follows a different path optimized for its purpose.
Why use it? In traditional one-size-fits-all systems, reads and writes compete for resources, causing contention and slowdowns. CQRS alleviates that by letting reads and writes scale and evolve independently. This often leads to better performance, scalability, and clarity in complex or high-traffic applications.
How it works. A command goes through the write model (applying business logic and updating state, often by emitting events), and the read model is updated (asynchronously) to reflect those changes in a query-friendly form. A query then hits the read model (which is fast and optimized for retrieval) without disturbing the write process.
Benefits. You can tailor the read database for efficient queries (even have multiple read views for different needs), while keeping the write side focused on business rules and consistency. Systems can handle larger load (since, for example, read-heavy traffic can be served by scaled-out read replicas). It also naturally fits with event-driven designs, giving you an audit log of all changes.
Trade-offs. CQRS adds complexity. You introduce eventual consistency, meaning recent writes might not show up immediately in reads. There’s additional overhead in maintaining two sets of models and keeping them in sync. Debugging and testing require careful thought due to the asynchronous, distributed nature of data flow.
When to apply. Use CQRS in domains that are complex, collaborative, or high-scale - where the extra complexity is justified by performance gains or design clarity. Good examples are systems with heavy read loads (social feeds, shopping catalogs, analytics dashboards) or where business transactions are complex. Avoid it for simple, low-scale applications or parts of an app where straightforward CRUD is more than enough.
CQRS + Event Sourcing. They complement each other. Event sourcing gives you the history of changes, and CQRS ensures you don’t pay a performance penalty for that history by updating read models on the fly. Together, they yield systems that are both scalable and maintain a full history of state changes.
Philosophy. More than just a pattern, CQRS encourages thinking about the intent of an operation. Commands decide (and change), queries ask (and inform). By honoring the difference, we allow each to “move at its own rhythm”, leading to a design optimized for both focus (each part does one job well) and flow (the system can handle more work overall).
With CQRS in your toolbox, you have the option to let reads and writes take different paths when the scenario calls for it – just like our waiter and kitchen, each doing what they do best.
I like how this forces clarity around intent!
The read and write problem is really just two different jobs fighting over the same desk.